SANA‑WM introduces a 2.6 B‑parameter model that can synthesize controllable 720p videos up to a minute long on a single GPU. The paper’s claims rest on a hybrid linear attention scheme, a dual‑branch camera controller, and a two‑stage generation pipeline. While the reported throughput and quality numbers look impressive, the actual novelty lies in engineering trade‑offs rather than a fundamentally new modeling approach, and several practical constraints remain.
What the paper claims
- A 2.6 B‑parameter world model that turns a single image plus a 6‑DoF camera trajectory into a 720p, 60‑second video on one H100 GPU.
- Hybrid Linear Attention: frame‑wise Gated DeltaNet combined with periodic softmax attention, allowing the model to keep a coherent latent state for a full minute.
- Dual‑branch camera control that mixes a coarse global pose estimate with a fine pixel‑aligned geometric branch to follow metric‑scale trajectories.
- A two‑stage pipeline where a 2.6 B backbone produces a rough rollout and a separate 17 B refiner sharpens texture and motion.
- Training on ~213 k public video clips with automatically extracted metric poses; training time 15 days on 64 H100s.
- Inference speed: one minute of 720p video in ~1 s on a single H100, or ~34 s on an RTX 5090 with NVFP4 quantisation.
- Benchmarks claim action‑following accuracy surpassing open‑source baselines (LingBot‑World, HY‑WorldPlay) and a 36× throughput advantage.
What is actually new
| Component | Prior work | Incremental change |
|---|---|---|
| Hybrid linear attention | Linear‑attention video models (e.g., Long‑Video Diffusion, DiT‑VAE) use either pure linear or full softmax attention. | SANA‑WM inserts a Gated DeltaNet that updates a hidden state with a cheap linear kernel, then applies a periodic full‑softmax over a sliding window. This reduces memory but does not eliminate the quadratic cost entirely; the softmax still runs every few frames. |
| Dual‑branch camera controller | Earlier world‑models (e.g., DreamFusion, Make‑It‑3D) condition on pose embeddings but rely on a single branch. | Two parallel branches (global pose + pixel‑aligned geometry) improve metric accuracy, but the idea of a coarse‑fine split is well‑known in SLAM and pose‑estimation literature. |
| Two‑stage refiner | Multi‑stage diffusion pipelines (Imagen 2, Stable‑Video) already separate coarse generation from high‑resolution refinement. | The refiner is simply a larger diffusion model (17 B) applied after the 2.6 B rollout. The novelty is the dedicated “long‑video” training regime rather than a new architecture. |
| Annotation pipeline | Pose extraction from internet videos has been explored (e.g., ARKit‑based datasets, Pose‑Track). | The authors claim a fully automated metric‑scale extraction, but the paper provides limited quantitative validation of pose error. |
In short, SANA‑WM’s contributions are engineering optimisations that make an existing diffusion‑based world model run faster at longer horizons. There is no breakthrough in the underlying generative formulation.
Limitations and practical concerns
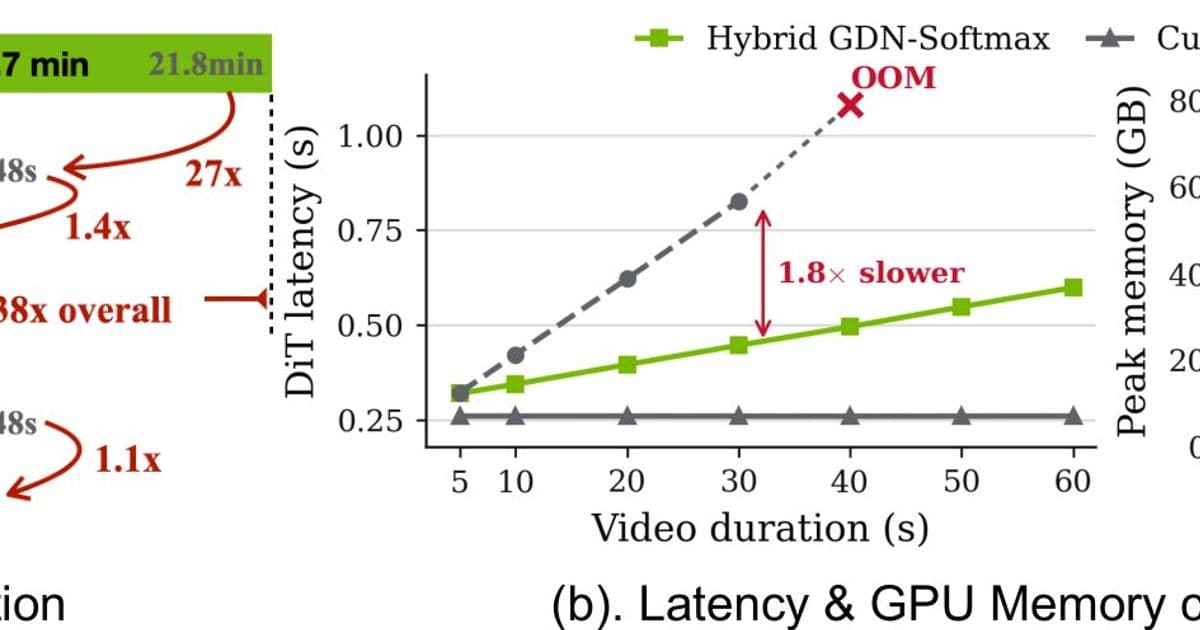
- Memory still spikes for very long sequences – Figure 1 shows that all‑softmax variants run out of memory beyond 60 s, and the hybrid approach only postpones the OOM by a factor of two. Scaling to multi‑minute videos would likely require further chunking or hierarchical latent structures.
