
Vercel's Fluid compute shatters AWS Lambda's one-request-per-instance model through a custom TCP transport layer and request multiplexing, enabling streaming responses and dramatic cost reductions. By intelligently routing traffic and introducing Active CPU pricing, they've transformed serverless economics for I/O-bound workloads like AI. This deep dive reveals the 2-year engineering journey behind architecture handling 45B weekly requests.

For over a decade, AWS Lambda's execution model—one request per instance, pay-for-all-allocated-time—defined serverless economics. Vercel's Fluid compute shatters this paradigm, slashing costs up to 95% while eliminating cold starts and enabling true streaming. The secret? A radical rearchitecture of serverless infrastructure that took two years to build. Here’s how they did it.
The Streaming Dilemma: Lambda’s Achilles' Heel
When React Server Components (RSC) demanded HTTP streaming in 2020, Vercel faced a fundamental limitation: AWS Lambda couldn’t stream responses (it has since added limited support). "Lambda’s model was simple: input blob in, output blob out," explains Vercel’s technical narrative. This binary approach couldn’t support chunk-by-chunk streaming required for modern UI frameworks.
Their solution? A custom TCP-based transport layer creating secure tunnels between Lambda functions and Vercel’s infrastructure. Instead of monolith blobs, they designed a packet protocol:
ResponseStarted: Initiate streamResponseBody: Data chunksResponseEnd: Terminate stream
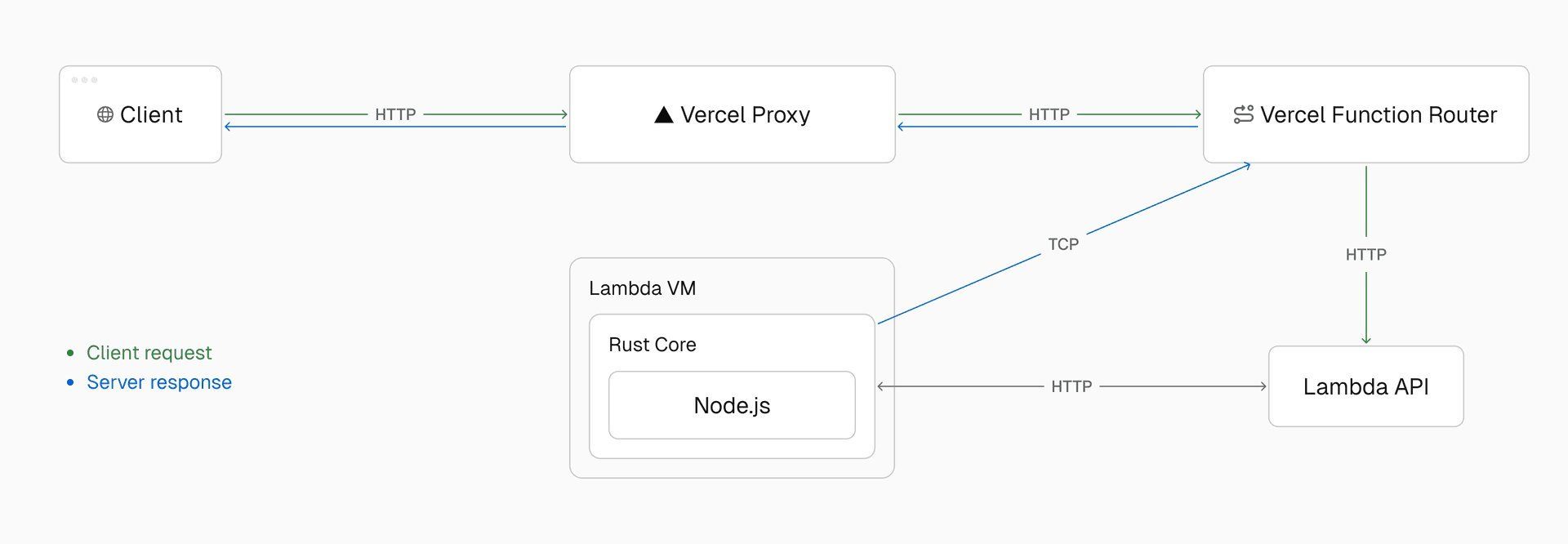 Vercel’s TCP tunnel architecture enabling real-time streaming between Lambda and edge routers
Vercel’s TCP tunnel architecture enabling real-time streaming between Lambda and edge routers
A Rust core translated between HTTP (Node.js/Python) and this protocol, unlocking features like waitUntil and enhanced logging. But during development, engineers had a revelation: What if this bidirectional tunnel could handle multiple requests per instance?
Breaking Lambda’s Cardinal Rule: Multiplexing Magic
Lambda’s "one invocation, one instance" model creates enormous waste—functions sit idle during I/O (database calls, LLM reasoning). Vercel realized their tunnel could multiplex requests onto active instances, dramatically improving density. The implications were seismic:
- Cost Reduction: Pay for useful work, not idle time
- Performance Boost: Fewer cold starts
- Resource Efficiency: Higher utilization rates
But implementation was treacherous. As traffic scales across Vercel’s 19 global regions, routing requests to reusable instances became a needle-in-haystack problem. Their solution? Compute-Resolver—a DNS-like service tracking function locations.
