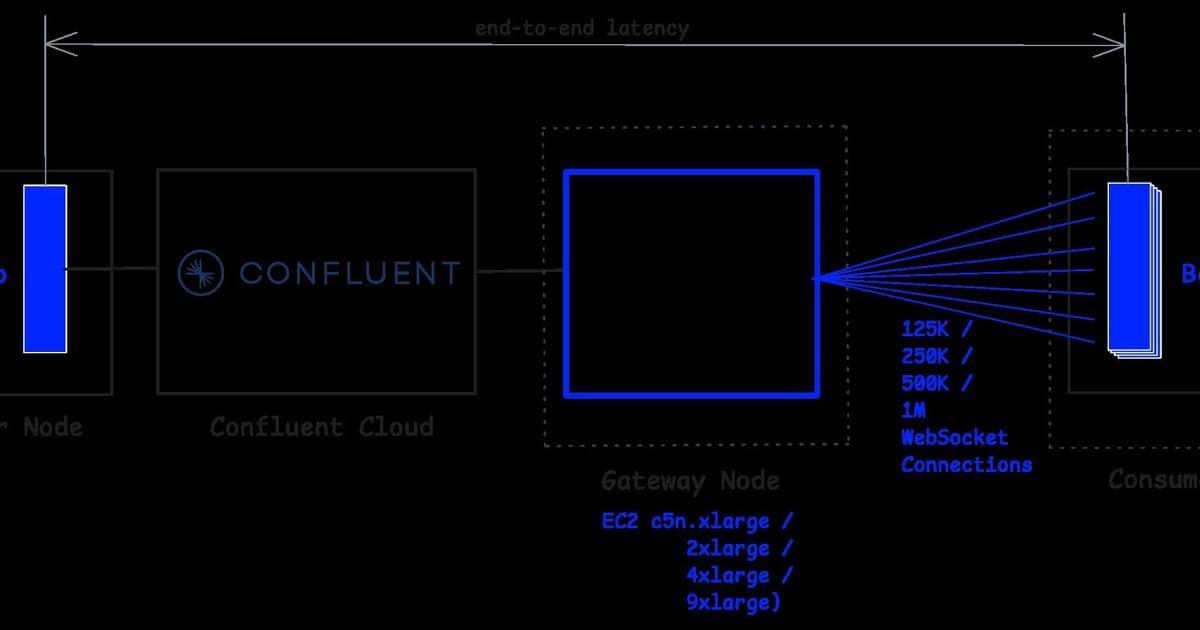
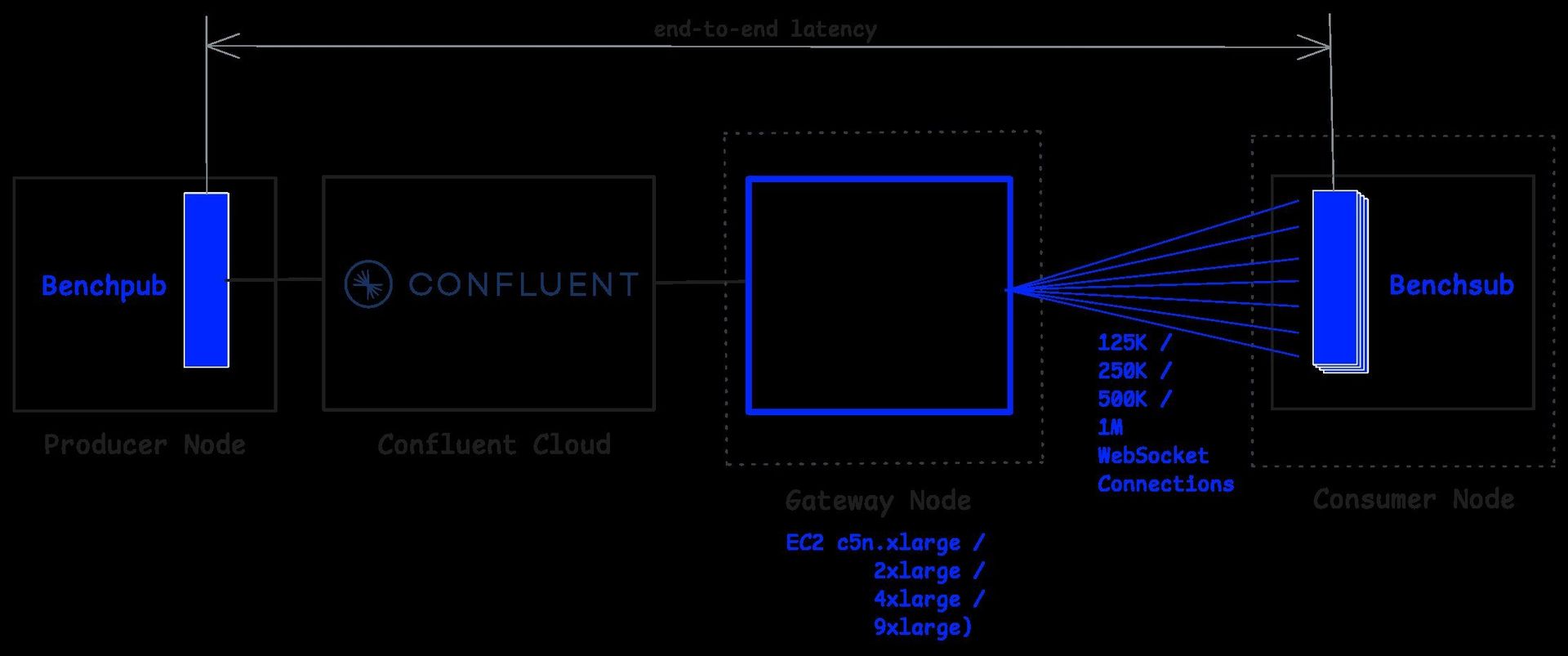
In a new benchmark, Kafkorama demonstrates that moving from a single Kafka broker to Confluent Cloud increases end-to-end latency by only 2-3 milliseconds while maintaining its ability to deliver 1 million messages per second to 1 million concurrent WebSocket clients.
Kafkorama Maintains Million-Message Performance with Confluent Cloud, Adding Just Milliseconds to Latency
In the world of real-time data streaming, performance metrics can make or break user experiences. When previous benchmarks showed Kafkorama delivering 1 million messages per second to 1 million WebSocket clients with a median end-to-end latency of just 3 milliseconds, it raised eyebrows. Now, the team has taken their testing further, replacing the single-node Kafka setup with Confluent Cloud—a production-ready managed service—and found that the performance impact is minimal at best.
Bridging the Gap Between Kafka and Real-Time Applications
Kafka has become the backbone of countless real-time data pipelines, but its native interface requires specialized knowledge of partitions, offsets, and consumer groups—typically limiting its use to backend services. Kafkorama aims to democratize this powerful technology by exposing Kafka data through familiar Streaming API endpoints.
"Kafkorama removes this barrier by exposing the same real-time data as Streaming APIs—enabling any developer to go beyond backend services and build real-time web, mobile, and IoT apps," explains the team behind the technology.
The architecture consists of three main components:
- Kafkorama Gateway - The core streaming engine that handles WebSocket connections and message routing
- Kafkorama Portal - A management layer for defining, documenting, and securing Streaming APIs
- Kafkorama SDKs - Lightweight client libraries for major programming languages and platforms
Each Streaming API endpoint follows the simple pattern /t/k, directly mapping to a Kafka topic t and key k. This abstraction allows developers to interact with Kafka data using standard PUB/SUB operations over persistent WebSocket connections, without needing to understand Kafka's internal mechanics.
