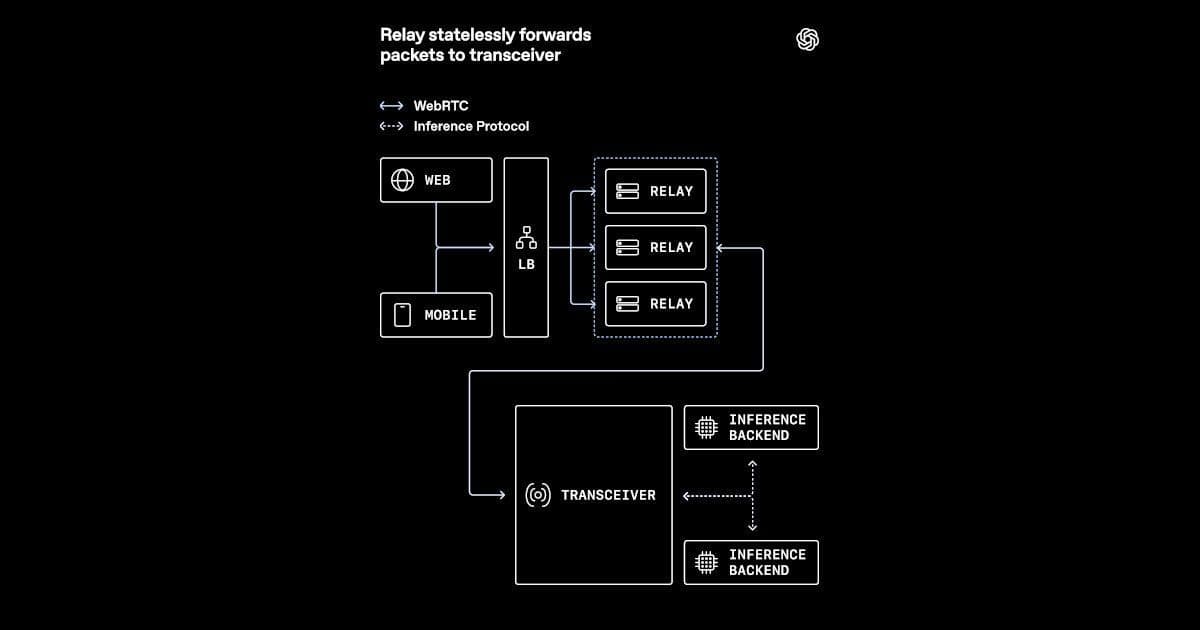
OpenAI replaces a traditional media termination model with a relay‑transceiver architecture for real‑time voice AI. The split keeps WebRTC state in a single transceiver service while lightweight relays handle packet forwarding, easing Kubernetes deployment, reducing public UDP exposure, and improving round‑trip times for 1:1 user‑model interactions.
