
An unemployed developer reverse-engineered PostgreSQL’s performance tuning to achieve the unthinkable: making the database 42,000 times slower. Through strategic sabotage of caching, vacuuming, WAL, and I/O configurations, this experiment reveals critical insights into Postgres’ performance boundaries.

In a world obsessed with optimizing database performance, Jacob Jackson pursued an unconventional goal: intentionally crippling PostgreSQL. His experiment—conducted while job hunting—demonstrates how easily misconfigured parameters can transform a high-performance database into a digital tortoise. Using TPC-C benchmarks on a Ryzen 7950x server, Jackson systematically dismantled Postgres’ efficiency through 32 deliberate postgresql.conf tweaks, exposing hidden vulnerabilities in default behaviors.
The Performance Baseline
Jackson started with a healthy setup: 10GB shared_buffers, optimized worker processes, and standard autovacuum settings. This baseline achieved 7,082 transactions per second (TPS). His mission? To dismantle this speed without touching indexes or hardware.
Starving the Cache
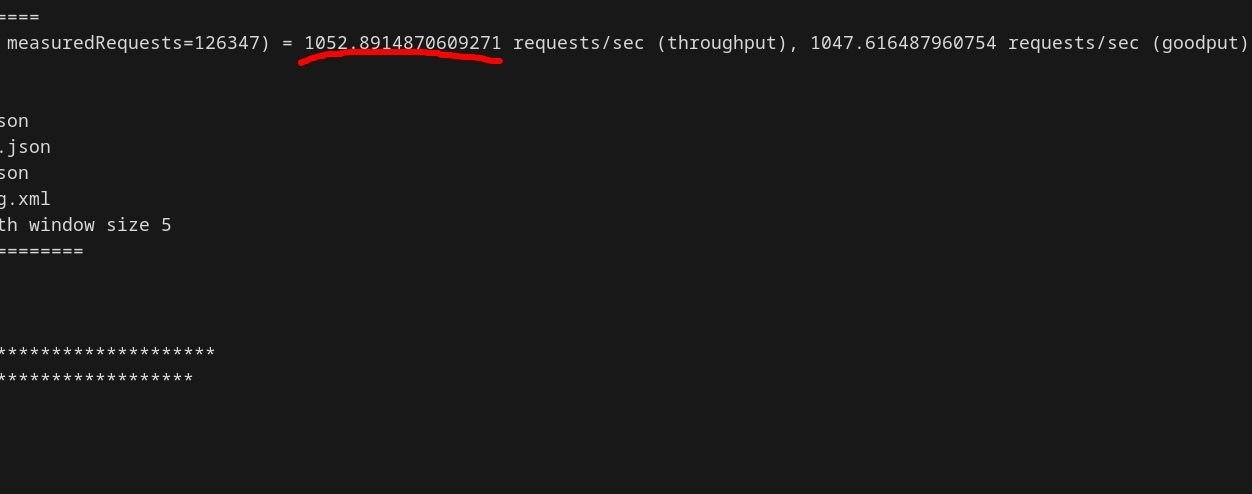
First, he minimized shared_buffers—the cache storing frequently accessed data. Reducing it to 8MB caused buffer hit rates to plummet from 99.9% to 70.5%, forcing constant disk reads. TPS dropped to 1,052.
Pushing further to 128kB crashed Postgres (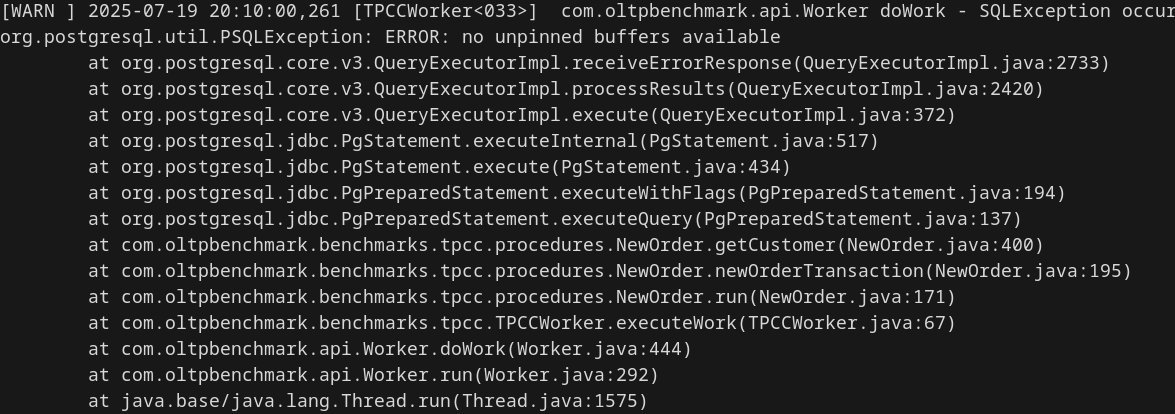 ), but 2MB proved workable—barely—slashing performance to 485 TPS (
), but 2MB proved workable—barely—slashing performance to 485 TPS (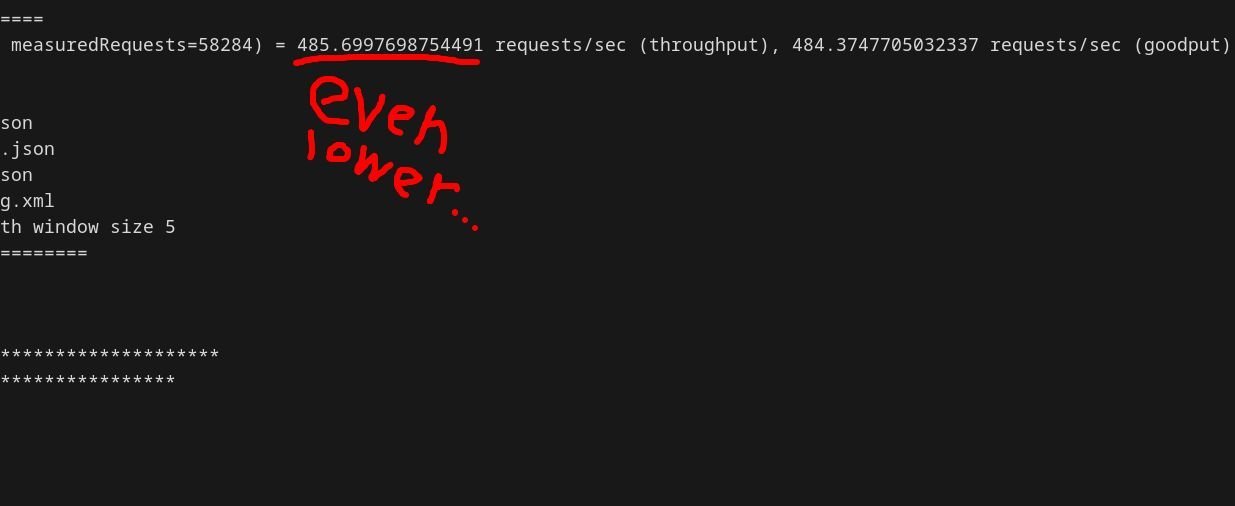 ).
).
