Pinterest Engineering has dramatically improved Apache Spark reliability by implementing automatic memory retries, reducing out-of-memory failures by 96% while cutting manual tuning efforts and improving pipeline stability for memory-intensive workloads.
Pinterest Engineering has significantly improved the reliability of its Apache Spark workloads, cutting out-of-memory (OOM) failures by 96% through a combination of improved observability, configuration tuning, and automatic memory retries. This work addresses persistent job failures that disrupted pipelines, increased on-call load, and threatened timely analytics for memory-heavy workloads powering recommendation systems and large-scale data processing.
For years, OOM errors were a persistent headache. Jobs would fail late in execution, often after hours of computation, forcing engineers to manually tweak memory settings to keep pipelines running. These failures disrupted downstream processes, increased on-call load, and made it harder for teams to focus on delivering new features. Fixing the problem required both technical and workflow-level solutions to reduce failures while minimizing manual effort.
A critical first step was improving visibility into how jobs consumed memory. Engineers built detailed metrics for executor memory usage, shuffle operations, and task execution times. This data helped identify hotspots, skewed partitions, and stages that were unusually resource-hungry. As Pinterest engineers explained in their blog post, understanding where memory is consumed within a job is critical to addressing failures effectively. By knowing exactly where problems arose, the team could make precise adjustments rather than simply adding memory across the board.
Visualizing executor-level memory usage and Auto Memory Retry in Spark workflows (Source: Pinterest Blog Post)
Configuration tuning complemented these insights. Spark settings for memory allocation, shuffle partitions, and broadcast joins were optimized for workload patterns. Adaptive query execution allowed the system to adjust partitioning dynamically, reducing memory pressure during heavy stages. Additional preprocessing helped smooth out data skew, and validation checks flagged unusually large or anomalous datasets before they could trigger failures. For high-risk jobs, human review remained part of the workflow, ensuring pipelines stayed stable and predictable.
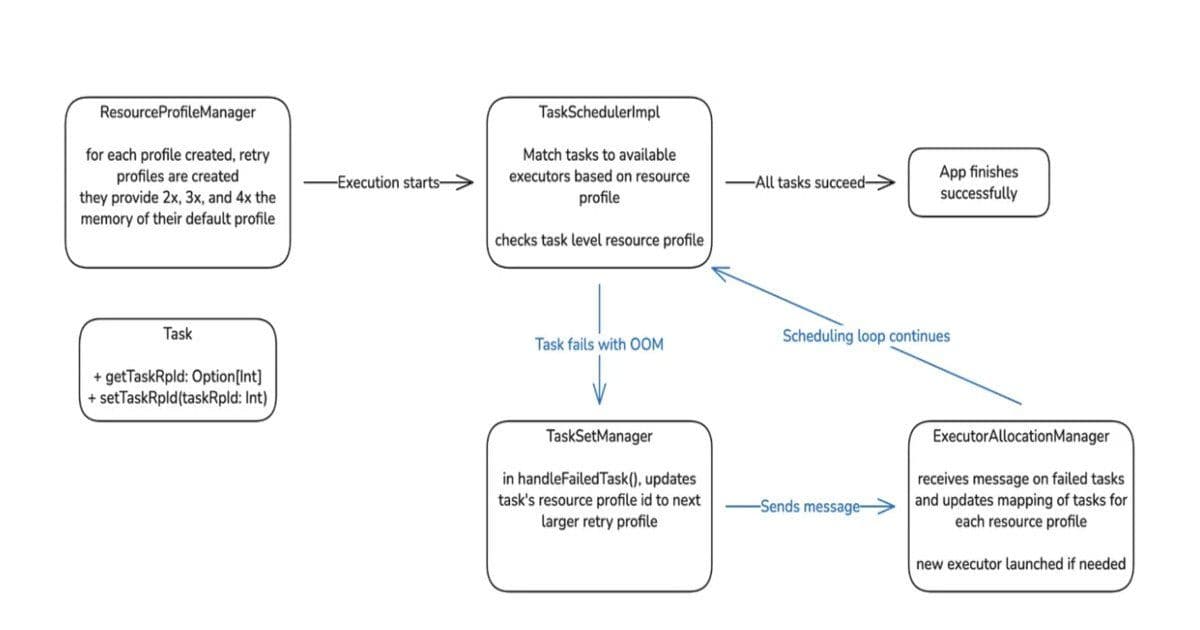
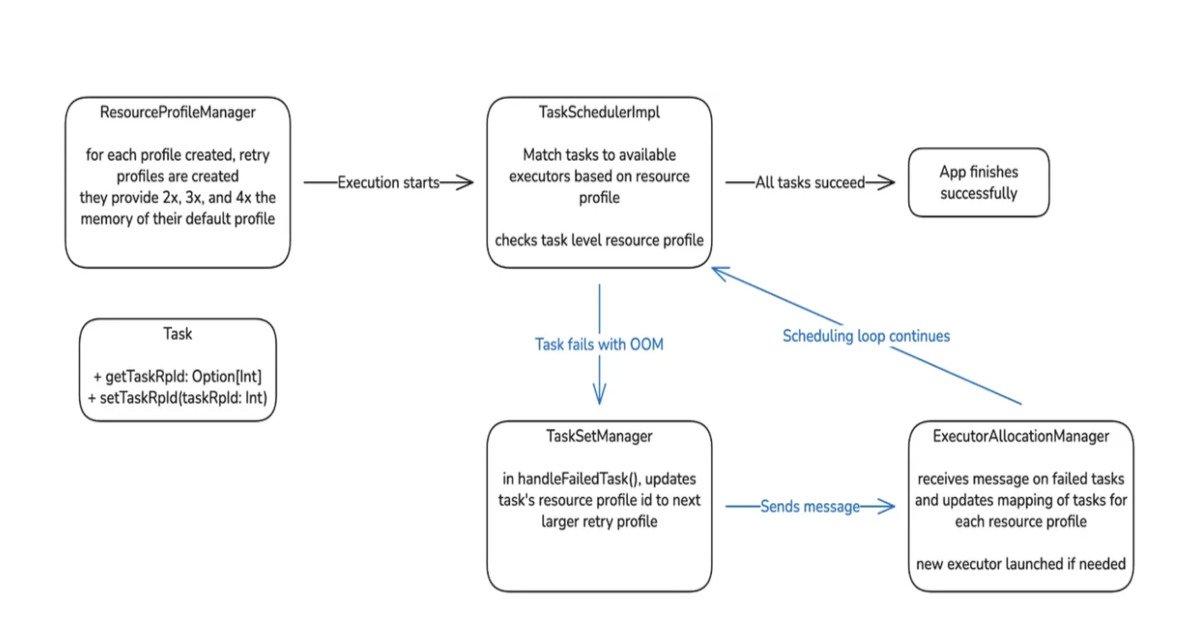