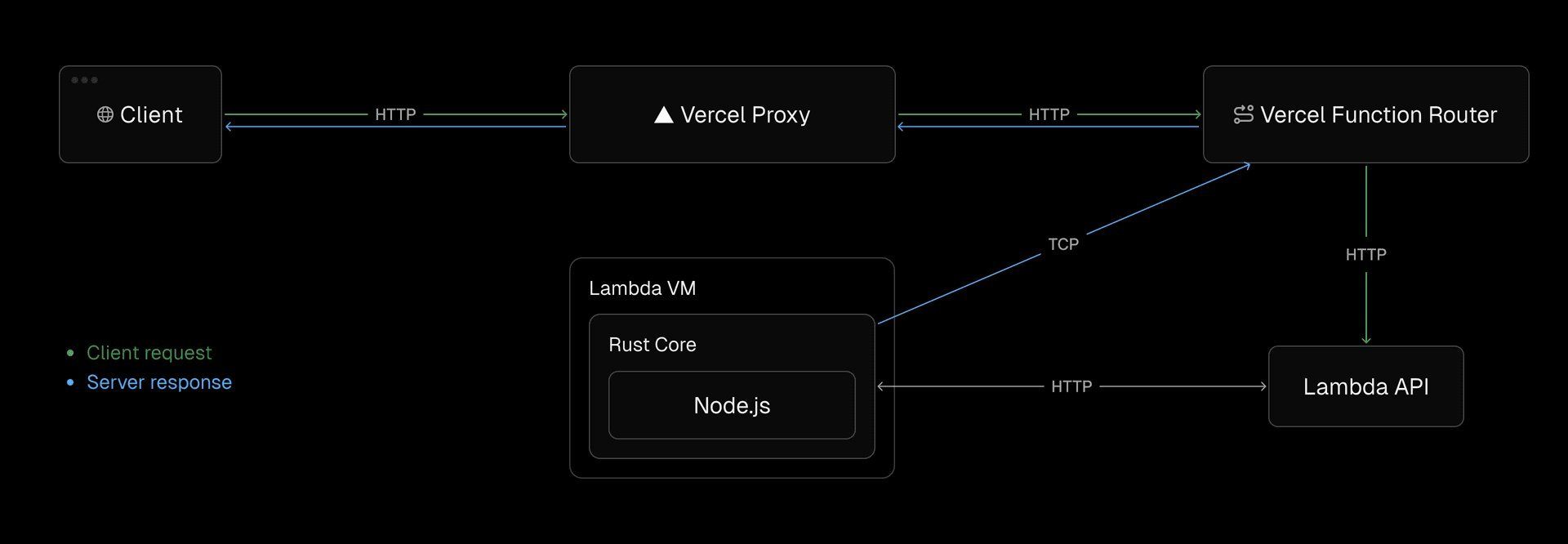 Multiplexing shatters Lambda’s one-request-per-instance model by reusing active connections
Multiplexing shatters Lambda’s one-request-per-instance model by reusing active connections
"At peak, Compute-Resolver handles >100K RPS with sub-millisecond p99.99 latency," notes the team. By routing 99%+ of requests to routers with active connections, reuse rates skyrocketed.
The Health Conundrum: Avoiding Meltdowns
Multiplexing risks overloading instances. Vercel engineered real-time heuristics to prevent disasters:
fn can_accept_request(instance: &Instance) -> bool {
!(cpu_throttled() ||
memory_near_limit() ||
file_descriptors_exhausted() ||
recent_timeouts())
}
Pseudocode of health checks preventing resource exhaustion
The Rust core continuously streams metrics to routers, which:
- Select instances with most available resources
- Use optimistic concurrency (back off at thresholds)
- Accept
nacksignals from overloaded Lambdas
This language-agnostic system adapts to varied workloads without manual tuning—crucial for unpredictable AI traffic.
Active CPU Pricing: The Economic Earthquake
Fluid compute’s architecture enabled Vercel’s Active CPU pricing model:
- Pay per ms of CPU time (not wall time)
- Memory billed per GB-hour
- Zero cost for idle cycles
Results are staggering: Additional 90%+ savings for I/O-bound workloads like AI inference via Model Context Protocol (MCP). Combined with Fluid’s base efficiencies:
- 75% of Vercel Functions now use Fluid
- 45B+ weekly requests processed
- 95% cost reductions reported
The New Serverless Calculus
Vercel’s 2-year engineering marathon proves serverless doesn’t require sacrificing efficiency at scale. By decoupling execution from Lambda’s constraints via custom protocols and intelligent routing, they’ve created a model where:
- Streamed responses enable modern app architectures
- Multiplexing turns idle cycles into cost savings
- Granular pricing aligns spend with actual compute
As AI workloads explode, Fluid compute offers a template for sustainable scalability—where servers truly become invisible, not inefficient.
Comments
Please log in or register to join the discussion