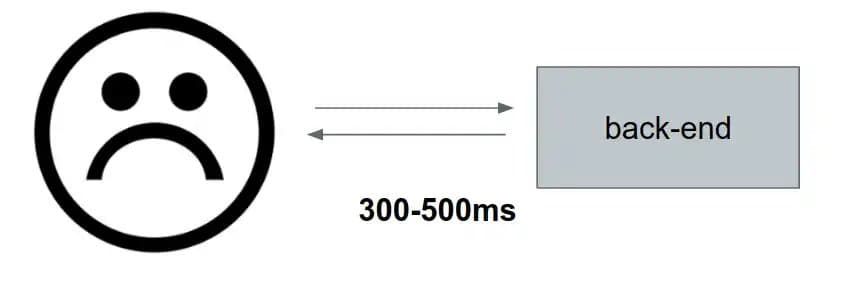
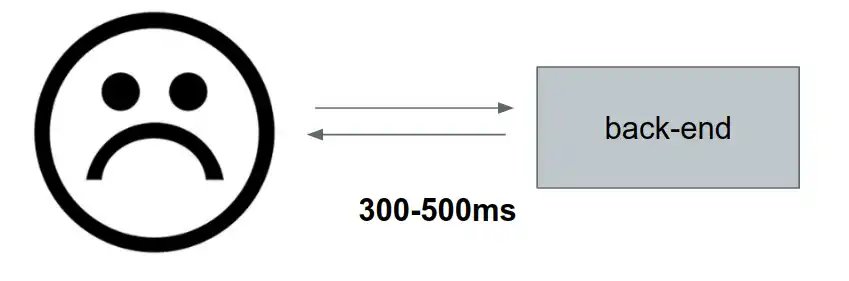
A deep dive into how Sensor Tower reduced a critical endpoint’s latency from 300‑500 ms to 80 ms by profiling Ruby code, adding dirty‑flag checks to avoid unnecessary Protobuf re‑encoding, and replacing full tree traversals with cached logarithmic path lookups.
Speeding Up the Back End with Graph Theory
Sensor Tower processes massive streams of mobile‑app data, and the responsiveness of its public APIs directly influences the experience of product managers, marketers, and analysts who rely on near‑real‑time insights. When a high‑traffic endpoint began returning responses that lingered for three to five hundred milliseconds—while its peers consistently stayed under fifty milliseconds—the engineering team launched a systematic investigation that ultimately yielded a four‑fold speedup.
The symptom and the first look
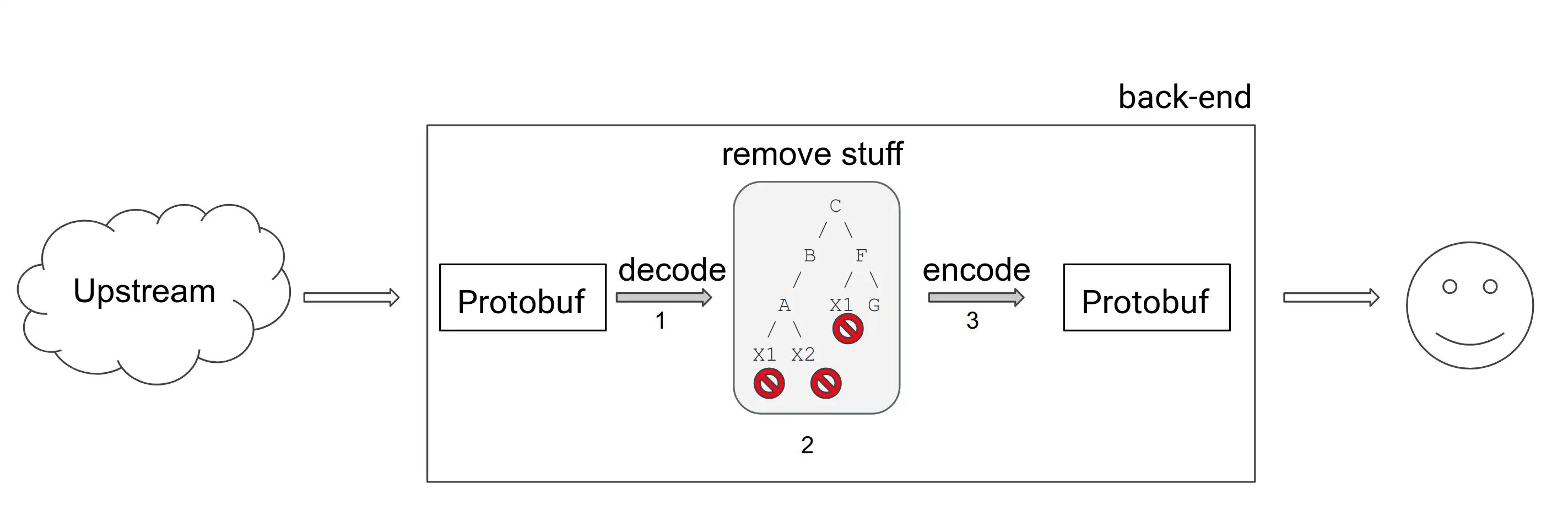
The problematic endpoint accepts a Protocol Buffers (Protobuf) payload, mutates the data according to business rules, and returns a new Protobuf blob. Protobuf is Google’s binary serialization format; it packs a tree‑like structure into a compact byte stream, much like JSON but without the textual overhead.
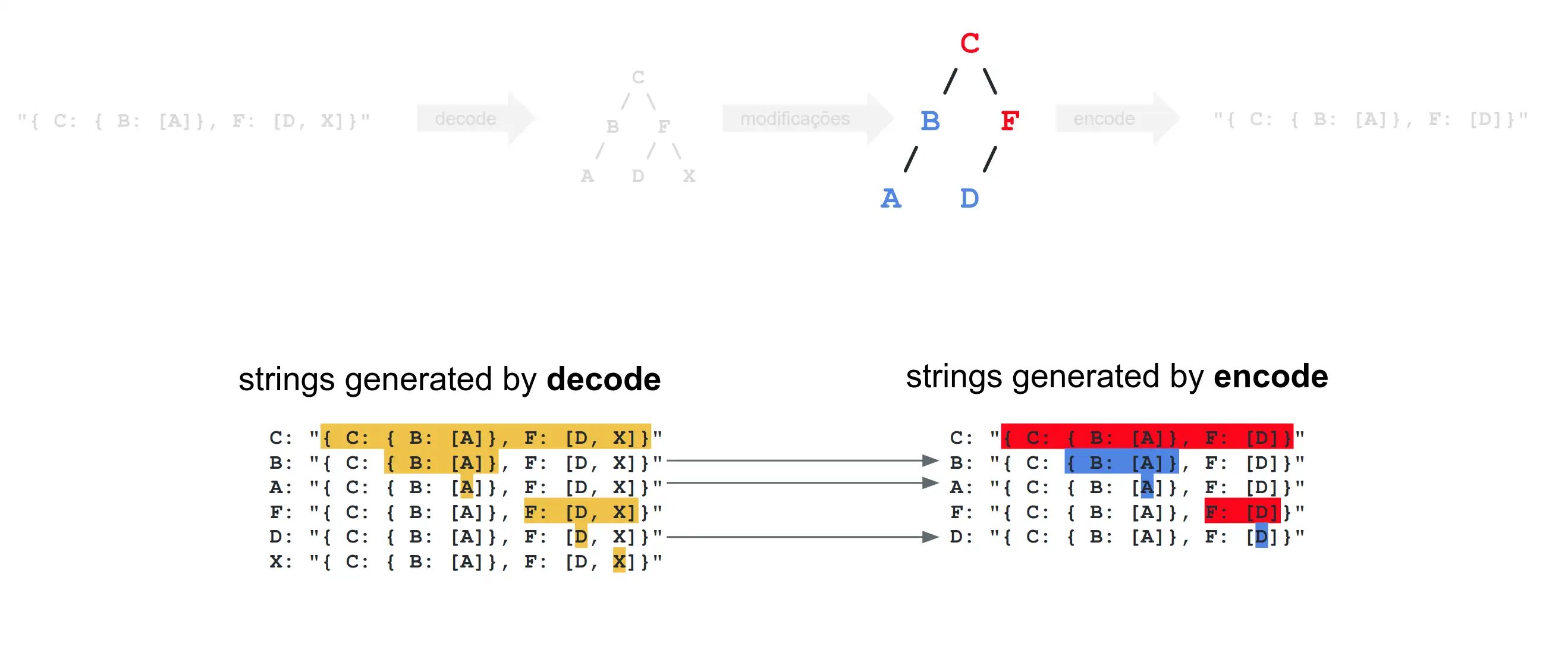
A quick dashboard view highlighted the outlier, and the team sketched the service’s internal flow:
The diagram shows three logical stages:
- Decode the incoming byte stream into a Ruby object tree.
- Modify the object according to the request’s intent.
- Encode the altered object back into Protobuf for the response.
Profiling reveals the hot spots
Rather than guessing, the engineers attached the Ruby profiler ruby‑prof and visualised the results with KCacheGrind. Two methods dominated the CPU profile:
#find_all– responsible for walking the decoded tree and applying modifications.#encode– responsible for turning the Ruby tree back into a Protobuf byte array.
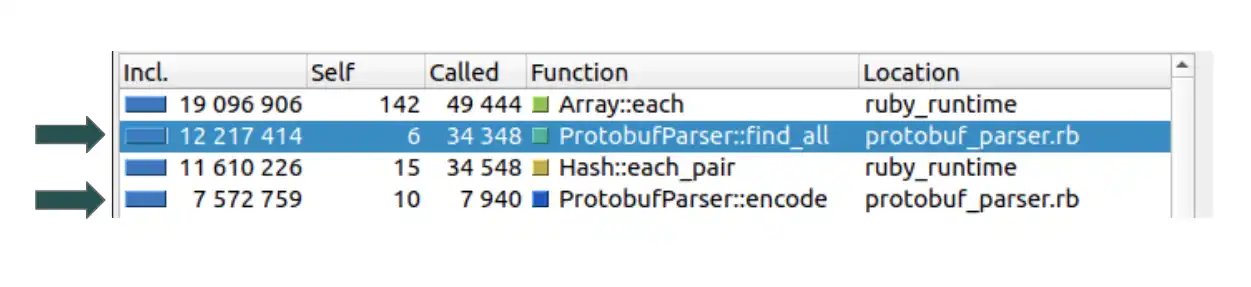
A single run of the profiler was insufficient because the endpoint processes thousands of heterogeneous payloads each hour. To validate the findings, the team benchmarked the two methods across a representative sample of requests. The combined runtime of #find_all and #encode accounted for virtually the entire latency budget, confirming that any improvement must target these two paths.
First optimization – selective re‑encoding
Understanding the recursive work
Both decoding and encoding are recursive: they start at the root node and descend to every leaf. Each node in the Ruby representation also stores the original Protobuf fragment that produced it. In many cases the node is never altered, meaning the stored fragment is already the correct output.

The change
The team introduced a dirty flag (@dirty) on each node. When a node or any of its descendants is modified, the flag is set; otherwise it remains false. During the encoding phase the algorithm now checks the flag and skips re‑serialization for clean nodes, re‑using the cached Protobuf fragment instead.
The code modification was minimal—essentially a couple of conditional checks and the flag assignment—but the impact was immediate: latency dropped by roughly thirty percent.
Second optimization – cached logarithmic paths
The problem with naïve traversal
#find_all originally performed a full depth‑first traversal to locate the nodes that needed removal. This linear scan (O(n)) becomes costly when the tree contains thousands of elements.
Exploiting the tree’s structure
In practice, the nodes of interest tend to appear along a relatively small set of paths. By collecting the most common root‑to‑target paths over time, the team could store them in a lookup table. Accessing a node via a known path reduces the cost to logarithmic time (O(log n)) because the traversal depth is bounded by the tree height, which grows logarithmically with node count.
The engineers measured the diversity of observed paths and found a clear logarithmic growth pattern:
Implementation and trade‑offs
During request handling the service first checks whether a cached path exists for the target node. If it does, the algorithm follows that path directly; otherwise it falls back to the full traversal. Over time the cache is refreshed with newly observed paths, keeping the hit rate high while limiting the memory footprint.
Because the cache does not guarantee 100 % coverage, a few nodes may be missed. In Sensor Tower’s use case, missing a handful of modifications among thousands of requests per hour was acceptable, and the overall latency improvement was dramatic—a three‑hundred percent speedup for the #find_all stage.
Putting it together – the final numbers
After deploying both optimizations, the endpoint’s latency distribution collapsed from the 300‑500 ms range to a tight band around 80 ms, with no perceptible degradation in data correctness for the majority of customers.
The chart illustrates the before‑and‑after performance across a week of production traffic.
Reflections and broader implications
The story underscores several principles that apply to many high‑throughput services:
- Profile before you refactor. A targeted profiler can surface unexpected hotspots that manual code review would miss.
- Cache what you can, but know the cost. Storing the original Protobuf fragment eliminated redundant work without altering the public API.
- Leverage statistical regularities. Even in seemingly unordered data, patterns emerge; recognizing and exploiting them can convert linear work into logarithmic work.
- Accept graceful degradation when appropriate. A small, bounded loss of precision can be a worthwhile trade‑off for large latency gains, provided the business impact is understood.
These techniques—dirty‑flag caching and path‑based lookups—are not limited to Protobuf processing. