Message queues decouple producers and consumers, enabling asynchronous processing, fault tolerance, and elastic scaling. This article explains the core mechanics, walks through real‑world examples, and evaluates consistency guarantees, API designs, and the operational costs of adding a queue layer.
Message Queues: Why They Matter, How They Work, and What You Trade Off
The problem: tightly coupled services choke under load
In a monolithic API, a request thread often calls downstream services directly. If the downstream service is slow, overloaded, or temporarily unavailable, the caller blocks, the thread pool fills up, and the whole system stalls. This coupling makes it hard to guarantee response time SLAs during traffic spikes, and it forces developers to write complex retry and circuit‑breaker logic.
The solution approach: introduce an intermediate store
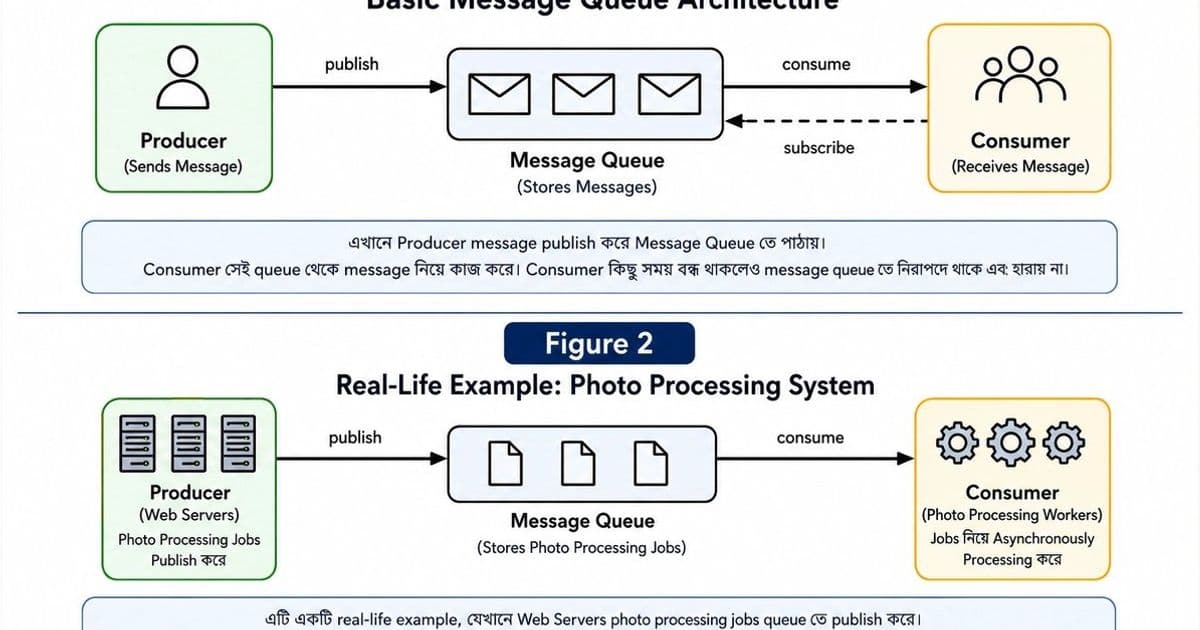
A message queue sits between a producer (the service that creates work) and a consumer (the worker that performs the work). The producer pushes a payload onto the queue and immediately returns, while the consumer pulls messages at its own pace. The queue persists the payload until a consumer acknowledges successful processing, providing durability and decoupling.
Core workflow
- Publish – The producer sends a message to the queue via a client library or HTTP endpoint.
- Store – The queue writes the message to durable storage (in‑memory, on‑disk, or replicated log).
- Deliver – One or more consumers fetch messages, process them, and acknowledge.
- Delete – Upon acknowledgment the queue removes the message; if the consumer crashes, the message is re‑queued for another consumer.
Real‑world illustration: food‑delivery ordering
- A customer places an order via the mobile app.
- The order service writes the order to the database and publishes a
NewOrderevent to the queue. - The restaurant service, which may be busy or temporarily offline, later pulls the event and begins preparation.
- If the restaurant service crashes before acknowledging, the queue redelivers the same event, guaranteeing the order is not lost.
This pattern eliminates the need for the order service to wait for the restaurant service to be ready, and it lets the restaurant scale its workers independently of the front‑end traffic.
