
LLMs and AI agents are challenging fundamental assumptions in cloud architecture, exposing limitations in our stateless compute paradigm and creating new challenges for system design.
For two decades, cloud-native architecture has operated on a simple premise: state belongs in databases, while compute remains stateless. When scaling, we either scale databases vertically (more powerful machines) or partition data and scale application servers horizontally (more boxes). Any request can hit any server, the load balancer remains indifferent, and the database serves as the single source of truth. This model has served us well until recently, when LLMs and AI agents began quietly violating these core assumptions, making traditional architectures increasingly difficult to work with.
The challenge manifests in three distinct ways that our current architecture wasn't designed to handle:
Long-running work: An agent performing a 10-minute task isn't a typical 'request'—it's an asynchronous process with a different lifecycle and durability profile.
Stateful compute: Agents maintain conversation context across multiple turns, process numerous tool calls, and rely on accumulated state that doesn't naturally fit into traditional database schemas.
Bi-directional interaction: Users want to observe agents as they 'think,' interrupt them, and redirect their focus—creating a conversational dynamic with a running process rather than simple query-response interactions.
Durable Execution as a Partial Solution
The industry's current response to these challenges comes in the form of durable execution frameworks like Temporal, Inngest, and Restate. These systems provide resilience for long-running processes, ensuring they can survive failures and resume execution.
However, durable execution only solves part of the problem. While it makes processes resilient, it doesn't address the fundamental interaction challenge. We're still operating under the assumption that our underlying architecture remains stateless beneath the durable execution layer.
The Routing Problem
The core issue lies in our fundamental routing primitives. HTTP, combined with load balancers and stateless servers, is designed to route to endpoints—not to specific processes. When a client needs to communicate with a particular process running within a durable execution framework, we face the same routing limitations that plagued earlier distributed systems.
The universal workaround has become polling: clients repeatedly query a database endpoint to retrieve updates from the durable execution process. This approach treats the database as a message bus—a pattern reminiscent of pre-message-queue systems. Polling introduces several familiar problems:
- Latency issues from polling frequency decisions
- Unnecessary database load
- Wasted requests
- Poor user experience for streaming scenarios
At its core, polling is what we do when we cannot address the specific process we want to communicate with. It's a workaround for a fundamental routing limitation.
Missing: A Fundamental Routing Primitive
Our 20-year-old architectural assumptions are breaking down. We've designed systems using this paradigm for so long that we've forgotten it was even a choice. What we're missing is a fundamental routing primitive that HTTP, load balancers, and stateless server designs cannot provide.
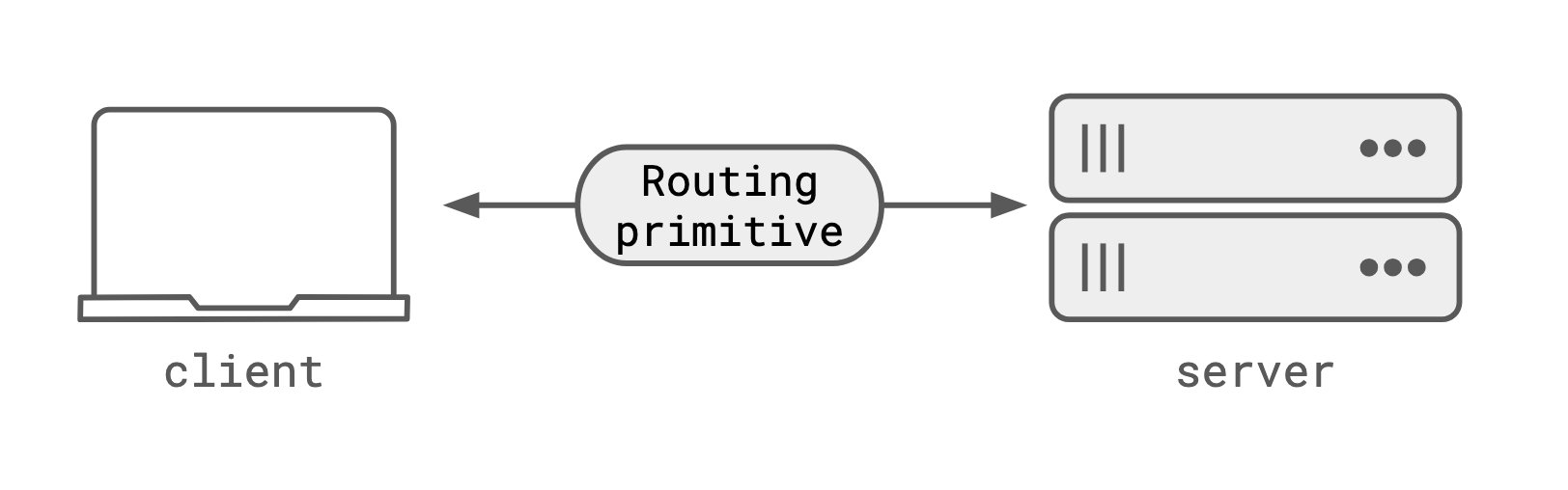
The solution isn't simply WebSockets. While WebSockets provide the necessary bi-directional, long-running connection, they represent a connection rather than an address. If a WebSocket connection drops, the 'address' is lost. There's no way to reconnect to the same process because there's no persistent address to route to.
