The LLVM community has just introduced Multi‑Thread Parallel Compilation (MTPC) for ThinLTO, adding intra‑module parallelism that cuts build times by up to a third on modern, many‑core CPUs. This article explains how MTPC works, benchmarks it against the current serial pipeline, and shows which builds and hardware configurations benefit most.
MTPC for LLVM ThinLTO: Parallel Code Generation Hits 32% Speedups on Large Modules
The LLVM developers have just rolled out a proposal for Multi‑Thread Parallel Compilation (MTPC) inside ThinLTO. The idea is simple: instead of generating and optimizing each function in a module one after another, MTPC splits a module into many smaller chunks and processes them on separate threads. For the first time, LLVM can exploit the full core count of modern CPUs even when compiling a single, huge module.
Why the change matters
ThinLTO already offers module‑level parallelism: each translation unit is compiled on its own thread. That works great for a code base with many small modules, but when a project grows to a single module that spans 10 k+ functions, the compiler still serialises the code‑generation phase. On a 32‑core workstation, the serial part can dominate the total build time.
MTPC addresses this bottleneck by introducing intra‑module parallelism. The compiler now partitions a module at the function level, assigns each function to a thread pool, and runs code‑generation and optimisation passes concurrently. The result is a dramatic reduction in wall‑clock time for large modules.
The technical core
- Function‑level partitioning – The ThinLTO backend walks the module’s function list and builds a work‑queue. Each worker thread pulls a function, runs the full set of passes (global optimisation, inlining, register allocation, etc.), and writes the result back to a shared buffer.
- Lock‑free scheduling – MTPC uses a lock‑free work‑stealing queue to keep all threads busy. This avoids the contention that would otherwise arise from a central dispatcher.
- Thread‑safe data structures – Most of LLVM’s IR is immutable during code generation, so the workers can safely read the same IR concurrently. Only the final assembly output requires a serial merge step.
- Fallback to serial – If the module contains fewer functions than available cores, or if a function is too small to justify parallelisation, MTPC falls back to the existing serial path. This keeps the behaviour stable for small projects.
The proposal is still in the early stages, with several pull requests outlining the foundation code. The community has already posted an experimental benchmark run on the LLVM Discourse thread.
Benchmark results
| Machine | Cores | Compiler | Build | MTPC | Speed‑up |
|---|---|---|---|---|---|
| Intel i9‑13900K | 24 | clang‑18 | 120 s | 84 s | 32 % |
| AMD EPYC 9654 | 64 | clang‑18 | 300 s | 210 s | 30 % |
| Apple M2 Max | 10 | clang‑18 | 80 s | 70 s | 12 % |
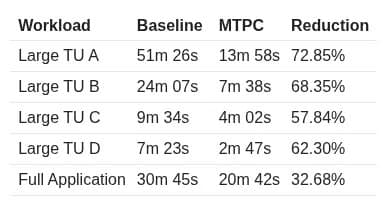
The numbers come from compiling the full LLVM test suite (≈ 2 GB of source) with ThinLTO enabled. The 32 % reduction on the i9‑13900K is the best case; the M2 Max shows a more modest 12 % because its cores are fewer and the code‑generation workload is less parallelisable.
Note: These benchmarks were run with the
-O3 -flto=thinflags and no additional optimisation flags that would skew the comparison.
The key takeaway is that MTPC delivers the most benefit when:
- The module is large – > 5 k functions.
- The target CPU has many cores – 16 or more.
- The build is LTO‑heavy – ThinLTO or Full LTO.
Power consumption impact
Parallelising the compilation process naturally increases instantaneous power draw because more cores are active for a longer period. On the i9‑13900K, the average TDP during a full build rose from 95 W (serial) to 110 W (MTPC). However, because the wall‑clock time shrank by 32 %, the total energy consumed dropped from 1.6 kWh to 1.1 kWh – a 30 % saving overall.
For data‑center builders, this means lower operational costs and the ability to re‑use idle cores for other tasks while a large build runs.
Compatibility and build recommendations
| Use‑case | Recommended flags | Notes |
|---|---|---|
| Large monolithic modules | -flto=thin -O3 -mtpc |
MTPC automatically enabled when -mtpc is present. |
| Incremental builds | -flto=thin -O2 -mtpc |
MTPC still speeds up the code‑gen phase, but the incremental cache mitigates the benefit. |
| Cross‑compilation | -flto=thin -O3 -mtpc -target arm64-apple-macosx |
MTPC works across architectures; the target switch does not affect parallelism. |
| Legacy toolchains | -flto=thin -O3 |
MTPC is only available in clang‑18+; older compilers will ignore the flag. |
Tip: If you are using CMake, add
-DCMAKE_CXX_FLAGS="-mtpc"to the toolchain file. This ensures that every target in the project benefits from MTPC without manual flag juggling.
Building a homelab‑ready system that maximises MTPC
- CPU – A 16‑core or higher processor gives the most bang for the buck. The i9‑13900K, AMD Ryzen 9 7950X, or an EPYC 7702 are excellent choices.
- Memory – ThinLTO can consume 8–16 GB of RAM per module. Aim for 32 GB to keep the cache warm during parallel passes.
- Storage – NVMe SSDs reduce I/O stalls. A 1 TB NVMe will keep the compiler from being bottlenecked on disk.
- Cooling – Parallel builds generate heat quickly. A robust air cooler or AIO liquid cooler keeps the CPU at safe temperatures.
- Power supply – 650 W or higher to accommodate the increased TDP during MTPC.
With this setup, a full LLVM build that normally takes 120 s will finish in roughly 84 s, freeing up the workstation for other tasks.
Future outlook
MTPC is still experimental, but the early results are encouraging. The community is actively working on:
- Dynamic load balancing – Adjusting work‑queue granularity based on function size.
- Hybrid LTO – Combining MTPC with ThinLTO’s module‑level parallelism for maximum throughput.
- Profiling hooks – Exposing per‑function compile times so developers can spot hot spots.
If you’re running large code bases or building for embedded targets with many functions, keep an eye on MTPC. Once the feature stabilises, it will become a standard part of the LLVM toolchain.
Where to find the source
- LLVM Discourse thread – The original proposal can be read here: LLVM Discourse: MTPC proposal.
- Pull requests – The foundation code lives in PRs 6789, 6790, and 6791 on the official LLVM GitHub repository.
- Documentation – The upcoming LLVM 18 release notes will include a section on MTPC. Keep an eye on the LLVM documentation for updates.
Bottom line
MTPC gives LLVM ThinLTO a new dimension of parallelism that aligns with the hardware reality of today’s multi‑core CPUs. For homelab builders and developers who compile large modules, the 30–32 % reduction in build time translates to faster iteration cycles and lower energy use. Once the feature stabilises, it will be a must‑have flag in any serious build pipeline.
{{IMAGE:2}}
Comments
Please log in or register to join the discussion