
Google unveils fourth-generation Gemma models with Apache 2.0 license, multimodal capabilities, and edge device support to compete with Chinese open-weights LLMs from Alibaba, Moonshot AI, and Z.AI.
Google has launched Gemma 4, its latest generation of open-weights AI models, as the tech giant seeks to counter the growing threat from Chinese competitors in the enterprise AI market.

Developed by Google's DeepMind team, the new models come with a more permissive Apache 2.0 license, addressing a key concern that had limited enterprise adoption of previous Gemma versions. The shift away from Google's restrictive licensing model means businesses can now deploy these models without fear of having their access terminated.
The Chinese competition heating up
The timing is strategic. Chinese AI companies have been releasing increasingly capable open-weights models that now rival Western offerings. Companies like Moonshot AI, Alibaba, and Z.AI have been pushing out models that compete directly with OpenAI's GPT-5 and Anthropic's Claude, forcing Google to respond with competitive alternatives that keep sensitive corporate data within domestic control.
Model lineup and capabilities
Google's fourth-generation lineup spans from massive datacenter models to tiny edge variants:
Top-tier models:
- 31B parameter dense model: Optimized for maximum output quality, runs unquantized at 16-bit on a single 80GB H100 GPU
- 26B parameter MoE model: Uses 128 experts with 3.8B active parameters for faster inference at the cost of some quality
Edge models:
- 2B effective parameters (5.1B actual with PLE optimization)
- 4B effective parameters (8B actual with PLE optimization)
Both tiers support 256K context windows for the larger models and 128K for the edge variants. The models are multimodal, accepting text, visual, and audio inputs (E2B/E4B only).
Technical innovations
The edge models use per-layer embeddings (PLE) to reduce effective compute requirements while maintaining the benefits of larger parameter counts. This allows them to run efficiently on devices like smartphones and Raspberry Pi while still offering substantial context windows.
For enterprises requiring low latency, the MoE architecture provides a compelling tradeoff: faster token generation at the expense of using only a fraction of available parameters per inference pass.
Enterprise appeal
The Apache 2.0 license change is arguably the most significant update. Previous Gemma models came with usage restrictions and termination clauses that made many enterprises wary of committing to the platform. The new licensing removes these barriers, making Gemma 4 a more attractive option for businesses concerned about vendor lock-in and data sovereignty.
Google claims "day-one support" for over a dozen inference frameworks including vLLM, SGLang, Llama.cpp, and MLX, with availability through AI Studio, AI Edge Gallery, Hugging Face, Kaggle, and Ollama.
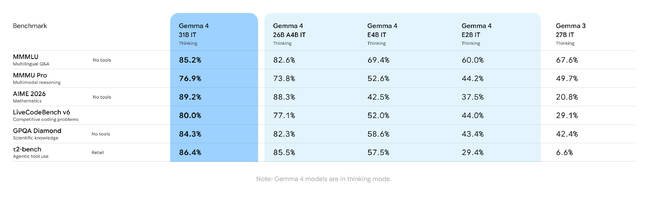
Performance claims
While vendor-supplied benchmarks should always be viewed skeptically, Google reports significant improvements over Gemma 3 across multiple AI benchmarks. The models are particularly tuned for agentic AI and coding applications, with native function calling capabilities.
The 31B model strikes a balance between capability and accessibility - powerful enough to compete with larger proprietary models while remaining practical for enterprise deployment without requiring massive GPU investments.
The launch represents Google's most aggressive push yet into the open-weights market, directly challenging Chinese AI companies that have gained ground with their increasingly sophisticated models. By offering a domestic alternative with enterprise-friendly licensing, Google aims to keep sensitive corporate data from flowing to foreign AI providers while providing the flexibility and performance that businesses demand.
Comments
Please log in or register to join the discussion