Enterprise AI platforms are outgrowing traditional, alert‑driven monitoring. Baharath Bathula outlines a six‑stage closed‑loop architecture that lets data pipelines detect, diagnose, remediate, verify and learn from failures autonomously, while keeping governance and auditability at the core.
How AI Systems Can Build Self‑Healing Data Infrastructure
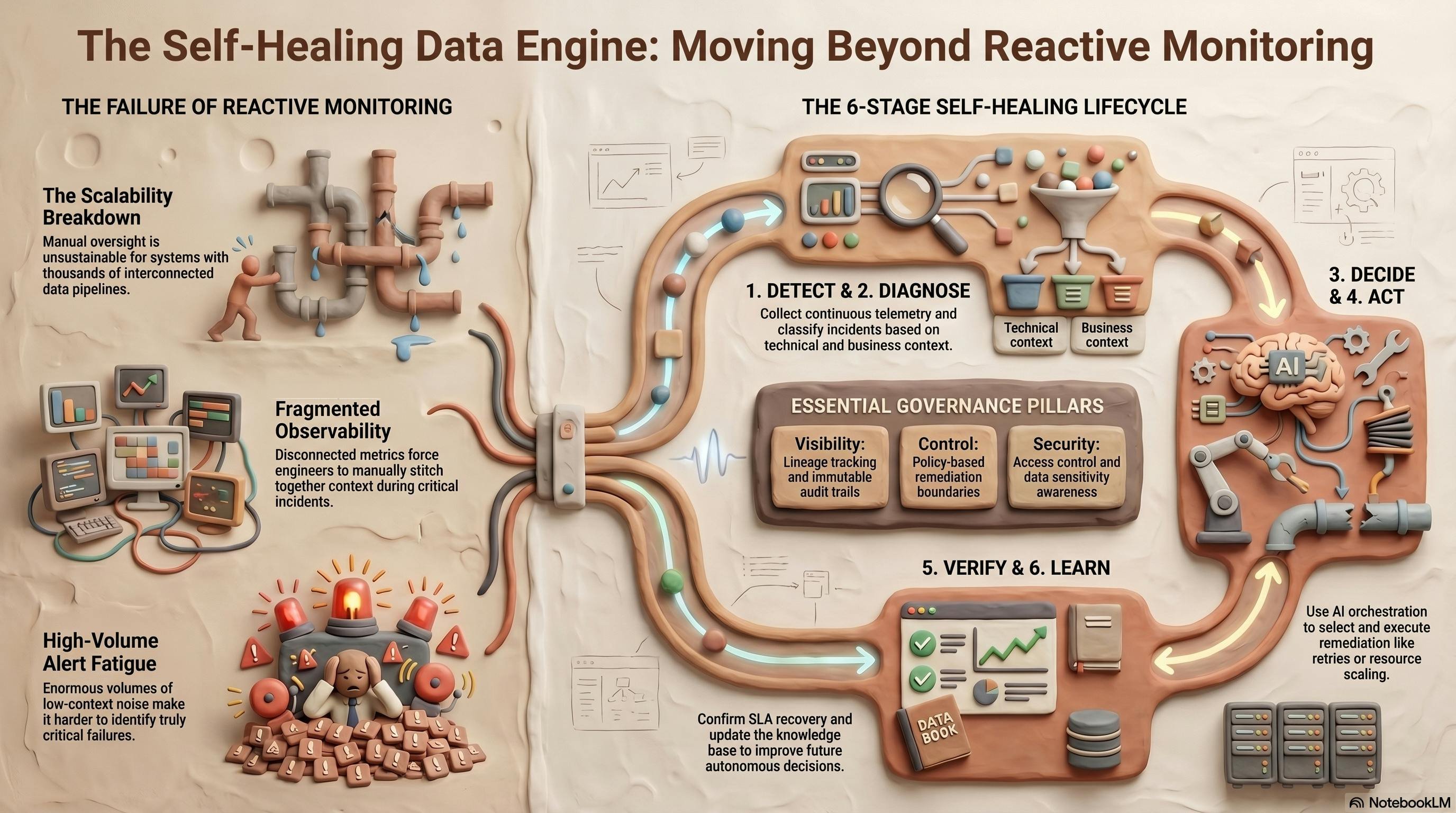
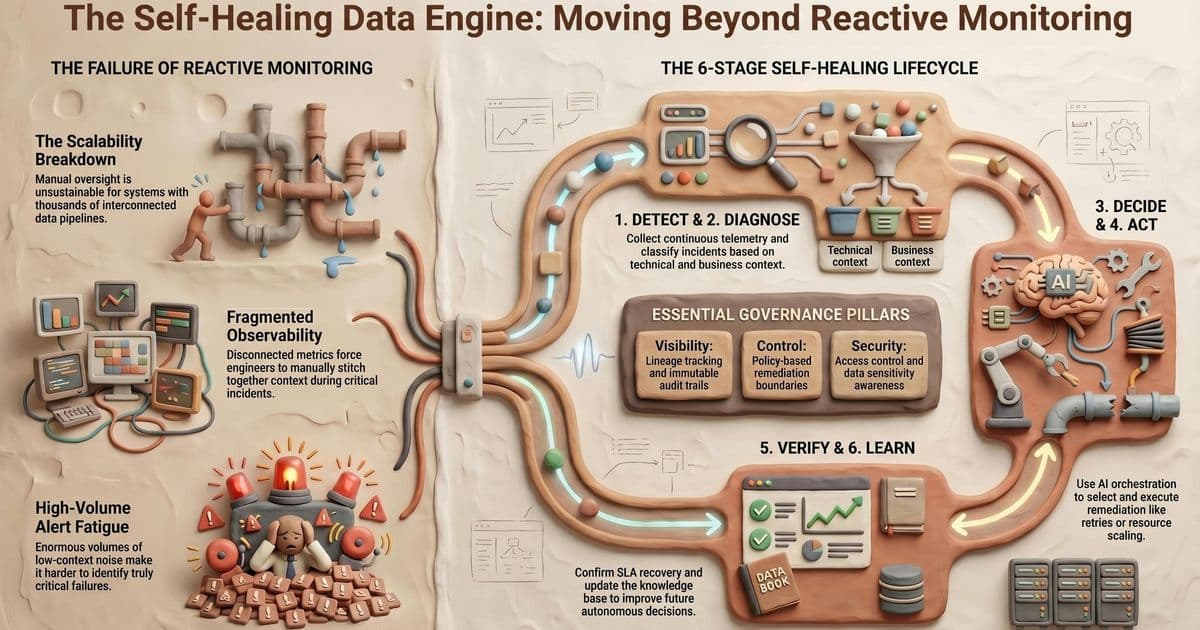
Modern enterprise data systems are now massive, distributed, and operationally intricate. Pipelines built on Airflow, Spark, Kafka, Databricks and cloud‑native ETL services move terabytes of data every hour, power real‑time analytics, feed machine‑learning models, and generate regulatory reports. Yet the reliability model that still dominates most organizations is reactive: an alert fires, engineers dig through logs, manually retry jobs, and hope the SLA is still met. At the scale of thousands of interconnected pipelines, that approach simply does not scale.
Why Traditional Monitoring Fails
- Scale overload – Thousands of DAGs, streaming jobs and micro‑services generate more alerts than any on‑call engineer can triage.
- Fragmented observability – Metrics, logs, schema‑drift detectors, and data‑quality checks live in separate tools, forcing operators to stitch context together during incidents.
- Silent AI degradation – A pipeline can appear healthy at the infrastructure level while model performance drifts because of subtle data‑quality issues.
- Alert fatigue – High‑volume, low‑signal alerts drown out the few critical incidents that truly need attention.
The result is a reliability workflow that is costly, slow and error‑prone. To keep up, enterprises must treat reliability as a design property, not an after‑thought.
Six Core Capabilities of a Self‑Healing Platform
A self‑healing data infrastructure is essentially a closed‑loop system that continuously cycles through six phases:
- Continuous telemetry collection – Real‑time ingestion of infrastructure metrics, pipeline states, streaming lag, SLA counters, schema changes and data‑quality signals.