What changed
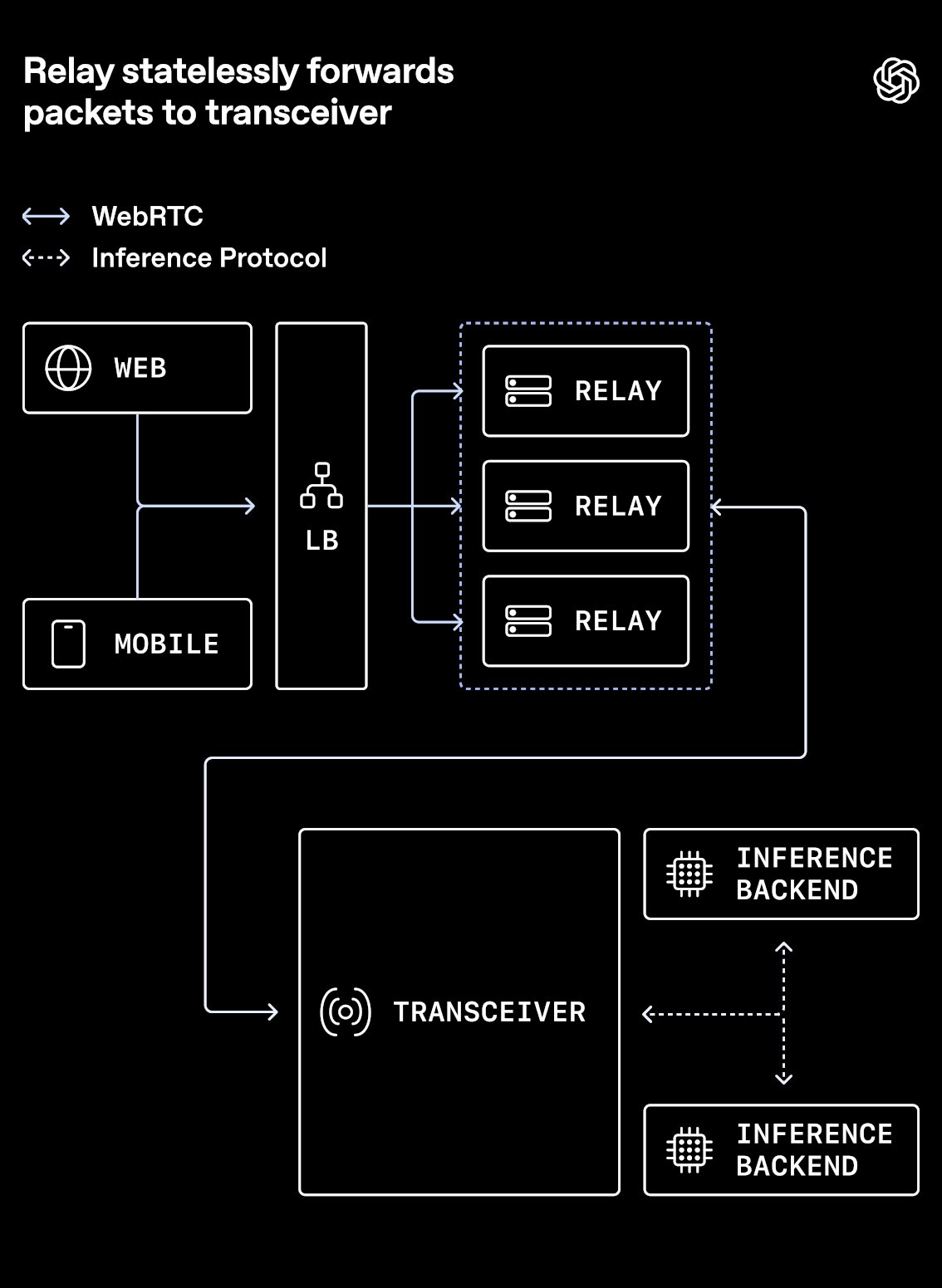
OpenAI announced a new WebRTC deployment pattern that moves the heavy‑weight parts of the protocol—ICE negotiation, DTLS handshakes, SRTP encryption—into a dedicated transceiver service. A thin relay layer sits in front of the transceiver, accepting inbound UDP packets and forwarding them with minimal processing. This contrasts with the classic model where each media server terminates the full WebRTC stack and exposes a large range of public UDP ports.
The shift was driven by three operational constraints:
- Global reach – users connect from dozens of regions, requiring a routing layer that can sit close to the edge.
- Fast connection setup – voice assistants must start speaking within a few hundred milliseconds.
- Stable, low media RTT – any jitter directly degrades the conversational experience.
By decoupling stateful protocol handling from packet forwarding, OpenAI can scale the relay horizontally behind cloud load balancers, while the transceiver remains a single, well‑instrumented component.
