An exploration of how PostgreSQL's storage inefficiencies waste 94% of CPU cache bandwidth, and why the PAX page format could dramatically improve performance without sacrificing transactional capabilities.
For decades, PostgreSQL's storage engine has silently suffered from a fundamental inefficiency that squanders precious CPU cache resources. The traditional N-ary Storage Model (NSM), while simple and effective for transactional operations, forces the database to load entire rows into cache memory when only a single column is needed. This architectural choice results in staggering inefficiencies where up to 94% of cache bandwidth is wasted during common operations—a problem exacerbated by modern hardware with wider cache lines.
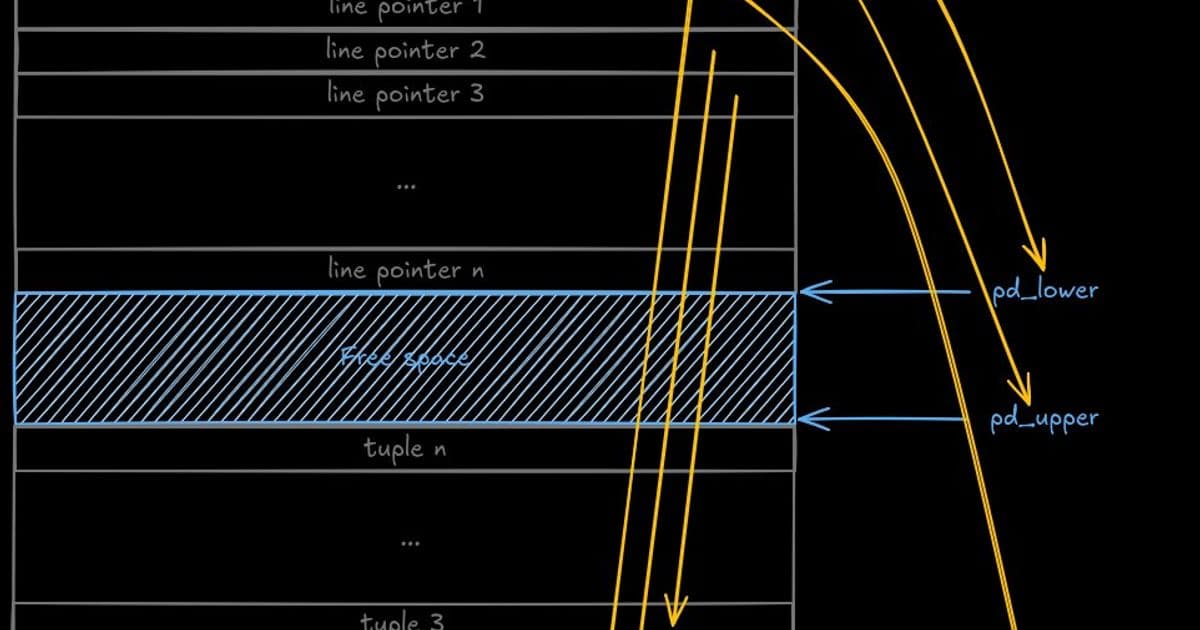
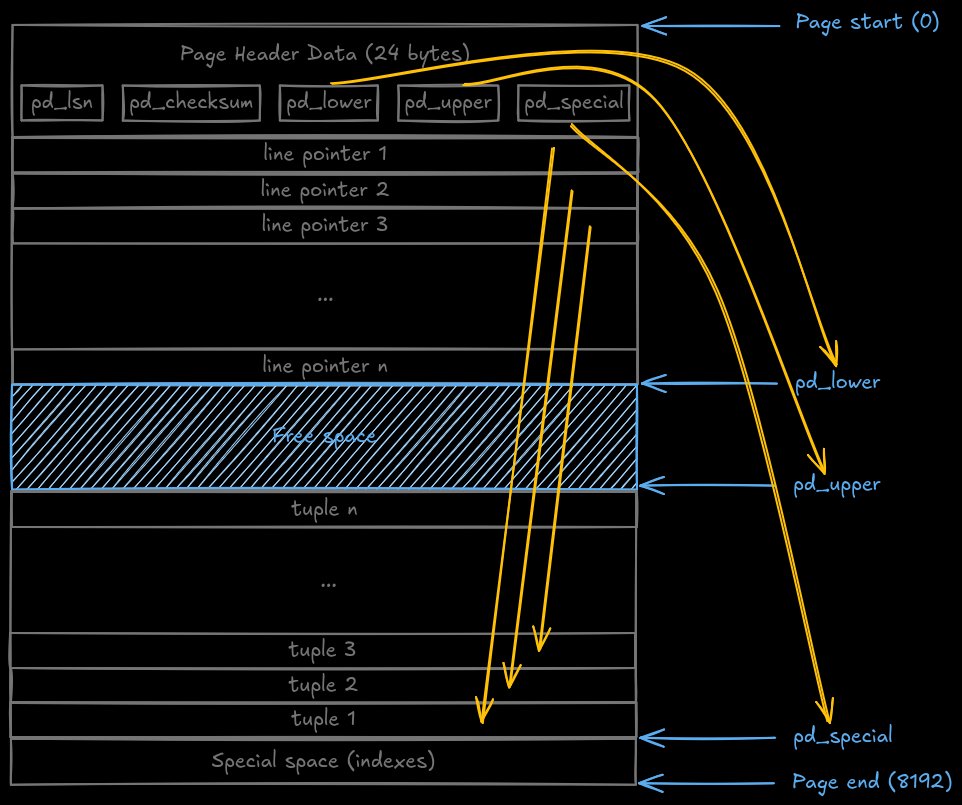 Structure of a PostgreSQL NSM page showing header, line pointers, tuples, and free space
Structure of a PostgreSQL NSM page showing header, line pointers, tuples, and free space
The core issue manifests when executing simple queries like SELECT age FROM users WHERE age > 30. While logically requesting just 4 bytes per row, PostgreSQL's physical storage forces the CPU to