
GitHub reduced token consumption by up to 62% across internal agentic CI workflows by normalizing usage data across Anthropic, OpenAI, and first-party agent frameworks, then applying targeted optimizations from unused tool pruning to deterministic data pre-fetching. The strategies, now available to all GitHub Agentic Workflows users, provide a repeatable blueprint for controlling cloud automation costs as agentic CI adoption scales across multi-cloud environments.

GitHub Agentic Workflows function as automated maintenance teams that handle routine repository hygiene tasks, from triaging issues to checking compiler quality. These automations improve code quality and reduce manual toil, but they introduce a hidden cost risk. Because agentic workflows trigger automatically on events like new pull requests or issues, token consumption accumulates without direct developer oversight, especially as teams scale their use of large language model (LLM) powered CI tasks.
GitHub’s engineering team, which maintains hundreds of agentic workflows across its own repositories, faced this challenge directly. In April 2026, the team began a systematic effort to optimize token usage across all production workflows, combining usage instrumentation, automated auditing, and targeted technical optimizations. The effort produced up to 62% reductions in effective token consumption for high-frequency workflows, with strategies now available to all users of the GitHub Agentic Workflows framework.
Instrumenting Token Usage
Before optimizing token consumption, the team needed visibility into how tokens were spent. The first hurdle was fragmented logging: agent frameworks including Claude CLI (Anthropic), Copilot CLI (GitHub), and Codex CLI (OpenAI) emitted usage data in incompatible formats, with incomplete historical records for past runs.
The team solved this using the existing security architecture for agentic workflows, which routes all agent API calls through a proxy to prevent direct access to authentication credentials. This proxy was extended to capture token usage in a single normalized format, regardless of the underlying agent framework. Every workflow now outputs a token-usage.jsonl artifact containing one record per API call with fields for input tokens, output tokens, cache-read tokens, cache-write tokens, model name, provider, and timestamps. Combining this data with workflow logs provides a complete historical view of token spend, enabling targeted optimization.
Automated Optimization Workflows
With normalized token data available, the team built two daily agentic workflows to continuously monitor and improve efficiency:
- The Daily Token Usage Auditor aggregates consumption data from recent workflow runs, flags anomalies such as sudden usage spikes or unexpected increases in LLM turns per run, and surfaces the most expensive workflows across the portfolio.
- The Daily Token Optimizer reviews flagged workflows, cross-references usage data with workflow configuration, and creates GitHub issues with concrete inefficiency descriptions and specific optimization recommendations.
Both workflows are agentic automations themselves, so their token usage appears in daily reports, creating a self-reinforcing cycle of improvement. Teams can deploy these same workflows using the gh-aw CLI with two commands:
gh extensions install github/gh-aw
gh aw add githubnext/agentic-ops/copilot-token-audit githubnext/agentic-ops/copilot-token-optimizer
Provider Comparison and Cost Normalization
A core challenge in optimizing agentic workflows is comparing token usage across different LLM providers and model tiers, which have vastly different cost structures. The team used three primary agent frameworks, each tied to a different provider:
- Anthropic Claude CLI: Offers three model tiers with distinct cost profiles. Haiku is the lowest cost option, with a 0.25x multiplier in GitHub’s Effective Tokens (ET) metric. Sonnet serves as the baseline 1x multiplier. Opus is the highest capability tier, with a 5x multiplier. Anthropic’s pricing page confirms these tiers, with Haiku costing roughly 4x less per token than Sonnet.
- GitHub Copilot CLI: A first-party framework that integrates directly with GitHub Actions, using a mix of proprietary models and third-party APIs. Its token costs align with the underlying model selected for each workflow.
- OpenAI Codex CLI: Uses OpenAI’s Codex models, which have separate pricing tiers not directly comparable to Anthropic’s structure using raw token counts alone.
To normalize cost across all providers and models, the team developed the Effective Tokens (ET) metric:
ET = m × (1.0 × I + 0.1 × C + 4.0 × O)
Where:
mis the model cost multiplier (Haiku = 0.25, Sonnet = 1.0, Opus = 5.0)Iis newly processed input tokensCis cache-read tokensOis output tokens
Output tokens carry a 4x weight because they are the most expensive token type across all major providers. Cache-read tokens carry a 0.1x weight because they are served from cached context at a fraction of the cost of fresh input. This formula ensures a 10% reduction in ET corresponds to a genuine 10% cost reduction, regardless of which model or provider a workflow uses. Raw token counts fail to capture these differences, as a workflow switched from Opus to Haiku would show similar token counts but a 95% cost reduction.
