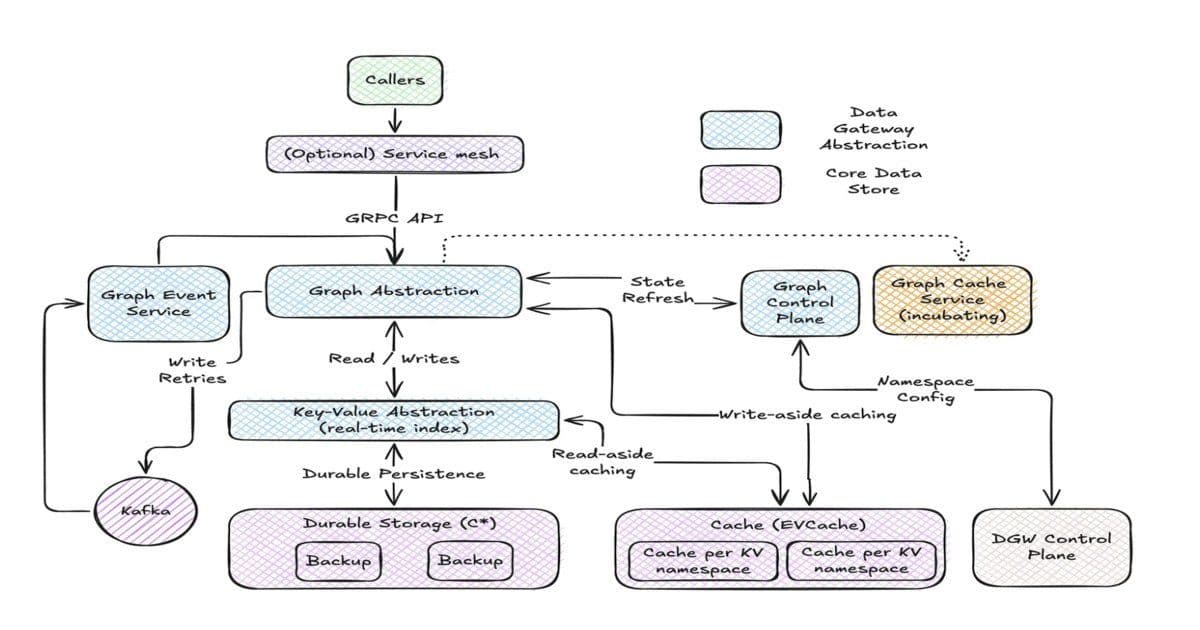
Netflix engineers have built Graph Abstraction, a high-throughput system managing 650TB of graph data globally with millisecond-level queries. The platform powers internal services including social graphs for Netflix Gaming and service topology graphs for operational monitoring, achieving single-digit millisecond latency for single-hop traversals through a carefully balanced architecture that trades query flexibility for predictable performance.
Netflix engineers have built Graph Abstraction, a high throughput system designed to manage large scale graph data in real time. The platform powers several internal services, including social graphs for Netflix Gaming and service topology graphs used for operational monitoring and incident analysis. By separating edge connections from edge properties and replicating data globally, the system enables millisecond level queries across roughly 650 TB of graph data, allowing engineers to analyze complex relationships quickly and reliably.
Graph processing systems often face a trade off between expressive queries and predictable performance. Traditional graph databases tend to prioritize flexible traversal and complex query capabilities, but many operational workloads require extremely fast responses at high throughput. To meet these requirements, Netflix's system restricts traversal depth and often requires a defined starting node, trading some query flexibility for consistent low latency at scale.
Graph Abstraction supports several internal use cases. These include a real time distributed graph that captures interactions across services in the Netflix ecosystem, a social graph used by Netflix Gaming to model user relationships, and a service topology graph that helps engineers analyze dependencies during incidents and root cause investigations. The platform also maintains historical graph state through a TimeSeries abstraction, enabling analytics, auditing, and temporal queries over graph evolution.
Rather than building a standalone graph database, Graph Abstraction is implemented as a layer on top of Netflix's existing data infrastructure. The latest graph state is stored in a Key Value abstraction, while historical changes are recorded through the TimeSeries abstraction. To reduce latency, the system integrates with EVCache, Netflix's distributed caching layer. Graph schemas are loaded into memory and strictly enforced, enabling validation, optimized traversal planning, and elimination of invalid query paths.