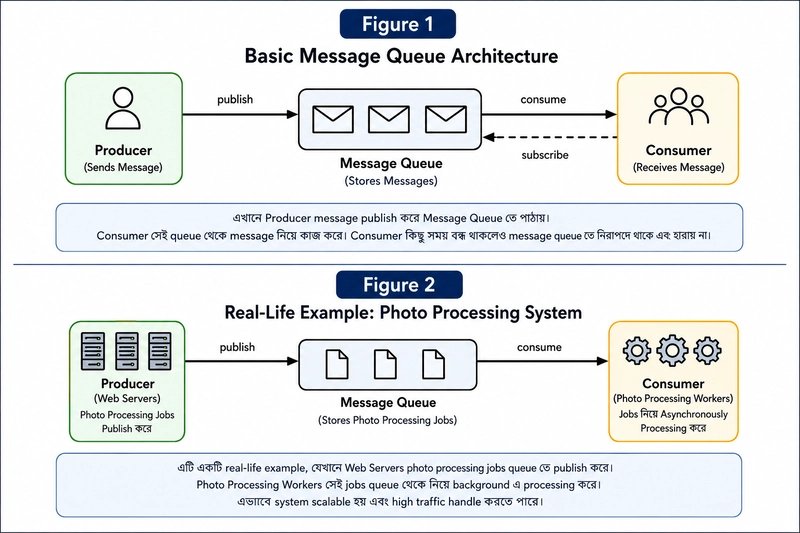
Example from the social‑media world
When a user uploads a photo, the web server quickly stores the original file and enqueues jobs such as:
- Resize to thumbnail
- Apply blur or sharpening
- Run face detection
Background workers consume these jobs, allowing the upload endpoint to stay fast. During a surge of uploads, you simply add more worker instances; when traffic drops, you scale them down.
Consistency models you need to understand
| Model | Guarantees | Typical queue implementations |
|---|---|---|
| At‑most‑once | A message is delivered zero or one time. Duplicate processing is impossible, but loss can happen if a consumer crashes after processing but before acknowledgment. | Simple in‑memory queues, some configurations of Amazon SQS. |
| At‑least‑once | A message is delivered one or more times. Consumers must be idempotent because duplicates may occur. | Most durable queues (RabbitMQ, Apache Kafka) default to this. |
| Exactly‑once | The system guarantees a single processing event. Achieving this requires transactional writes and idempotent consumers, often with deduplication tables. | Kafka with idempotent producers + transactional consumers, or specialized services like Azure Service Bus with duplicate detection. |
Choosing a model impacts how you design downstream services. If you cannot make your processing idempotent, you must stick with at‑most‑once and accept the risk of lost work.
API patterns for producers and consumers
Producer side
- Fire‑and‑forget HTTP POST – Simple but hides back‑pressure; useful for low‑risk events.
- Client library with confirm callbacks – The library returns a future that resolves when the broker acknowledges persistence (e.g.,
channel.publish(..., confirm=True)in RabbitMQ). - Batch publishing – Reduces network overhead when sending many small messages.
Consumer side
- Pull model – Workers call
receive()orpoll()on the queue. Gives the worker control over batch size and concurrency. - Push model (webhooks) – The broker pushes messages to an HTTP endpoint. Simpler for stateless services but can tie the consumer’s availability to the broker’s retry policy.
- Long‑running lease – The consumer obtains a lease on a message, processes it, then commits the lease. This pattern reduces the window where a crash could cause duplicate work.
Trade‑offs you will encounter
| Aspect | Benefit of adding a queue | Cost / complication |
|---|---|---|
| Scalability | Workers can be added or removed without touching producers. | You must monitor queue depth and tune prefetch limits to avoid back‑pressure. |
| Reliability | Messages survive consumer crashes; no data loss if the queue is durable. | Durable storage adds latency; you need to manage replication and disk usage. |
| Operational complexity | Decoupled services can be deployed independently. | You now run an extra component (RabbitMQ, Kafka, SQS, etc.) that requires capacity planning, security hardening, and upgrade paths. |
| Consistency | Guarantees about delivery order (FIFO, partition ordering) can be enforced. | Strict ordering may limit parallelism; some brokers sacrifice order for higher throughput. |
| Observability | Queue metrics (lag, dead‑letter count) give early warning of bottlenecks. | You must instrument producers and consumers to emit tracing IDs so you can follow a message across services. |
When a queue is not the right tool
- Ultra‑low latency: If the end‑to‑end latency budget is sub‑millisecond, the extra hop adds unacceptable delay.
- Simple request‑response: For CRUD operations where the caller needs an immediate result, a direct RPC call is clearer.
- Stateless pipelines: If the work can be expressed as a pure function without side effects, a functional stream may be more appropriate.
Getting started quickly
- Pick a broker that matches your consistency needs. For most web apps, RabbitMQ (at‑least‑once) or Amazon SQS (at‑most‑once) are easy to provision.
- Define a small schema for your messages (JSON with
type,payload,correlationId). - Implement a producer that publishes with confirmation and logs the
correlationId. - Write a consumer that processes messages idempotently and moves failed messages to a dead‑letter queue.
- Set up alerts on queue depth and dead‑letter rate.
Bottom line
Message queues give you a clean way to absorb traffic spikes, survive partial outages, and evolve services independently. The trade‑offs revolve around latency, operational overhead, and the consistency guarantees you must enforce in downstream code. By picking the right broker, designing idempotent consumers, and monitoring queue health, you can turn a brittle synchronous call chain into a resilient, elastic system.
For deeper dives, see the official RabbitMQ documentation, the Kafka design guide, and the AWS SQS best practices.
Comments
Please log in or register to join the discussion