Auto Memory Retries represented a major workflow shift. Jobs that previously failed due to memory exhaustion could now automatically restart with updated memory settings. This automation eliminated much of the manual tuning that had been consuming engineering time while letting pipelines finish without changing core job logic. The rollout was staged carefully. Engineers started with ad hoc jobs, ramping from 0% to 100%, and then moved to scheduled jobs, beginning with lower-priority tiers and eventually applying the feature to critical workloads. A dashboard tracked key metrics such as recovered jobs, cost savings, MB, and vCore seconds saved, and post-retry failures. This staged approach allowed the team to catch issues early, ensure reliability, and fine-tune retries before full deployment.
Along the way, teams learned important operational lessons, including improving scheduler performance for large TaskSets, handling custom resource profiles for Apache Gluten compatibility, and adjusting host failure exclusions so OOM failures no longer blocked retries. Future work includes proactive memory increases, where tasks in high-risk stages receive extra memory before failing, further reducing retries and cluster overhead.
The 96% reduction in OOM failures represents a significant improvement in operational efficiency and reliability. By combining observability, configuration optimization, and automated retries, Pinterest has created a more resilient Spark environment that allows engineers to focus on building features rather than firefighting memory issues. This approach demonstrates how systematic problem-solving and incremental improvements can transform a persistent operational challenge into a manageable workflow.
The work also highlights the importance of staged rollouts and comprehensive monitoring when implementing reliability improvements at scale. By carefully measuring the impact of each change and maintaining visibility into system behavior, the team was able to build confidence in the solution while minimizing risk to production workloads.
For organizations running memory-intensive Spark workloads, Pinterest's approach offers a blueprint for reducing OOM failures through a combination of better observability, smarter configuration, and automated recovery mechanisms. The key insight is that addressing memory issues requires understanding not just how much memory is being used, but where and why it's being consumed within the job execution pipeline.
Comments
Please log in or register to join the discussion