The platform also uses caching strategies: write-aside caching prevents duplicate edge writes, while read-aside caching accelerates access to node and edge properties. These techniques reduce read and write amplification and maintain performance under heavy workloads.
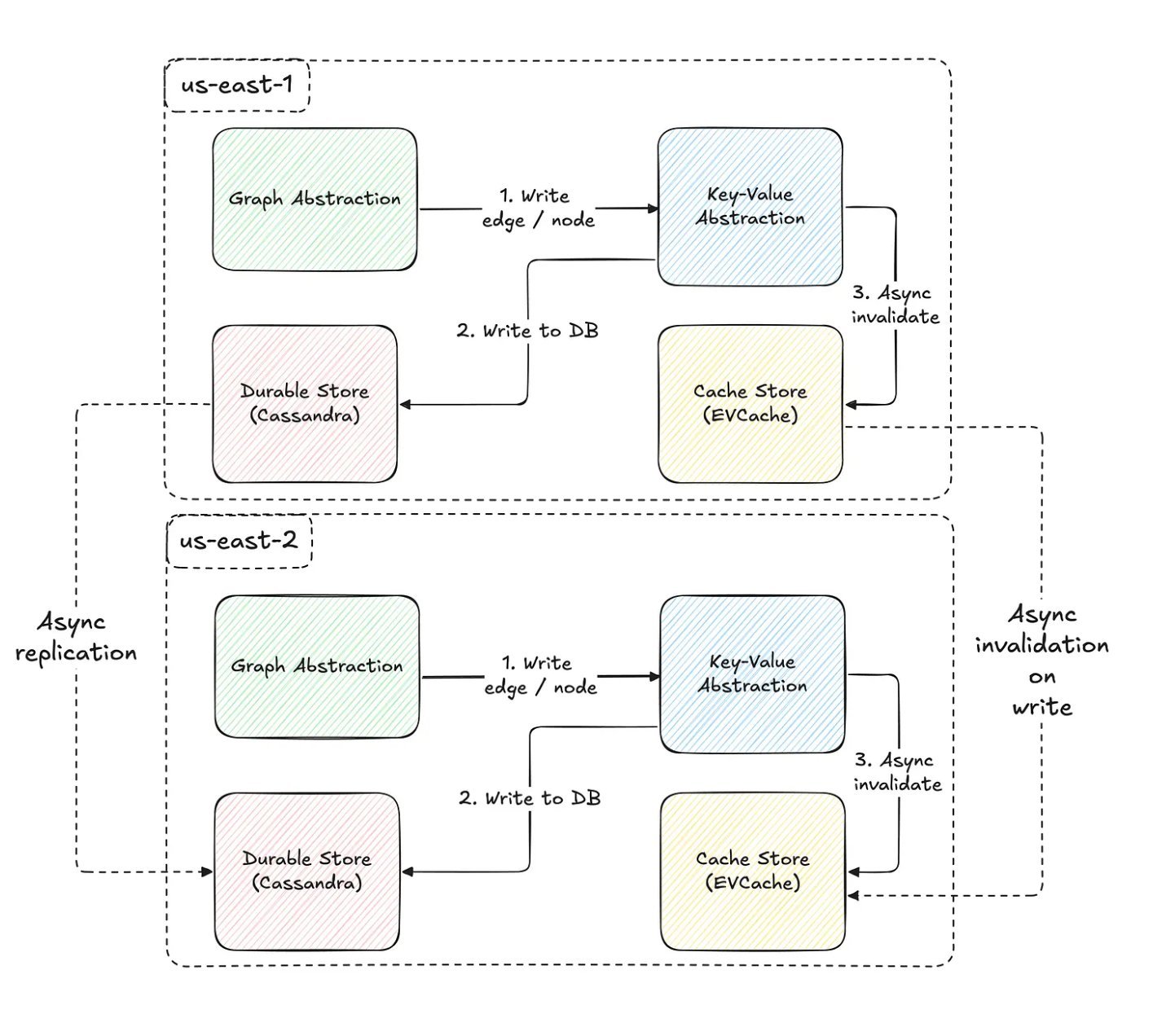
Graph Abstraction exposes a gRPC traversal API inspired by Gremlin, enabling services to chain traversal steps, apply filters, and limit results. Netflix engineers describe that global availability was achieved through asynchronous replication across regions, ensuring eventual consistency while supporting high throughput. Both caching layers and durable storage replicate graph data across regions, balancing latency, availability, and consistency trade-offs.