Provider comparison
| Aspect | Traditional SFU / TURN model | OpenAI relay‑transceiver model |
|---|---|---|
| Port management | Requires allocating a wide public UDP range per pod; Kubernetes NetworkPolicies become complex. | Relays listen on a small, fixed port range; transceiver uses a single internal endpoint. |
| Scaling | Each SFU instance must carry full WebRTC stack; scaling adds protocol overhead. | Relays are stateless, can be autoscaled with a standard Horizontal Pod Autoscaler; transceiver scales independently based on session count. |
| Cloud‑load‑balancer compatibility | Many cloud LB services struggle with UDP affinity and long‑lived connections. | UDP traffic terminates at the relay, which is a simple L4 service; standard LB health checks work out‑of‑box. |
| Provider‑specific costs | High egress bandwidth on public IPs; potential data‑transfer surcharge on AWS/NVIDIA/Google edge nodes. | Relays can be placed on cheaper edge compute (e.g., Cloudflare Workers, Azure Front Door) while the transceiver runs on reserved instances in a single region, reducing cross‑region traffic. |
| Operational risk | Port‑exhaustion attacks, NAT‑traversal failures, complex firewall rules. | Only the relay surface is exposed; attacks are limited to a thin stateless layer that can be DDoS‑mitigated with standard cloud WAFs. |
Why the split matters for major clouds
- AWS – Elastic Load Balancing supports UDP but does not provide sticky session semantics needed for per‑session ICE. The relay‑transceiver pattern lets you keep the UDP endpoint behind an NLB, while the transceiver lives behind a private ALB with HTTP/2 health checks.
- Google Cloud – Traffic Director can route UDP at the edge, but its firewall rules are coarse‑grained. By funneling traffic through a relay, you can apply Cloud Armor policies to the relay only, keeping the transceiver insulated from external traffic.
- Azure – Azure Front Door now offers UDP preview; the relay can be deployed as a Front Door endpoint, leveraging its global PoP network, while the transceiver runs on Azure VM Scale Sets in a single region.
Business impact
Faster time‑to‑market for voice‑first products
Developers building on the OpenAI Realtime API can now rely on a predictable latency envelope (< 80 ms median RTT) because the relay sits in the same edge location as the user. This reduces the need for custom client‑side jitter buffers and simplifies SDK logic.
Lower operational expenditure
By collapsing many per‑pod UDP allocations into a handful of relays, OpenAI cuts the number of public IPs required. Cloud providers charge per‑GB of outbound traffic; keeping most traffic inside the provider’s private network (relay → transceiver) reduces billable egress.
Improved security posture
Only the relay is internet‑facing, allowing a unified security policy (e.g., rate limiting, IP reputation checks). The transceiver never sees raw client IPs, which mitigates exposure to port‑scanning attacks and simplifies compliance audits (PCI‑DSS, GDPR).
Migration considerations for existing customers
If you already run an SFU‑based voice AI stack, the migration path involves:
- Deploying the OpenAI‑style relay as a Kubernetes DaemonSet on edge nodes.
- Pointing existing clients to the relay’s public address (no SDK change needed).
- Gradually routing sessions to the new transceiver via a feature flag.
- Decommissioning legacy SFU pods once traffic stabilises.
The approach works best for 1:1 conversational use cases. Teams that need multi‑party conferencing should still evaluate a full SFU or MCU, but can adopt the relay‑transceiver pattern for the audio‑only leg of the call to reap the same scaling benefits.
Takeaway for architects
The core lesson is to keep protocol complexity in a single, well‑instrumented service while pushing routing logic to a thin, stateless layer that can be duplicated across edge locations. This design aligns with how modern cloud load balancers and Kubernetes networking are evolving, and it offers a clear cost and security advantage for large‑scale voice AI deployments.
