
ClickHouse reimagines row-level updates by transforming them into high-speed inserts, leveraging its MergeTree architecture to avoid the traditional pitfalls of column stores. This deep dive explores purpose-built engines like ReplacingMergeTree and CollapsingMergeTree, revealing how they enable real-time data mutations without sacrificing analytical performance. For developers grappling with IoT, e-commerce, or financial data streams, this design offers a scalable path to handling volatile data
Columnar databases excel at analytical queries but often stumble when faced with row-level updates. Traditional row stores like PostgreSQL handle mutations efficiently by overwriting data in-place, but this comes at the cost of analytical speed. ClickHouse, optimized for blistering-fast inserts and aggregations, initially avoided this trade-off entirely—until real-world demands for updates in IoT sensor feeds, inventory systems, and financial records forced innovation. The solution? Treat updates as inserts.

The Insert-Only Philosophy: Why Updates Are a Column Store Nightmare
In column stores, data is split into per-column files. An update affecting multiple columns requires rewriting fragments across these files, creating I/O bottlenecks. ClickHouse flips this model by exploiting its core strength: insert performance. With no global indexes to lock, inserts scale linearly, handling over 1 billion rows per second in some deployments. By recasting updates and deletes as new row inserts, ClickHouse defers the heavy lifting to background merges—leveraging the continuous consolidation already inherent in its MergeTree engine.
"We sidestepped the update problem by treating updates as inserts. This isn’t a workaround; it’s a deliberate design choice," explains the ClickHouse team. The approach avoids random I/O, instead using sorted, immutable data parts that merge efficiently in linear passes.
