
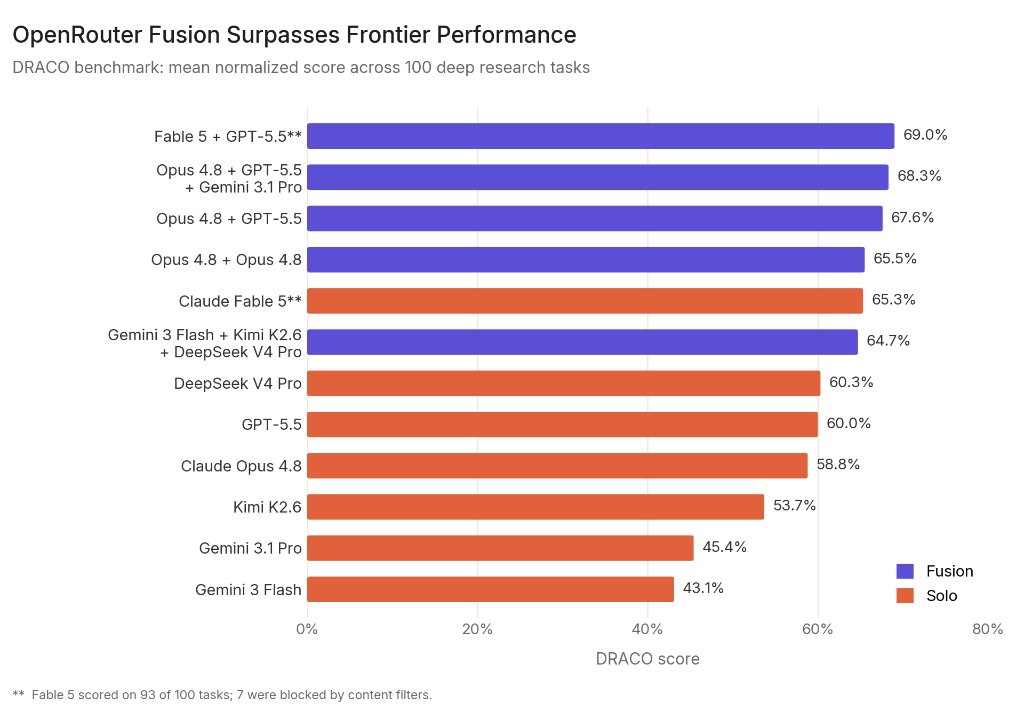
OpenRouter says model panels can outperform solo models on deep research tasks, with its Fusion setup scoring 69.0% on DRACO by combining Fable 5 and GPT-5.5 outputs.
OpenRouter said June 12 that its new Fusion tool scored above solo frontier models on the DRACO deep research benchmark by sending one prompt to several models, then using a judge model to synthesize the answers.

The strongest reported setup paired Claude Fable 5 and GPT-5.5, with Claude Opus 4.8 serving as synthesizer. OpenRouter reported a 69.0% DRACO score for that panel. Fable 5 alone scored 65.3%, GPT-5.5 scored 60.0%, and Opus 4.8 scored 58.8%.
OpenRouter also tested a lower-cost panel with Gemini 3 Flash, Kimi K2.6, and DeepSeek V4 Pro. That group scored 64.7%, ahead of GPT-5.5 and Opus 4.8, and within 1 percentage point of Fable 5. OpenRouter said that panel cost about half as much as the Fable 5 run.
Fusion works as a server-side orchestration layer. A user sends one prompt to OpenRouter. OpenRouter sends that prompt to a selected panel of models, gives each model web search and web fetch access, and asks a judge model to compare the responses. The judge produces a structured analysis covering consensus, contradictions, missing coverage, unique findings, and blind spots. The final model then writes an answer grounded in that synthesis.
OpenRouter exposes Fusion through the openrouter/fusion model slug, a chatroom at openrouter.ai/fusion, a plugin configuration, and a server tool. Developers can configure participant models through the Fusion API documentation, including budget panels and frontier panels.
OpenRouter chose DRACO because Perplexity designed it for deep research tasks that require source gathering, synthesis, tool use, and concise presentation. DRACO contains 100 tasks across academic research, finance, law, medicine, technology, UX design, general knowledge, retrieval, personalized assistance, and product comparison.
Each DRACO task uses a weighted rubric across factual accuracy, breadth and depth, presentation quality, and citation quality. The rubric can also penalize harmful or false claims through negative criteria. That design matters for model panels because a longer answer can score worse if the model adds unsupported claims.
OpenRouter said it ran each response through three judge passes and reported the mean normalized score from zero to 100. The company used Gemini 3.1 Pro Preview as the judge, while the DRACO paper used Gemini 3 Pro. That choice limits direct comparison with the paper’s scores, though OpenRouter framed the post around relative differences among its own runs.
The most interesting result may involve Opus 4.8 paired with itself. OpenRouter ran Opus 4.8 twice as a two-member panel, with Opus 4.8 also acting as synthesizer. That setup scored 65.5%, up from 58.8% for solo Opus 4.8.