load entire tuples spanning multiple cache lines. Each 64-byte cache line might contain only one relevant value, surrounded by irrelevant columns. As illustrated below, this results in 94% cache pollution—loading 60 unnecessary bytes for every 4 useful bytes.
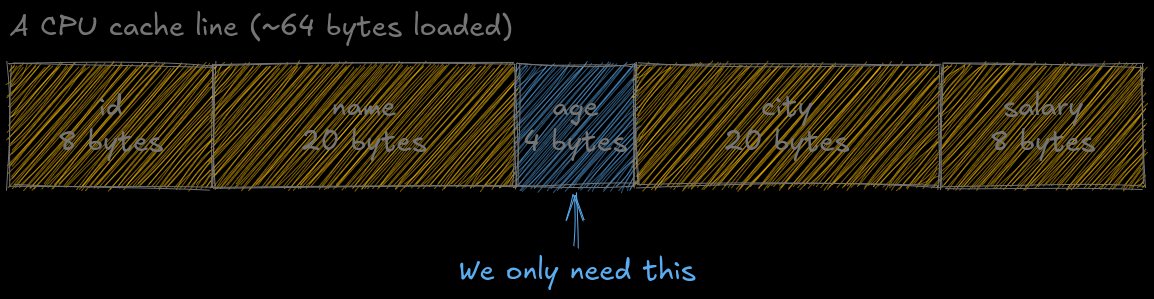 Cache line showing 94% waste when loading a single column
Cache line showing 94% waste when loading a single column
This inefficiency isn't theoretical. On a 1-million-row table scan, NSM triggers 1 million cache misses while transferring only 4MB of useful data, wasting 56MB of memory bandwidth. The problem intensifies with modern 128-byte cache lines, creating even greater waste. Remarkably, this flaw was quantified as early as 2001 by Anastasia Ailamaki's research, which found 75% of cache misses avoidable through alternative storage models.
The solution lies in PAX (Partition Attributes Across), a page format that maintains the physical proximity of rows while reorganizing data within each 8KB page. Instead of storing complete tuples contiguously, PAX vertically partitions columns into minipages—essentially creating a columnar organization within each traditional database page.