Pub/Sub Channels as the Routing Primitive
The solution lies in pub/sub channels, which invert ownership of addressing. Neither the server process nor the client becomes directly addressable. Instead, the transport itself becomes addressable. Both client and server connect to a pub/sub channel by name, establishing bi-directional, stateful communication.
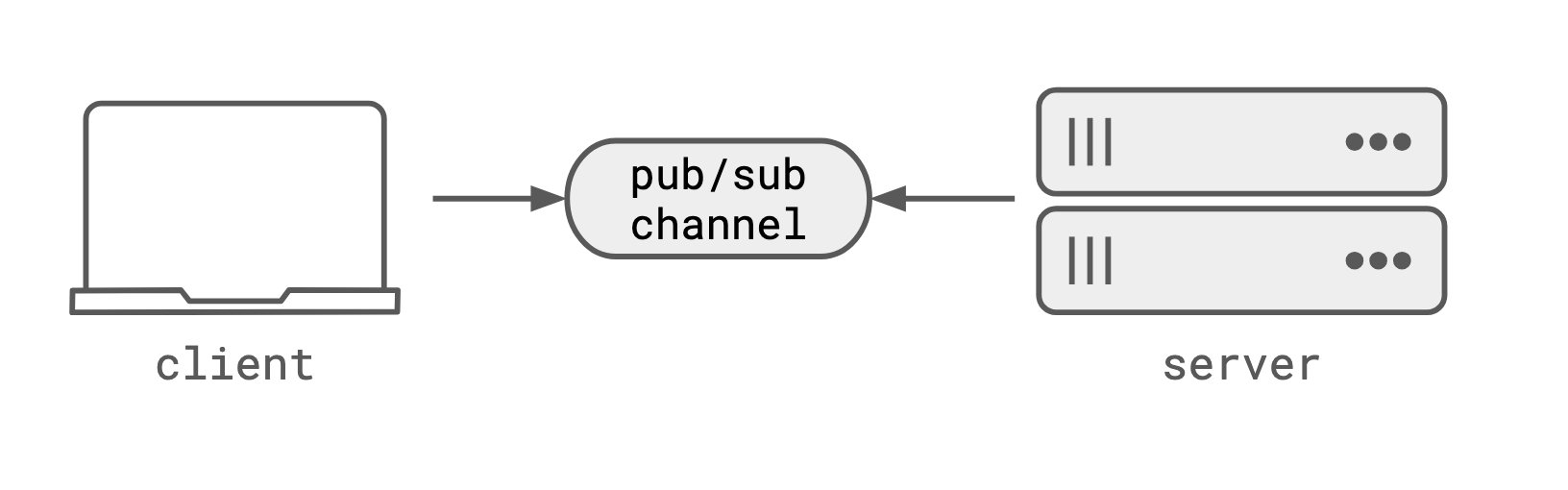
The channel itself serves as the address—unlike WebSockets, it's not a connection but a durable entity that can be disconnected from and reconnected to without losing data or the ability to route to the same process.
In practice, a durable workflow activity would connect to a pub/sub channel named after its workflow ID. The client would connect to the same channel to receive updates and send interrupt or steering messages. Both the workflow and the channel would be durable, allowing reconnection even if the workflow process or client connection drops.
This approach eliminates several architectural compromises:
- No need to thread data through a database
- No polling requirements
- No addressing challenges for durable processes
Why LLMs Make This Problem More Visible
While the architectural limitations existed before LLMs, these models make the constraints far more apparent. In traditional systems, if a connection dropped, requests were cheap enough to retry with reasonable expectation of deterministic results.
LLMs break this assumption in two critical ways:
Non-determinism: The same prompt can produce different outputs, making retries potentially problematic.
Cost: Token-based pricing means connection failures result in direct financial waste.
We don't want to waste tokens because a client entered a train tunnel, nor do we want to stream every token through a database simply to ensure resilience against connection issues. By being both non-deterministic and expensive, LLMs expose the limitations of our current architecture and make the trade-offs of HTTP + stateless server + load balancer + database significantly more painful.
Beyond LLMs: A New Architecture Paradigm
The stateless web paradigm isn't inherently wrong—it's simply not well-suited for agentic applications requiring long-running, stateful, interactive processes. What we need is a new architecture that includes a routing primitive capable of addressing processes directly, not just databases.
The emerging solution combines durable execution frameworks with pub/sub channels and stateless HTTP, allowing each component to perform its specialized role:
- Durable execution handles process resilience and state management
- Pub/sub channels provide the routing primitive for bi-directional communication
- Stateless HTTP continues to handle traditional request-response interactions
This hybrid approach acknowledges that different application patterns require different architectural solutions. As we build increasingly sophisticated AI systems, we need equally sophisticated infrastructure that can support their unique requirements without forcing them into outdated architectural molds.
Comments
Please log in or register to join the discussion