Key Technical Optimizations
The Daily Token Optimizer identified three high-impact, repeatable optimizations applicable to most agentic workflows:
Pruning Unused MCP Tools
Most agentic workflows use the Model Context Protocol (MCP) to register tools the LLM can call, such as fetching pull request diffs or updating issue labels. Because LLM APIs are stateless, agent runtimes include full tool function names and JSON schemas with every request. A GitHub MCP server with 40 tools adds 10–15 KB of schema data per LLM turn, even if the agent only uses 2 of the available tools.
Workflow authors often start with a full toolset for simplicity, but most workflows settle into a narrow, stable set of required tools over time. The Optimizer cross-references tool manifests with actual tool call logs to identify unused registrations, then recommends pruning them from the workflow configuration. For GitHub’s smoke-test workflows, removing unused tools reduced per-call context size by 8–12 KB, saving thousands of tokens per run with no change in workflow behavior.
Replacing GitHub MCP with GitHub CLI
Removing unused MCP tools delivers quick wins, but a larger structural optimization is replacing MCP-based data fetching with calls to the GitHub CLI (gh). MCP tool calls require a full LLM reasoning step: the agent must decide to call the tool, formulate arguments, and process the response, which counts as a full API round-trip with associated token costs for tool schemas, arguments, and output.
By contrast, running gh pr diff or gh issue view is a deterministic HTTP request to GitHub’s REST API with no LLM involvement. The team used two strategies to migrate workflows:
- Pre-agentic data downloads: For data the agent will always need, such as a pull request diff or list of changed files, add setup steps to the workflow that run
ghcommands before the agent starts, writing results to workspace files. The agent reads these files directly instead of making MCP calls, eliminating tool-call overhead and letting the agent use its training in bash scripting to process data efficiently. - In-agent CLI proxy substitution: For data the agent determines it needs at runtime, use a lightweight transparent HTTP proxy that routes
ghtraffic to GitHub’s API without exposing authentication tokens to the agent. This maintains the zero-secrets security requirement for agentic workflows while removing LLM involvement from data retrieval.
Together, these techniques move the majority of GitHub data fetching out of the LLM reasoning loop, cutting unnecessary token spend.
Fixing Misconfigured Workflow Rules
The team also found that single-line misconfigurations can cause runaway token consumption. The Daily Syntax Error Quality workflow, the highest token consumer before optimization, had a misconfigured bash allowlist that only permitted relative-path glob patterns. When the workflow tried to compile files copied to /tmp/ using gh aw compile *, every attempt was blocked. The agent fell into a 64-turn fallback loop, manually reading source code to reconstruct compiler output instead of using the tool. A one-line fix to the allowlist eliminated the loop entirely.
Initial Results and Business Impact
The team deployed the auditor and optimizer across a dozen production workflows in the gh-aw and gh-aw-firewall repositories, then compared ET for runs before and after optimization. Results below cover workflows with at least eight runs in both pre- and post-optimization periods:
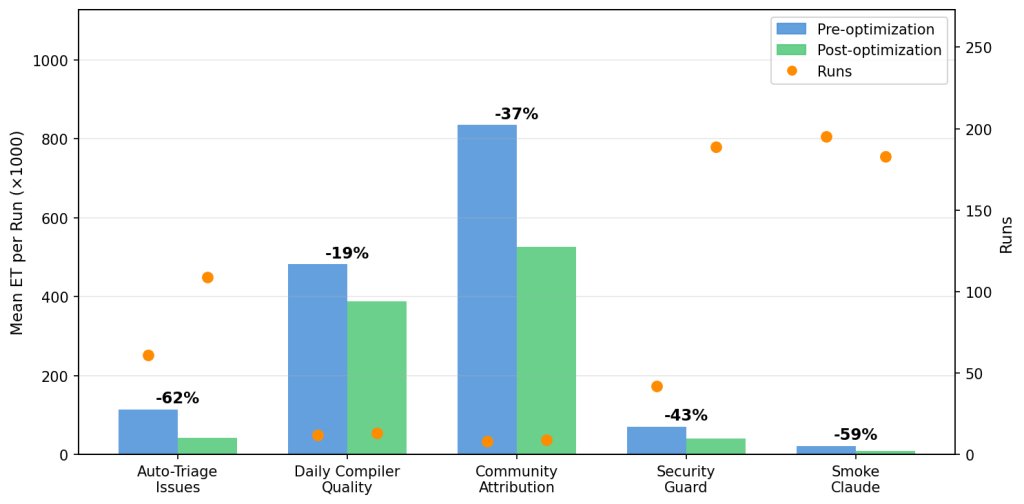
- Auto-Triage Issues: 62% ET reduction across 109 post-fix runs. This workflow fires on every new issue, averaging 6.8 runs per day, so the savings compound quickly: over the observation period, the optimization saved roughly 7.8 million ET.