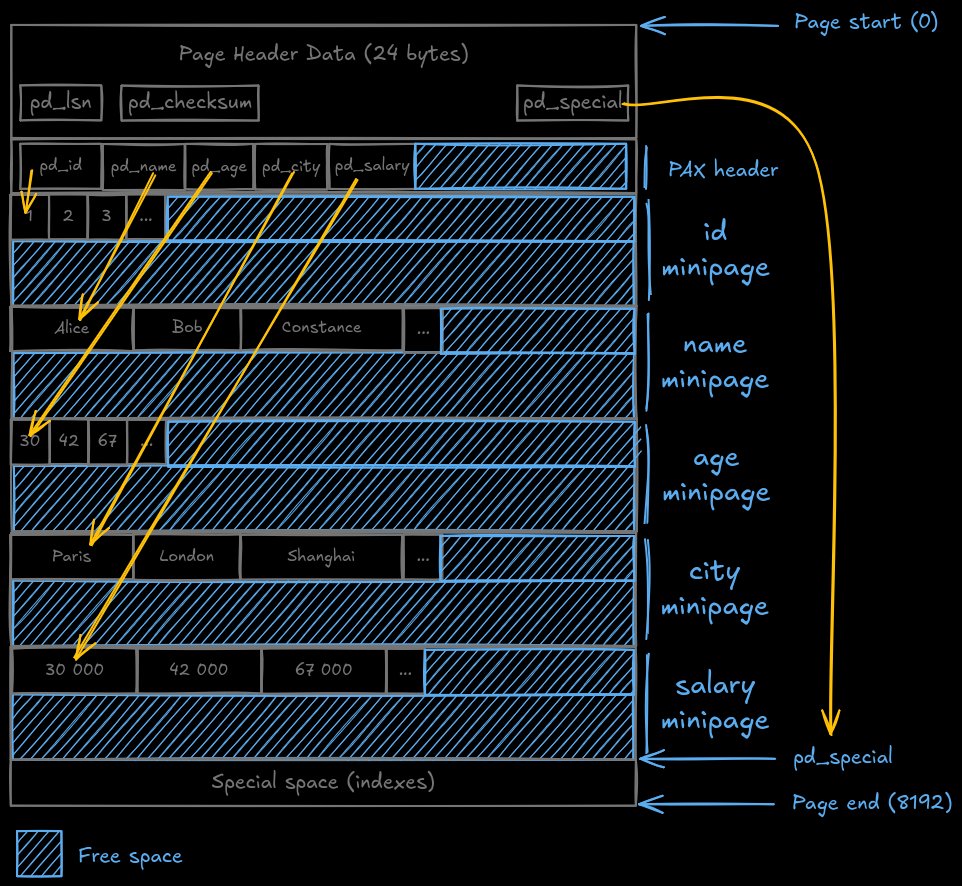 PAX page structure with column-oriented minipages
PAX page structure with column-oriented minipages
When querying a single column like age, PostgreSQL would access only the corresponding minipage rather than entire rows. This transformation fundamentally changes cache behavior. Where NSM loaded one value per cache line, PAX packs 16 values into the same 64-byte cache line—a 16x improvement in cache utilization.
 Cache line loading from PAX page showing 16 values
Cache line loading from PAX page showing 16 values
The practical implications are profound: scanning 100 rows for an age filter drops from 100 cache misses under NSM to just 7 under PAX—a 93% reduction. Crucially, this optimization occurs while preserving the page-level atomicity PostgreSQL requires for ACID transactions and MVCC, differentiating it from file-level columnar formats like Parquet.
Interestingly, Parquet's architecture directly descends from PAX research. While Ailamaki pioneered the page-level approach in 2001 for transactional databases, Twitter and Cloudera later scaled the concept to multi-megabyte row groups for data lakes. The critical distinction lies in mutability: PAX retains update capabilities within 8KB pages while Parquet's file-level implementation sacrifices mutability for compression benefits.
| Feature | PAX (Original) | Parquet | PostgreSQL Need |
|---|---|---|---|
| Granularity | Page (8KB) | Row group (128MB+) | Page (8KB) |
| Update Support | Yes | No | Yes |
| Environment | OLTP+OLAP DBMS | Data lakes | OLTP+OLAP DBMS |
| Compression | Limited | Advanced | Future option |
PAX shines brightest in specific scenarios:
- Wide tables (12+ columns) with selective queries accessing few columns
- Mixed OLTP/OLAP workloads requiring both point updates and analytical scans
- Frequent sequential scans with low projectivity (returning few columns)
Conversely, its advantages diminish for:
- Narrow tables (<8 columns) where reconstruction overhead negates benefits
- Full-table scans (
SELECT *) requiring all columns anyway - Index-heavy workloads where point lookups fetch entire rows
Historical benchmarks from Ailamaki's Pentium II-era research showed 75% fewer cache misses and 11-48% faster TPC-H queries. Modern extrapolations suggest even greater potential: DDR5 memory and NVMe storage have shifted bottlenecks from I/O to CPU cache efficiency. Conservative estimates indicate PAX could accelerate OLAP queries on wide tables by 10-30% with minimal impact on OLTP operations.
Implementation in PostgreSQL remains challenging—requiring reengineering of vacuum processes, WAL logging, and buffer management while preserving MVCC semantics. Dead tuple management would require per-minipage tracking rather than whole-page processing. Yet the potential rewards justify exploration: eliminating 94% cache pollution could fundamentally reshape PostgreSQL's performance profile for data-intensive workloads.
As hardware continues evolving toward wider cache lines and more memory-bound workloads, PAX represents not merely an optimization but an architectural imperative. The two-decade journey from academic research to Parquet's industry adoption suggests the time is ripe for revisiting page-level columnar storage in transactional databases. The cache efficiency gains Ailamaki demonstrated in 2001 have only grown more relevant in the age of terabyte-scale analytics running on transactional systems.
References:
- Weaving Relations for Cache Performance (Ailamaki et al., VLDB 2001)
- PostgreSQL Storage Internals
Comments
Please log in or register to join the discussion