A Production-Ready Reality Check
The initial benchmark deliberately used a single Apache Kafka® broker to isolate and measure Kafkorama's raw performance. However, in production environments, Kafka's replication, durability, and retention guarantees—typically provided by managed services like Confluent Cloud—are essential.
"In this blog post, we rerun the benchmark using the same setup, scenario, and benchmark tests, but replacing the single Kafka broker with Confluent Cloud," the team states. "We demonstrate that switching to this production-ready Kafka service increases end-to-end latency by only 2-3 milliseconds (2 ms at median, 3 ms at the 75th percentile), while maintaining the same level of latency stability."
The benchmark scenario remained consistent:
- 10,000 endpoints mapping to a Kafka topic with 10,000 keys
- Each key updated once per second
- Clients subscribing to random endpoints
- 512-byte message payloads
The Results: Minimal Impact, Maximum Assurance
When comparing the single-broker setup to Confluent Cloud, the results were strikingly similar:
"The only small difference appears in end-to-end latency: the median increases by 2 milliseconds, and the 75th percentile increases by 3 milliseconds. This slight increase—which reflects Confluent Cloud's replication, durability, and the additional network hops of a managed Kafka service—is consistent across all benchmark tests, which means overall latency remains perfectly stable."
This 2-3 millisecond increase is a small price to pay for the production-ready features that Confluent Cloud provides, including automatic replication, failover, and operational simplicity.
Scaling in All Directions
Beyond the latency comparison, the benchmark also thoroughly validated Kafkorama's scalability characteristics. Starting with a c5n.xlarge instance supporting 125,000 clients, the team demonstrated linear vertical scalability by doubling hardware capacity at each step:
- c5n.xlarge: 125,000 clients
- c5n.2xlarge: 250,000 clients
- c5n.4xlarge: 500,000 clients
- c5n.9xlarge: 1,000,000 clients
{{IMAGE:2}}
This linear scaling pattern held true across all tests, with each doubling of hardware resources resulting in a proportional increase in both concurrent users and message throughput.
The team also validated horizontal scalability by deploying a cluster of four Kafkorama Gateway instances on separate c5n.2xlarge nodes. This configuration successfully supported 1 million concurrent clients while processing 1 million messages per second, confirming that Kafkorama scales linearly in both vertical and horizontal dimensions.
Implications for Real-Time Application Development
For organizations considering real-time applications at scale, these results offer several important insights:
Managed Services Needn't Compromise Performance: The minimal latency increase when moving from a single broker to Confluent Cloud demonstrates that managed services can provide production-ready features without sacrificing raw performance.
API Abstraction Works: Kafkorama's approach of exposing Kafka through familiar Streaming APIs successfully bridges the gap between specialized streaming infrastructure and general application development.
Resource Efficiency Matters: The linear vertical scalability means fewer machines are needed to achieve high throughput, reducing operational overhead and costs compared to solutions that require more nodes to reach similar scales.
Developer Experience is Key: By providing SDKs for major platforms and a management portal, Kafkorama lowers the barrier to entry for building real-time applications on Kafka.
The Path Forward
As real-time applications become increasingly common across industries, the ability to deliver data at scale with minimal latency will continue to be a critical differentiator. Kafkorama's benchmark results suggest that it's possible to have both the robustness of a managed streaming service and the performance of a specialized streaming gateway.
For developers and architects evaluating streaming technologies, these results provide valuable data points for making informed decisions about infrastructure choices. The availability of detailed benchmark configurations and results on GitHub further enables teams to validate these findings in their own environments.
"If you'd like to try these benchmarks on your own machines, you can replicate the results we've shared here or adapt the setup to test scalability for your own use case," the team concludes. "The configuration details, scripts, commands, and results are available in this GitHub repository."
As real-time data becomes increasingly central to digital experiences, technologies that can deliver both performance and operational simplicity will likely play an outsized role in shaping the next generation of applications.
Comments
Please log in or register to join the discussion