- Daily Compiler Quality: 19% improvement over 12 post-fix runs.
- Community Attribution: 37% improvement over eight post-fix runs.
- Security Guard: 43% reduction in the
gh-aw-firewallrepo, which audits every pull request for security-sensitive changes. - Smoke Claude: 59% reduction in the
gh-aw-firewallrepo, an integration test for the firewall’s Claude CLI path.
Run frequency proved as important as per-run savings. Auto-Triage Issues and Security Guard run multiple times per day, so even moderate per-run improvements deliver outsized aggregate savings. Not all workflows showed immediate gains: the Contribution Check workflow had a 5% ET increase post-optimization, but this was due to a shift in workload (more large pull requests) rather than failed optimizations. Output tokens, weighted 4x in the ET formula, rose 14% as the agent reviewed larger diffs, masking per-turn efficiency gains.
For context, the cheapest LLM call is the one not made. Auto-Triage Issues saw its largest gains from moving deterministic data-gathering steps out of the LLM loop entirely, while Security Guard added a relevance gate that skips the LLM for pull requests that do not touch security-sensitive files.
Strategic Implications for Multi-Cloud Teams
These results hold clear lessons for organizations running agentic workflows across multi-cloud or large-scale cloud-native CI environments. First, token efficiency directly impacts cloud spend: as agentic CI adoption scales, unoptimized workflows can lead to unexpected cost overruns, especially for high-frequency automations. Second, normalizing cost across providers is critical: teams using multiple LLM providers need a unified metric like ET to avoid overspending on expensive models when cheaper tiers suffice. Third, most agent turns are deterministic data-gathering tasks that do not require LLM reasoning, making them low-hanging fruit for optimization.
Trade-offs exist for every optimization. Pruning MCP tools requires periodic review as workflows evolve, pre-agentic data downloads only work for predictable data needs, and CLI substitution requires workflows to have access to the gh CLI. However, the team found these trade-offs negligible compared to the cost savings and unchanged workflow behavior.
What’s Next: System-Level Optimization
GitHub’s team is now moving beyond workflow-level optimization to system-level improvements. Future work includes refactoring monolithic agents into teams of subagents using smaller, cheaper models, breaking workflows into episodes (context gathering, retries, synthesis) to identify costly phases, and portfolio-level analysis to reduce duplicate work across workflows.
Portfolio-level optimization is particularly relevant for multi-cloud teams running dozens of agentic automations. Many workflows trigger on the same events, inspect the same diffs, and produce adjacent judgments, leading to redundant token spend. Caching shared intermediate artifacts instead of rediscovered them for each run could deliver additional savings.
The team also notes open challenges: there is no standard agentic CI benchmark to measure quality, and process signals (turn counts, output tokens per call) do not capture outcome quality. Measuring tokens per unit of correct work requires additional instrumentation that is not yet widely available.
For those interested in hands-on agentic workflow discussions, GitHub will host OpenClaw: After Hours at its San Francisco HQ on Wednesday, June 3, 2026, from 5:30 to 9 PM.  The event coincides with Microsoft Build 2026, with in-person demos and a Twitch livestream available.
The event coincides with Microsoft Build 2026, with in-person demos and a Twitch livestream available.
Getting Started
Teams running agentic workflows in CI can apply these same strategies immediately. The first step is adding API proxy-level observability to normalize token usage across all providers and frameworks. The auditor and optimizer workflows are available via the gh-aw CLI, and can run alongside existing CI to provide immediate visibility into usage.
For support, join the #agentic-workflows channel on the GitHub Next Discord or participate in the GitHub Community discussion for agentic workflows.
Comments
Please log in or register to join the discussion