- Dependency on accurate pose supervision – The model’s action‑following ability hinges on the quality of the automatically extracted 6‑DoF trajectories. Errors in pose estimation propagate directly into visual artifacts, especially in fast‑motion scenes that the paper does not evaluate.
- Two‑stage pipeline complexity – Deploying the 17 B refiner adds a substantial runtime and memory overhead. While the authors provide a distilled 5090 variant, the quality drop is noticeable in fine‑grained textures (e.g., water caustics, fur).
- Limited diversity of training data – 213 k clips is modest compared to commercial datasets (hundreds of millions). The benchmark focuses on static‑camera, low‑action prompts; it is unclear how the model handles dynamic camera moves or complex interactions.
- Open‑source release status – The paper mentions “code and models soon”. Until the repository is public, reproducibility remains an open question.
Why it matters
- Throughput: Achieving minute‑scale generation on a single GPU is a useful engineering target for research labs that cannot afford massive clusters.
- Control: Precise 6‑DoF camera conditioning opens up applications in robotics simulation, virtual production, and interactive storytelling where deterministic camera paths are required.
- Benchmarking: The authors introduce a one‑minute world‑model benchmark that could become a reference point for future efficiency studies.
What to watch next
- Scaling beyond 60 s – The community will need to see whether the hybrid attention can be combined with hierarchical latent caching to reach multi‑minute or even hour‑scale rollouts.
- Robust pose supervision – A more thorough ablation of pose noise and its impact on visual fidelity would help gauge the model’s reliability in real‑world pipelines.
- Open‑source validation – Once the code is released, independent replication of the 36× throughput claim will be the ultimate test.
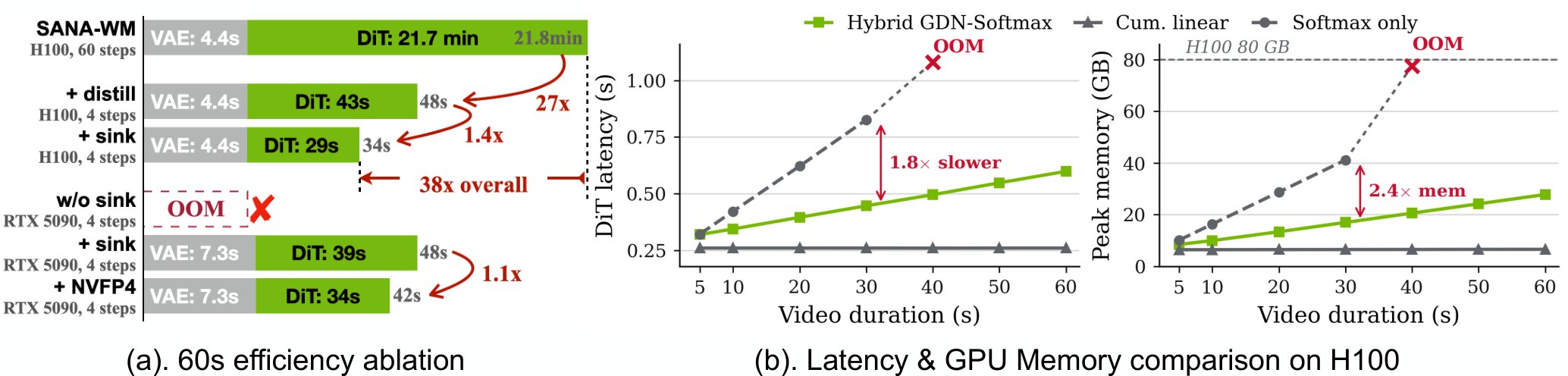 Figure 1. Efficiency ablation and scaling (left: per‑stage latency; right: H100 latency vs. video length). The hybrid linear variant stays within GPU memory up to 60 s, whereas a pure‑softmax design runs out of memory earlier.
Figure 1. Efficiency ablation and scaling (left: per‑stage latency; right: H100 latency vs. video length). The hybrid linear variant stays within GPU memory up to 60 s, whereas a pure‑softmax design runs out of memory earlier.
References
- Zhu, H., Liu, H., Zhao, Y., Ye, T., Chen, J., Yu, J., He, T., Han, S., & Xie, E. (2026). SANA‑WM: Efficient Minute‑Scale World Modeling with Hybrid Linear Diffusion Transformer. arXiv:2605.15178.
- Official project page (to be released) – expected to host model checkpoints and training scripts.
- Related code bases: DiT‑VAE, Stable‑Video.
Comments
Please log in or register to join the discussion