Foundation: Parts, Merges, and Sorted Efficiency
Every ClickHouse insert creates a self-contained part—a folder of column files, sorted by the table’s key (e.g., (order_id, item_id)). For example, an initial insert into an orders table:
INSERT INTO orders VALUES
(1001, 'kbd', 10, 45.00, 0.00),
(1001, 'mouse', 6, 25.00, 0.00);
Generates a part like all_1_1_0, storing rows contiguously. Background merges combine parts through single-pass interleaving (no resorting needed), making consolidation cheap. This efficiency enables lightweight handling of mutations during merges.
Purpose-Built Engines: Three Paths to Lightning-Fast Mutations
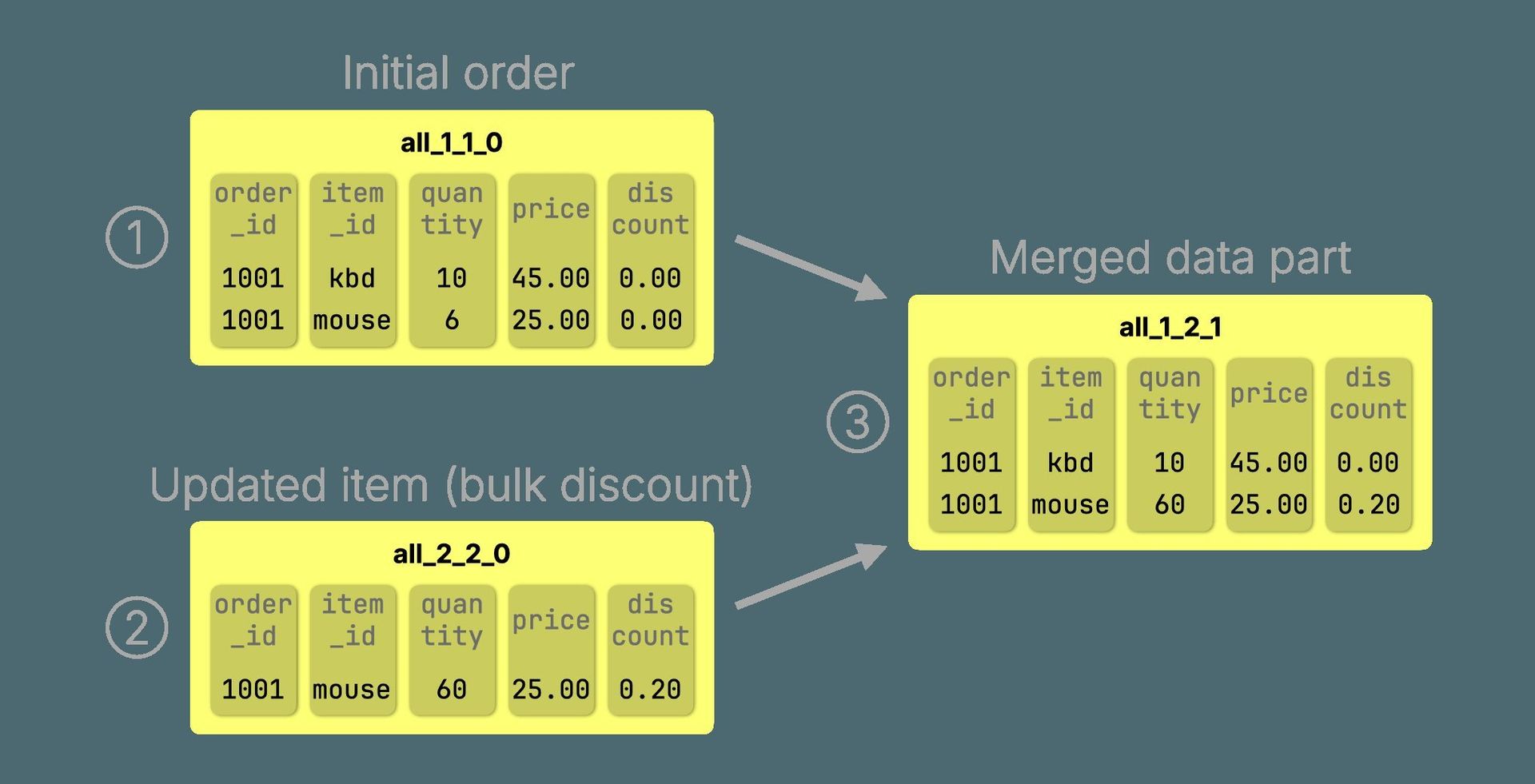
1. ReplacingMergeTree: Updates as New Versions
Define a table with ENGINE = ReplacingMergeTree and insert a new row with the same sorting key to update. Merges retain only the latest version:
CREATE TABLE orders (
order_id Int32,
item_id String,
quantity UInt32,
price Decimal(10,2),
discount Decimal(5,2)
) ENGINE = ReplacingMergeTree ORDER BY (order_id, item_id);
-- Initial insert
INSERT INTO orders VALUES (1001, 'mouse', 6, 25.00, 0.00);
-- Update: Insert increased quantity
INSERT INTO orders VALUES (1001, 'mouse', 60, 25.00, 0.20);
During merges, outdated rows are discarded.  visualizes this process.
visualizes this process.
2. CoalescingMergeTree: Partial Updates with Null Magic
Mark non-key columns as Nullable and insert only changed fields. Merges coalesce values into a complete row:
CREATE TABLE orders (
order_id Int32,
item_id String,
quantity Nullable(UInt32),
price Nullable(Decimal(10,2)),
discount Nullable(Decimal(5,2))
) ENGINE = CoalescingMergeTree ORDER BY (order_id, item_id);
-- Partial update: Only quantity and discount change
INSERT INTO orders VALUES (1001, 'mouse', 60, NULL, 0.20);
 shows how NULLs allow sparse inserts to merge into full rows.