That result suggests Fusion gains more than model diversity. Two calls to the same model can take different research paths, select different sources, and emphasize different facts. A judge can combine those paths into a stronger answer than either run produced alone.
OpenRouter also found a benchmark contamination risk during testing. With web search enabled, some model runs found DRACO grading rubrics online. OpenRouter said it excluded the rubric host locations from web search and web fetch, then produced the published scores after those exclusions took effect.
That detail deserves attention from teams running agent benchmarks. Tool-using models can stumble into answer keys through search terms, even without an explicit prompt to cheat. OpenRouter supports excluded_domains for web search and blocked_domains for web fetch, giving evaluators a practical way to keep benchmark materials out of model context.
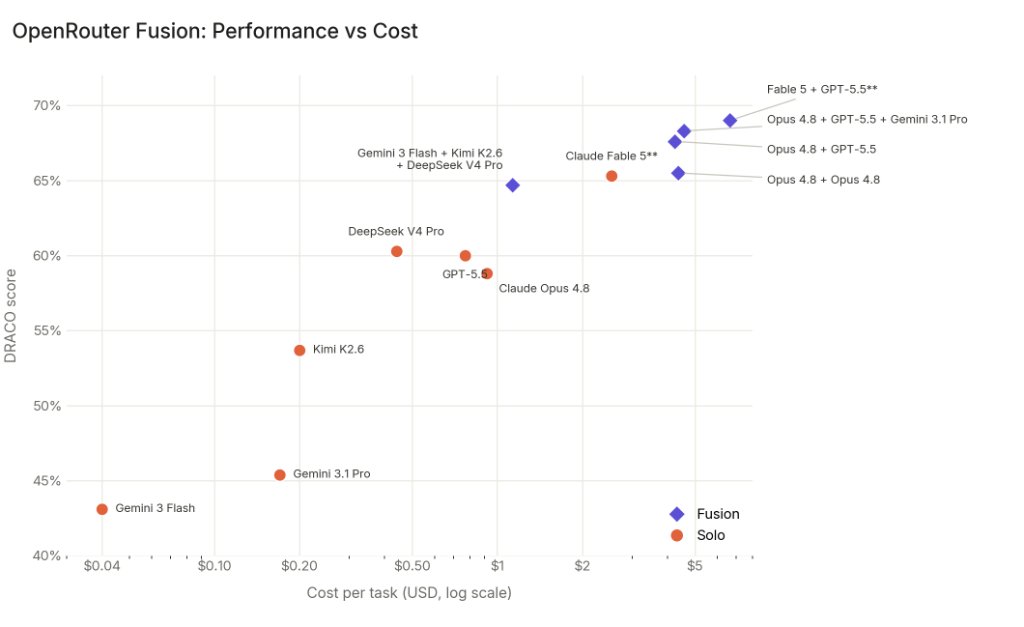
The results support a narrow claim: for DRACO-style research questions, multiple model responses plus a synthesis step can beat one strong model under the same tool budget. The post does not show that Fusion can replace specialized coding models, long-horizon agents, or all frontier model calls.
OpenRouter makes that distinction in its launch FAQ. The company says developers should treat Fusion as a tool that a base model can invoke for questions worth extra time and money, such as architecture decisions or research-heavy trade-offs. Routine coding work can still go through the base model.
Latency also changes the use case. OpenRouter said a Fusion invocation often takes two to three times longer than a standard call because the system waits for multiple model responses, processes them, and writes a fused answer. That cost makes sense for research questions. It fits poorly in low-latency chat flows unless the application can reserve Fusion for high-value prompts.
The benchmark leaves several open questions. DRACO covers text-only English tasks, and its static task set may miss production workloads. Judge choice can move absolute scores by large margins. Fable 5 completed only 93 of the 100 tasks because content filters blocked seven runs, which makes its direct comparison with models that completed all 100 tasks uneven.
Fusion also adds another layer of model behavior that teams must evaluate. A judge can improve source coverage and catch contradictions, but it can also choose the wrong answer when panel members disagree. Teams that adopt this pattern should inspect judge rationales, compare outputs against task rubrics, and track cost per accepted answer.
OpenRouter’s launch fits a wider pattern in AI systems: teams now treat model calls as components inside larger inference pipelines. Retrieval, tool use, self-consistency, reranking, and judge-based synthesis can improve results without waiting for a new base model. Fusion packages that pattern behind one API call.
For developers, the practical question is where the extra inference spend changes the user outcome. Deep research, technical due diligence, policy comparison, legal intake, and medical literature review may benefit from panel synthesis, subject to domain review and source controls. Simple summarization, autocomplete, and routine chat may see poor value from the added cost.
OpenRouter has made a credible benchmark case that synthesis can raise deep research scores. The harder test comes next: developers will need to measure Fusion against their own tasks, their own latency limits, and their own tolerance for judge-model errors.
Comments
Please log in or register to join the discussion