Netflix engineers emphasize that in production the system delivers single digit millisecond latency for single hop traversals and under 50 milliseconds for two hop queries at the 90th percentile, providing predictable performance at scale. The design carefully balances traversal planning and execution to enable efficient exploration of large graph datasets.
As Netflix expands into new verticals such as live content, gaming, and advertising, Graph Abstraction is expected to play an increasingly important role in modeling relationships between users, services, and content while maintaining high throughput, global availability, and low latency access across the platform.
Technical Architecture Deep Dive
The Graph Abstraction system represents a sophisticated approach to handling massive-scale graph data that differs significantly from traditional graph database implementations. The core innovation lies in its hybrid architecture that combines multiple data storage paradigms rather than relying on a single graph database engine.
Data Model Separation
The system separates edge connections from edge properties, a design decision that enables more efficient storage and querying patterns. Edge connections represent the fundamental relationships between nodes, while edge properties contain the metadata and attributes associated with those relationships. This separation allows for more optimized storage layouts and query patterns, as connection data can be stored in highly compact formats while properties can be accessed selectively based on query requirements.
Key-Value Foundation
By building on top of a Key Value abstraction rather than a traditional graph database, Netflix achieves several advantages. Key-value stores typically offer superior performance characteristics for simple lookups and updates, which aligns well with the system's focus on predictable, low-latency operations. The Key Value layer serves as the primary storage for the current graph state, providing fast access to the most recent data.
Time Series Integration
The integration with TimeSeries abstraction enables the system to maintain historical graph states without compromising the performance of real-time operations. This temporal dimension is crucial for many operational use cases, such as incident analysis where understanding how service dependencies have evolved over time can be critical for root cause determination. The TimeSeries layer captures changes incrementally, allowing for efficient storage of historical data while maintaining the ability to reconstruct past graph states when needed.
Caching Strategy
The dual caching approach—write-aside and read-aside—addresses different performance challenges. Write-aside caching prevents duplicate edge writes by maintaining a cache of recently written edges, reducing write amplification and ensuring consistency. Read-aside caching accelerates access to node and edge properties by keeping frequently accessed data in memory, dramatically reducing latency for common query patterns.
Schema Enforcement
Strict schema enforcement represents another key architectural decision. By loading graph schemas into memory and validating all operations against these schemas, the system can eliminate invalid query paths before execution, optimize traversal planning, and ensure data consistency. This approach trades some flexibility for significant performance gains and reliability improvements.
Performance Characteristics
The performance metrics achieved by Graph Abstraction are particularly impressive given the scale of data involved. Single-digit millisecond latency for single-hop traversals and sub-50-millisecond latency for two-hop queries at the 90th percentile represent exceptional performance for a system handling 650TB of data.
Latency Breakdown
Single-hop traversals benefit from the system's optimized data structures and caching strategies. Since these operations typically involve direct neighbor lookups, the combination of in-memory schemas and distributed caching enables extremely fast responses. The system's ability to predict and optimize these common query patterns contributes significantly to the achieved latency figures.
Two-hop traversals are more complex, involving multiple lookup operations and potentially larger result sets. The 90th percentile figure of under 50 milliseconds demonstrates the system's ability to handle more complex queries while maintaining predictable performance. This level of consistency is crucial for operational workloads where timing guarantees are essential.
Throughput Considerations
The system's high-throughput design enables it to handle concurrent queries and updates without degradation in performance. This is particularly important for use cases like social graph analysis in Netflix Gaming, where multiple users may be querying relationship data simultaneously. The architecture's ability to scale horizontally through distributed caching and replication ensures that throughput can be maintained even under heavy load.
Global Availability and Consistency
Achieving global availability while maintaining acceptable consistency levels represents a significant engineering challenge. Netflix's approach uses asynchronous replication across regions, which provides eventual consistency while enabling high throughput and low latency.
Replication Strategy
The system replicates both caching layers and durable storage across regions, ensuring that data is available locally regardless of where queries originate. This geographic distribution reduces latency for users in different regions and provides resilience against regional outages. The asynchronous nature of replication means that updates may take some time to propagate across all regions, but this trade-off is acceptable for many of the system's use cases.
Consistency Model
The eventual consistency model chosen by Netflix represents a pragmatic approach to the CAP theorem trade-offs. For many operational and analytical use cases, immediate consistency is less critical than availability and performance. The system's design ensures that users can always access data, even if it may be slightly stale in some regions.