Weaponizing Autovacuum
Jackson then reconfigured autovacuum to run incessantly:
autovacuum_vacuum_threshold = 0
autovacuum_naptime = 1 # Runs every second
maintenance_work_mem = 128kB # Starves memory for vacuum ops
This triggered vacuum/analyze cycles every second, flooding disks with pointless I/O. TPS nosedived to 293 (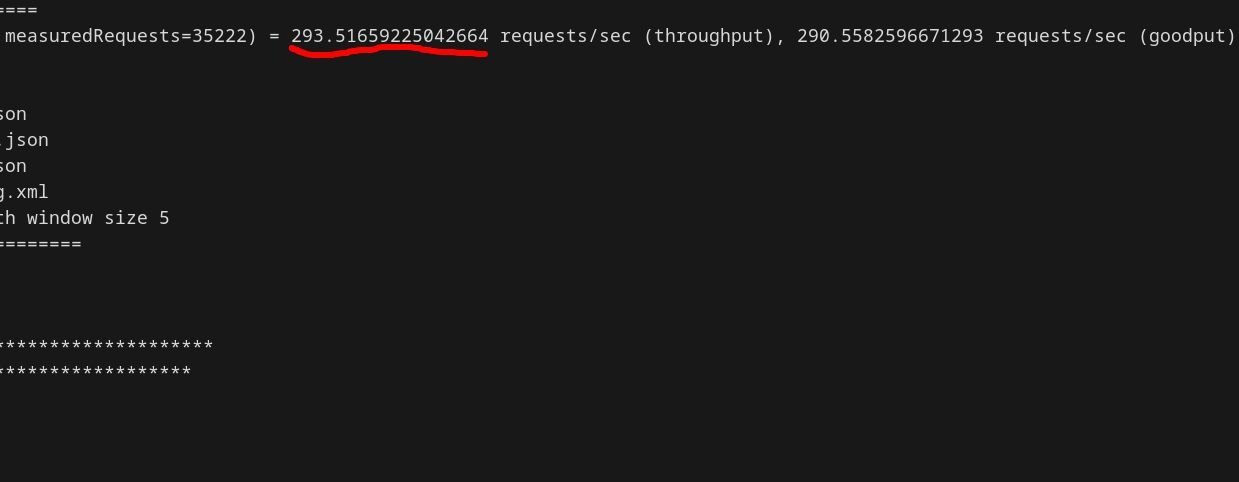 ). Logs confirmed chaos:
). Logs confirmed chaos:
LOG: automatic vacuum of table "benchbase.public.warehouse"...(repeated every second)
Crippling Write-Ahead Logging (WAL)
Next, Jackson attacked WAL efficiency:
wal_sync_method = open_datasync # Slowest sync method
checkpoint_timeout = 30s # Minimum interval between checkpoints
wal_level = logical # Forces excessive logging
Checkpoints fired every 30 seconds, overwhelming I/O. Warnings like "checkpoints are occurring too frequently" flooded logs, cutting TPS to double digits.
Banishing Indexes and I/O Parallelism
To sabotage query planning, he made index scans astronomically expensive:
random_page_cost = 1e300
cpu_index_tuple_cost = 1e300
Finally, Postgres 18’s new I/O features were exploited to bottleneck disk operations into a single thread:
io_method = worker
io_workers = 1
The Result: 42,000x Slowdown
The final configuration achieved 0.17 TPS—over 42,000 times slower than baseline. Only 11 transactions completed in 120 seconds across 100 connections. Jackson’s full config reads like a cautionary tale for DevOps teams.
Why This Matters
Beyond the dark humor, this experiment underscores critical lessons:
- Configuration sensitivity: Small changes can trigger catastrophic performance collapse.
- Monitoring gaps: Tools like
log_autovacuumand WAL metrics are essential for diagnosing self-inflicted wounds. - Default safeguards: Postgres’ refusal to set
shared_buffersbelow 2MB highlights built-in protections—but they’re easily bypassed.
As Jackson notes: "Postgres tries to make it difficult to make decisions this stupid." Yet his unemployment-fueled tinkering proves that with enough misguided determination, even robust systems can be brought to their knees. For engineers, it’s a stark reminder: performance isn’t just about avoiding bottlenecks—it’s about resisting the temptation to create them.
Source: Making Postgres 42,000x slower because I am unemployed by Jacob Jackson
Comments
Please log in or register to join the discussion