
Notion scaled its PostgreSQL database to handle billions of atomic blocks using application-level sharding and zero-downtime migration strategies while maintaining their Node.js monolith architecture.

Modern productivity tools face immense scaling challenges as user bases grow exponentially. Notion's journey from a simple Node.js/PostgreSQL stack to handling billions of atomic "blocks" demonstrates how thoughtful database architecture can solve scaling problems without abandoning monolithic application design.
The Monolith Bottleneck
Early Notion architecture followed a conventional pattern: a Node.js backend communicating with a single PostgreSQL instance. As user numbers grew, this approach hit critical limitations:
- CPU Saturation: Daily CPU usage consistently exceeded 90% during peak loads
- Vacuum Failures: PostgreSQL's autovacuum process couldn't keep pace with write volume
- Transaction ID Wraparound Risk: The database approached a state where it would refuse writes to prevent data corruption
These weren't abstract concerns—each represented an existential risk to service reliability.
Why Sharding Over Microservices?
When facing scaling limitations, many organizations reflexively adopt microservices. Notion deliberately avoided this path for several reasons:
- Operational Complexity: Distributed transactions across services would complicate their core "block" data model
- Development Velocity: Maintaining a monolith preserved developer productivity
- Data Locality: Their hierarchical content structure (pages containing nested blocks) performed better with co-located data
Instead, Notion focused on horizontally scaling the persistence layer while preserving application architecture.
The 480-Shard Architecture
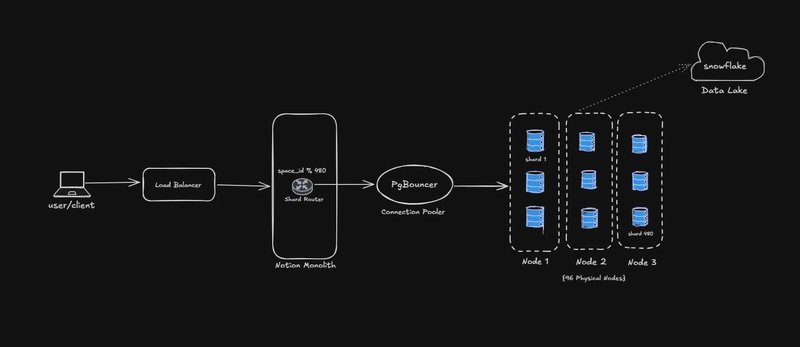
Notion implemented logical sharding at the application level using these key components:
| Component | Implementation | Purpose |
|---|---|---|
| Partition Key | space_id |
Ensures all workspace data remains co-located |
| Shard Router | TypeScript logic using space_id % 480 |
Directs queries to correct shard |
| Logical Shards | 480 independent PostgreSQL schemas | Virtual partitioning of data |
| Physical Nodes | 32 AWS RDS instances (initial) | Hardware distribution layer |
| Connection Pooling | PgBouncer | Prevents connection exhaustion to shards |
This architecture enabled linear scalability: When physical nodes approached capacity, engineers could migrate logical shards to new hardware without code changes. The 480 shard count was deliberately oversized to accommodate future growth.
Zero-Downtime Migration Strategy
Migrating terabytes of live data required meticulous planning. Notion's migration sequence:
- Shadow Writes: New data written simultaneously to legacy DB and target shards
- Background Backfill: Historical data migrated incrementally during off-peak hours
- Consistency Verification: Comparison engine validated data integrity between sources
- Controlled Cutover: Traffic shifted to shards only after verification
This approach eliminated downtime while ensuring data integrity during the transition.
Scaling Evolution: From 32 to 96 Nodes
By 2023, the original 32-node cluster reached saturation. Thanks to logical sharding, scaling involved:
- Tripling physical nodes to 96
- Redistributing shards across new hardware
- Zero application code changes
The architecture's flexibility proved its value—capacity tripled without disrupting development workflows.
Supporting Infrastructure
Cross-Shard Analytics
With data distributed across 480 shards, Notion implemented:
- Central Data Lake: Consolidated data from all shards using Fivetran pipelines
- Analytics Processing: Snowflake for cross-shard reporting and analytics
Connection Management

PgBouncer solved the connection scaling problem:
- Reduced connection overhead by pooling backend requests
- Prevented connection storms during traffic spikes
- Allowed backend services to communicate with hundreds of shards efficiently
Tradeoffs and Considerations
While successful, this approach involves compromises:
- Application Complexity: Shard routing logic lives in application code
- Cross-Shard Operations: JOINs across workspaces require separate handling
- Tooling Limitations: Standard PostgreSQL tools don't natively understand sharding
Notion mitigated these through careful abstraction and tool development.
Conclusion
Notion's scaling journey demonstrates that monoliths can handle massive scale through targeted database innovation. Their approach delivered:
- Cost Efficiency: Added capacity incrementally without rearchitecting
- Operational Simplicity: Maintained developer velocity
- Proven Scalability: Handled billions of atomic "block" operations
As data-intensive applications grow, Notion's example proves that sometimes the most effective scaling strategy isn't breaking things apart—but partitioning them intelligently.
For organizations facing similar scaling challenges, PostgreSQL's table partitioning documentation provides foundational concepts, while PgBouncer's connection pooling remains essential for sharded architectures.
Comments
Please log in or register to join the discussion