API Design and Query Language
The gRPC traversal API inspired by Gremlin provides a familiar interface for developers while being optimized for the system's specific capabilities and limitations. The API enables chaining of traversal steps, application of filters, and result limiting, providing sufficient expressiveness for most use cases while maintaining the performance characteristics that make the system valuable.
Traversal Planning
The system's approach to traversal planning is particularly noteworthy. By analyzing query patterns against the in-memory schema and available data structures, the system can optimize execution paths before actually performing any operations. This pre-planning phase can eliminate unnecessary operations, choose the most efficient data access patterns, and provide accurate performance estimates.
Query Restrictions
The deliberate restrictions on traversal depth and the requirement for defined starting nodes represent conscious trade-offs that enable the system's performance characteristics. While these limitations mean that some complex graph queries may not be possible, they allow the system to guarantee predictable performance for the queries it does support.
Future Implications and Scalability
As Netflix continues to expand into new areas like live content, gaming, and advertising, the Graph Abstraction system is positioned to handle increasingly complex relationship modeling requirements. The architecture's ability to scale horizontally through distributed caching and replication suggests that it can accommodate growing data volumes and query loads.
Vertical Expansion
The system's current use cases in social graphs, service topology, and distributed systems monitoring demonstrate its versatility. As Netflix develops new services and features, the Graph Abstraction platform can likely be extended to model new types of relationships and support new analytical capabilities without requiring fundamental architectural changes.
Horizontal Scaling
The distributed nature of the system, with its regional replication and caching strategies, provides a clear path for horizontal scaling. As data volumes grow or query loads increase, additional regions and caching nodes can be added to maintain performance characteristics. The system's design appears to accommodate this type of scaling without requiring significant rearchitecture.
Comparison with Traditional Graph Databases
Graph Abstraction represents a fundamentally different approach to graph data management compared to traditional graph databases like Neo4j, Amazon Neptune, or TigerGraph. While those systems prioritize query flexibility and complex traversal capabilities, Graph Abstraction optimizes for predictable performance and operational use cases.
Trade-off Analysis
The trade-offs made by Netflix are appropriate for their specific use cases but may not be suitable for all graph processing needs. Organizations requiring complex, ad-hoc graph queries with deep traversals would likely find Graph Abstraction too restrictive. However, for operational workloads requiring consistent, low-latency access to graph data, the system's approach offers compelling advantages.
Performance Comparison
Traditional graph databases often struggle to maintain consistent performance as data volumes grow, particularly for complex queries. Graph Abstraction's focus on predictable performance through architectural constraints and optimization strategies enables it to deliver consistent results even at massive scale. The single-digit millisecond latencies achieved are exceptional for a system handling 650TB of data.
Implementation Considerations
Organizations considering similar approaches to graph data management should note several key implementation considerations based on Netflix's experience.
Infrastructure Requirements
The system's reliance on existing Netflix infrastructure like EVCache and their Key Value and TimeSeries abstractions means that organizations would need comparable infrastructure capabilities to implement a similar solution. The tight integration with these components is crucial to the system's performance characteristics.
Schema Management
The strict schema enforcement approach requires careful schema design and management processes. Changes to graph schemas can have significant implications for existing queries and applications, so schema evolution strategies would need to be carefully considered.
Caching Strategy
The effectiveness of the write-aside and read-aside caching strategies depends heavily on access patterns and data characteristics. Organizations would need to analyze their specific use cases to determine whether similar caching approaches would provide comparable benefits.
Conclusion
Netflix's Graph Abstraction system represents an innovative approach to handling massive-scale graph data that prioritizes predictable performance over query flexibility. By building on existing infrastructure, implementing strategic data model separations, and making conscious trade-offs around query capabilities, the system achieves exceptional performance characteristics that enable new operational capabilities across Netflix's platform.
The system's success demonstrates that for many real-world graph processing needs, the traditional graph database approach may not be optimal. Instead, carefully architected solutions that leverage existing infrastructure and make appropriate trade-offs can provide superior performance and reliability for specific use cases.
As organizations continue to grapple with graph data at scale, the principles and approaches demonstrated by Netflix's Graph Abstraction system offer valuable insights into how to achieve predictable, high-performance graph processing in production environments.
Comments
Please log in or register to join the discussion