
Apache Kafka's shift from ZooKeeper to its native KRaft consensus protocol marks a seismic architectural change. This deep dive unpacks how KRaft leverages Raft for streamlined metadata management, enhanced scalability, and simpler Kafka deployments—fundamentally reshaping cluster operations.
For over a decade, Apache Kafka relied on Apache ZooKeeper for cluster coordination—a dependency that introduced operational complexity, scalability challenges, and a single point of failure. With the KRaft protocol (Kafka Raft Metadata mode), Kafka engineers have engineered an elegant solution: Kafka now manages its own metadata using a Raft consensus implementation, eliminating ZooKeeper entirely. This isn’t just an incremental upgrade—it’s a foundational rewrite of Kafka’s control plane.
The ZooKeeper Burden and KRaft’s Promise
Kafka’s original architecture separated data planes (brokers handling producer/consumer traffic) from control planes (ZooKeeper managing cluster state). This division forced operators to manage two distributed systems, each with its own failure modes and scaling constraints. KRaft collapses this duality by embedding a Raft-based consensus layer directly into Kafka brokers. Controllers—now just specialized broker roles—form a Raft quorum to replicate metadata changes as committed log entries.

How KRaft Replicates State: Raft Under the Hood
KRaft models cluster metadata (topics, partitions, configurations) as an immutable log. When a controller proposes a change—like creating a topic—it appends the change as an entry to its log. The Raft protocol ensures this entry is replicated to a quorum of controllers before being committed and applied to the cluster state. This guarantees strong consistency without ZooKeeper’s overhead.
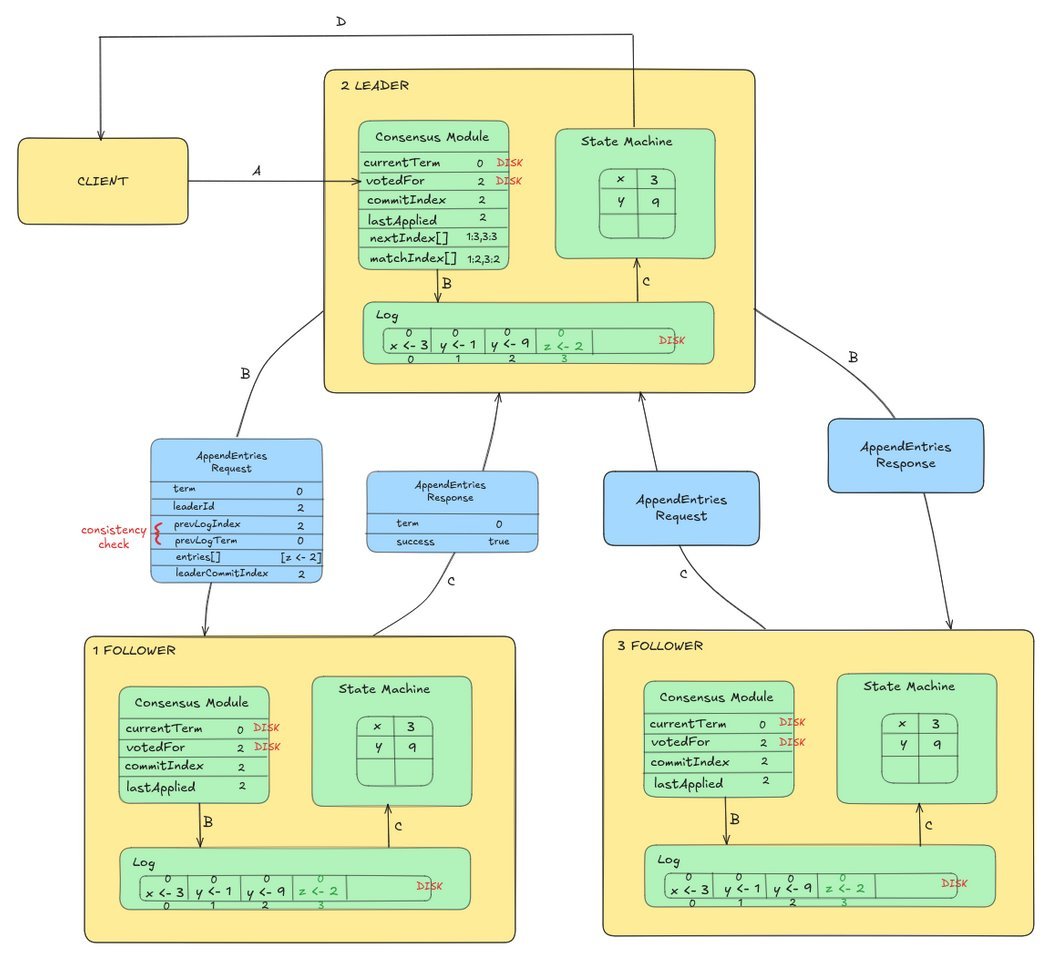
Figure: KRaft’s state replication mechanism. Uncommitted entries (like z <- 2) must achieve quorum consensus before becoming visible.
Inside a Metadata Operation: Creating Topics in KRaft
Consider a CreateTopics API call in KRaft:
- The client request hits a broker, which forwards it to the active controller.