- Intelligent anomaly detection – Machine‑learning models spot deviations from normal patterns across both technical and business dimensions.
- Context‑aware incident classification – The system tags each anomaly (e.g., transient node failure, schema drift, downstream quality breach) to decide the appropriate remediation path.
- Automated remediation orchestration – An AI‑driven decision engine evaluates historical incident data, dependency health and policy constraints to select actions such as intelligent retries, checkpoint rollbacks, traffic rerouting, or dynamic scaling.
- Recovery verification – After remediation, the platform checks that SLAs are restored, downstream pipelines are stable, and data quality thresholds are met before declaring the incident closed.
- Continuous operational learning – Every incident enriches a knowledge base that refines detection thresholds, improves decision policies and reduces future alert noise.
Together these capabilities shift the operational model from "detect‑then‑react" to "detect‑decide‑act‑verify‑learn".
Architectural Overview
The architecture can be visualized as a layered stack:
- Telemetry Layer – Agents and collectors push metrics, logs and custom signals into a time‑series store.
- Analytics Layer – Anomaly‑detection models (e.g., LSTM, isolation forest) run on streaming telemetry to flag outliers.
- Decision Layer – A policy‑aware engine consults a reliability knowledge graph, evaluates risk scores and selects remediation actions.
- Orchestration Layer – Workflow engines (e.g., Argo, Prefect) execute the chosen actions, respecting governance constraints.
- Verification Layer – Post‑action health checks confirm that the system returned to a defined steady state.
- Learning Layer – Incident outcomes feed back into model training pipelines, continuously improving detection and decision accuracy.
Figure: High‑level architecture of an autonomous self‑healing data infrastructure framework integrating telemetry, anomaly detection, remediation orchestration, governance, reliability scoring, and observability layers.
Governance – The Trust Anchor
Automation without oversight is a non‑starter for regulated sectors such as healthcare, finance or insurance. A self‑healing platform must therefore be observable, explainable, auditable and policy‑controlled. Key governance mechanisms include:
- Lineage tracking – Every data transformation and remediation step is recorded in an immutable graph.
- Audit trails – All automated actions are logged with user‑level attribution for compliance reviews.
- Policy engines – Fine‑grained rules define which actions can run autonomously and which require human approval.
- Access control – Role‑based permissions ensure that only authorized services can trigger high‑risk remediation.
- Data‑sensitivity tagging – The system distinguishes PHI, PCI or other regulated data, adjusting remediation strategies accordingly.
By embedding these controls, enterprises can gain confidence that autonomous actions will not violate compliance or introduce new risks.
What It Means for Engineers
Self‑healing infrastructure does not replace engineers; it reshapes their responsibilities:
- From firefighting to strategy – Teams spend less time on manual triage and more on defining policies, designing resilient architectures and improving the learning loop.
- Higher‑level observability – Engineers focus on reliability metrics (MTTR, error budgets) rather than individual alert thresholds.
- Continuous improvement – The operational knowledge base becomes a shared asset that grows with every incident.
Outlook
As cloud‑native AI platforms continue to expand—adding streaming analytics, real‑time model serving and multi‑cloud deployments—the gap between reactive monitoring and the need for autonomous reliability will only widen. Organizations that adopt a self‑healing approach can expect:
- Lower mean‑time‑to‑recovery (MTTR) through automated, context‑aware remediation.
- Reduced alert fatigue as the system filters noise before surfacing incidents.
- Stronger compliance postures thanks to built‑in governance layers.
- Greater scalability, allowing data teams to add pipelines without proportionally increasing operational headcount.
In short, the next generation of enterprise AI infrastructure will be intelligent, adaptive and governed. Building that capability now positions companies to keep pace with the growing complexity of data‑driven products.
Author bio: Baharath Bathula is a Data & AI Engineer at CVS Health, focusing on autonomous reliability systems and cloud‑native data platforms. He writes about the intersection of AI, observability and governance.
Comments
Please log in or register to join the discussion