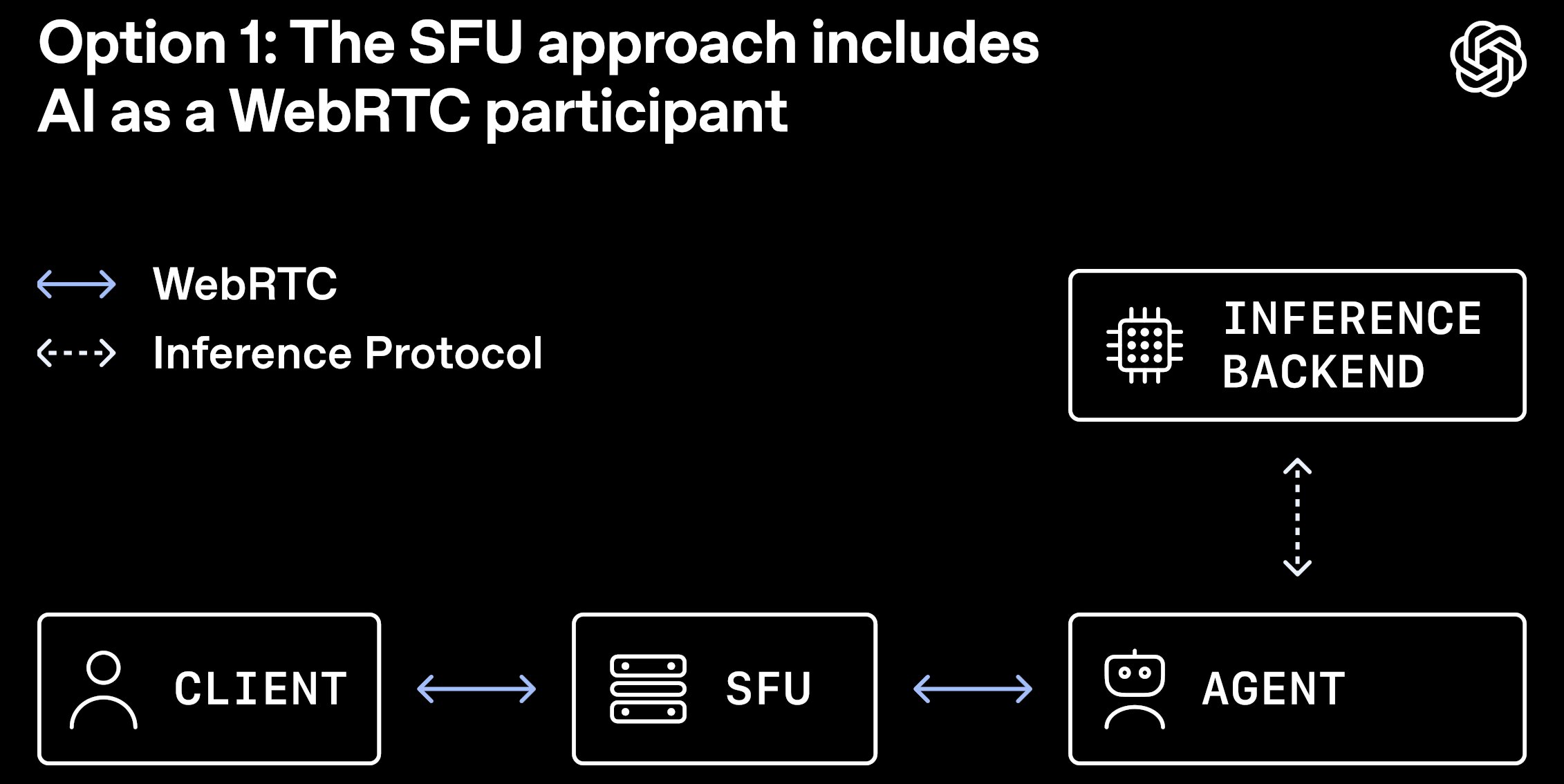
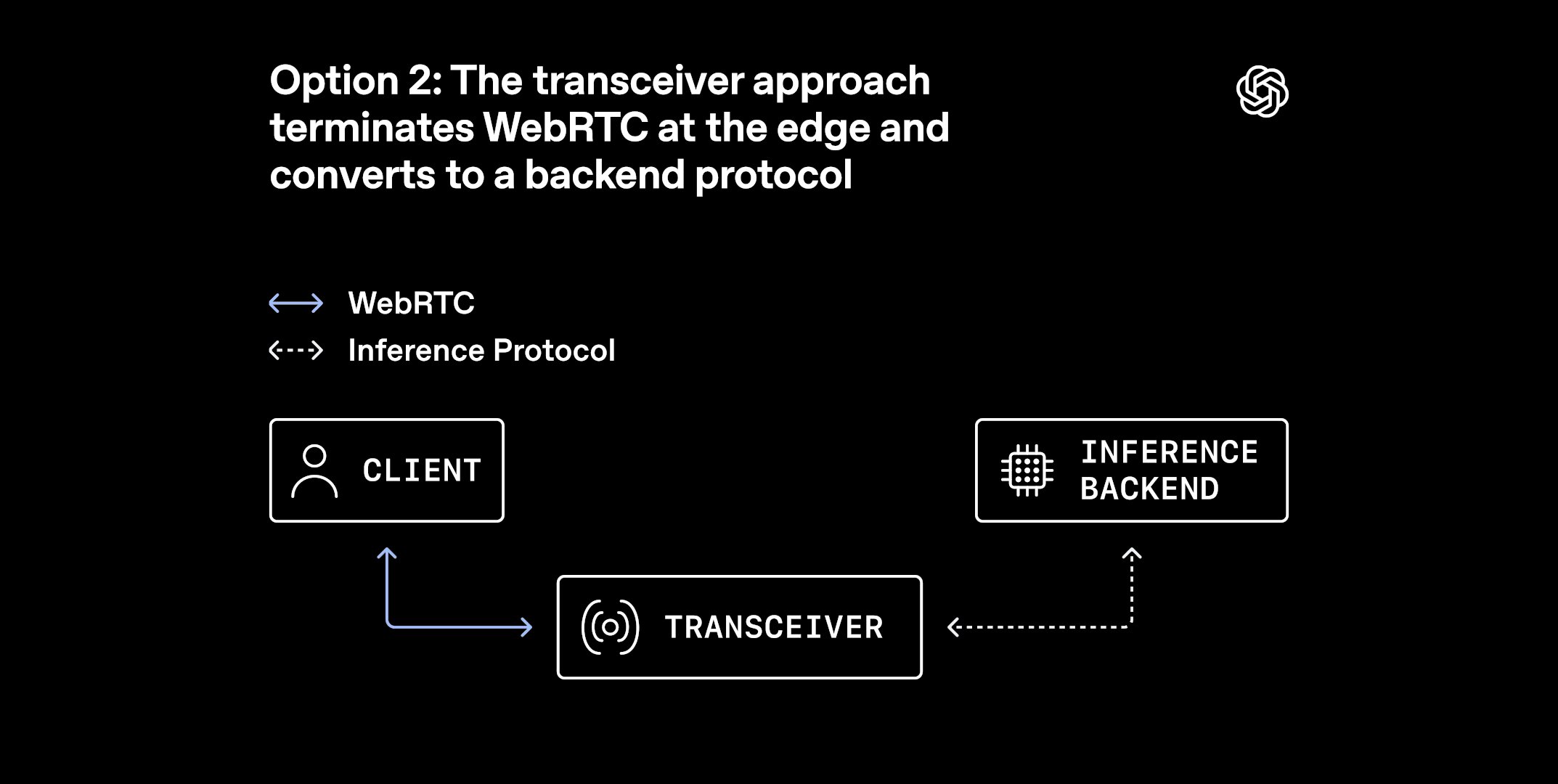
Author: Eran Staller, Chief Software Architect at Cartesian
Comments
Please log in or register to join the discussion