- The controller appends the topic creation record to its log.
- The record is replicated to follower controllers via the Raft protocol.
- Once a quorum acknowledges the record, it’s committed.
- The controller applies the change, updating the metadata cache.
- Brokers sync the new state, making the topic available.
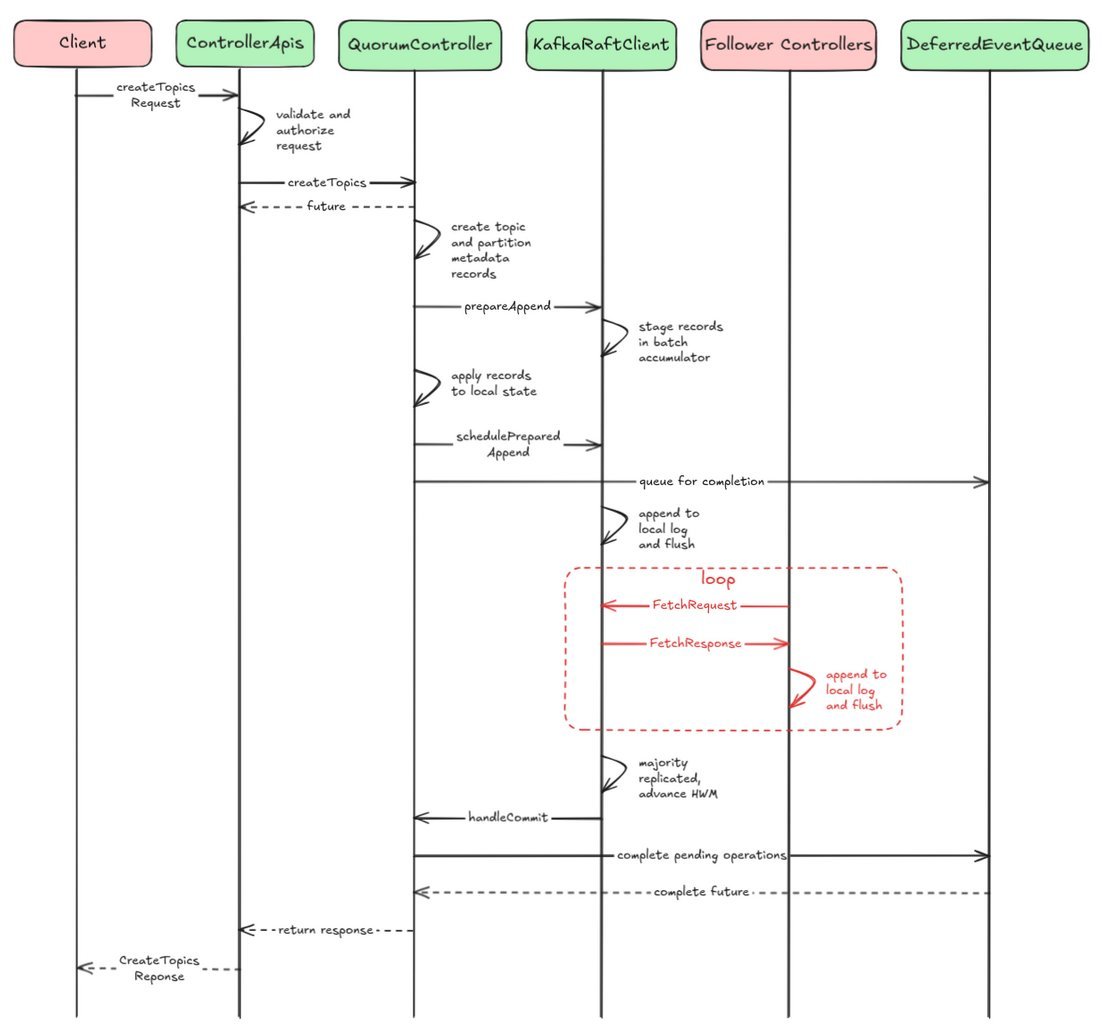
Figure: Simplified sequence flow for CreateTopics in KRaft. Note the absence of ZooKeeper round-trips.
Why This Matters: Simplicity, Scale, and Self-Sufficiency
- Operational Simplicity: No more tuning or monitoring a separate ZooKeeper cluster. Kafka is now a single, self-contained system.
- Enhanced Scalability: KRaft handles metadata for 100,000+ partitions—orders of magnitude beyond ZooKeeper’s limits.
- Faster Recovery: Controller failover now takes seconds (not minutes) thanks to Raft’s leader election.
- Unified Security: A single set of TLS/authentication configs applies to all components.
The Road Ahead: A Kafka-Centric Future
KRaft isn’t just an optimization—it’s an enabler. By internalizing consensus, Kafka unlocks smoother Kubernetes deployments, leaner cloud offerings, and real-time metadata changes critical for dynamic environments. While ZooKeeper-based deployments persist, KRaft represents Kafka’s future: a simpler, faster, and fundamentally more resilient architecture. For developers and operators alike, understanding KRaft is now essential Kafka literacy.
Source: Red Hat Developers: Deep Dive into Apache Kafka's KRaft Protocol
Comments
Please log in or register to join the discussion