shows how NULLs allow sparse inserts to merge into full rows.
3. CollapsingMergeTree: Deletes as Anti-Rows
Add a sign column (e.g., is_valid). Insert 1 for new rows and -1 to delete:
CREATE TABLE orders (
order_id Int32,
item_id String,
quantity UInt32,
price Decimal(10,2),
discount Decimal(5,2),
is_valid UInt8
) ENGINE = CollapsingMergeTree(is_valid) ORDER BY (order_id, item_id);
-- Delete: Insert a "cancelling" row
INSERT INTO orders VALUES (1001, 'mouse', NULL, NULL, NULL, -1);
Merges collapse matching +1 and -1 rows. 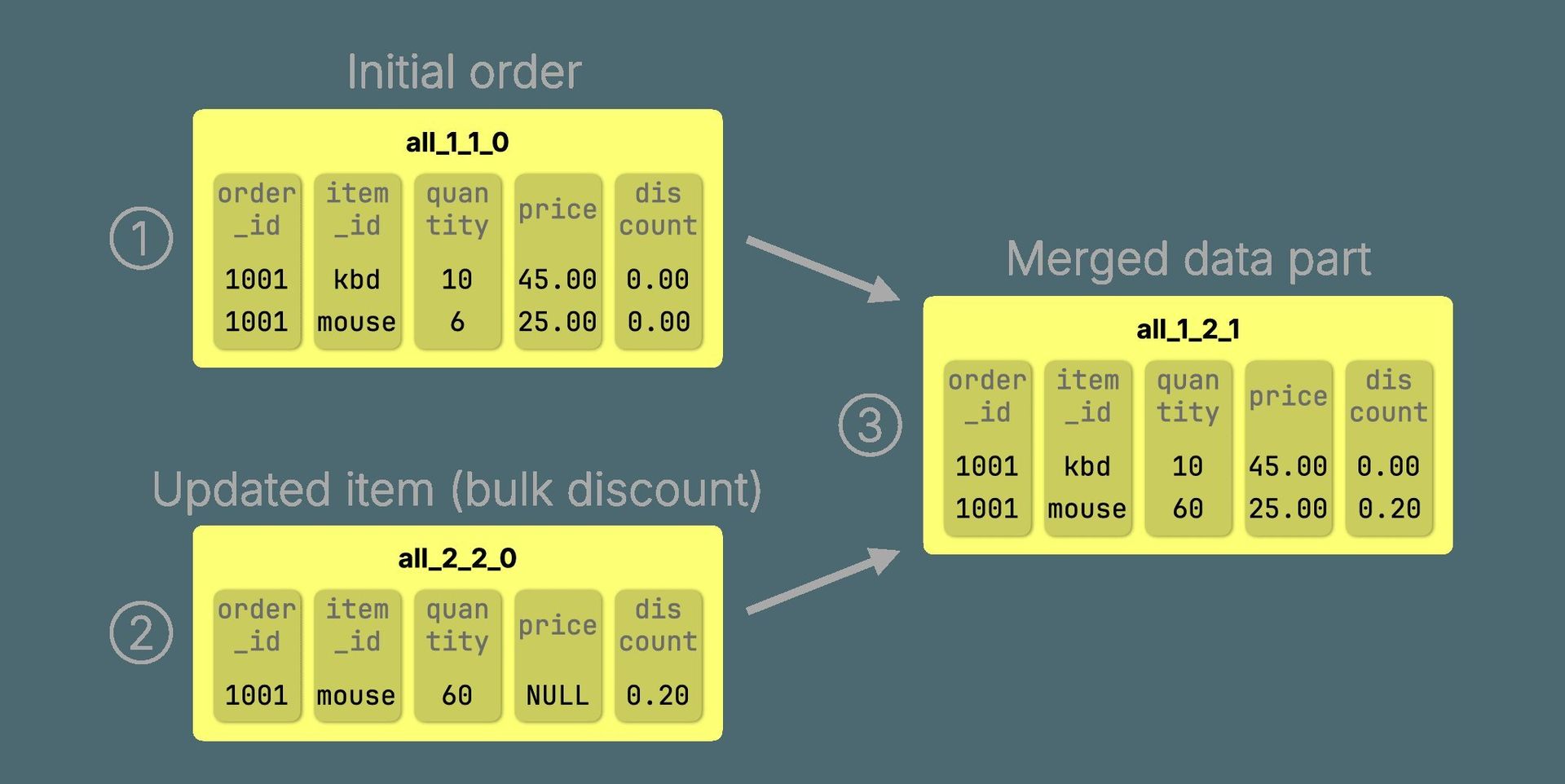 illustrates this—unique for supporting key changes.
illustrates this—unique for supporting key changes.
Immediate Consistency with FINAL: No Merge Wait Needed
Background merges introduce eventual consistency. For real-time accuracy, use FINAL in queries:
SELECT * FROM orders FINAL;
This performs in-memory consolidation during reads, applying engine logic (e.g., keeping latest rows or collapsing deletes) without on-disk merges. Optimizations skip unnecessary work, ensuring speed even on large datasets.
The Trade-Off: Power vs. Complexity
While these engines handle high-throughput scenarios elegantly, they demand ClickHouse-specific modeling. Developers must understand sorting keys, merge semantics, and engine quirks—ReplacingMergeTree can’t update keys, and schemas often require Nullable columns or sign flags. Yet, the payoff is profound: updates become as cheap as inserts, sustaining ClickHouse’s analytical prowess. As the team notes, this insert-and-merge rhythm mirrors traditional row stores in outcome but achieves it through scalable, lock-free parallelism.
In Part 2, ClickHouse evolves further, wrapping this ingenuity into SQL-standard UPDATE syntax via patch parts—proving performance and familiarity can coexist.
Source: ClickHouse Blog
Comments
Please log in or register to join the discussion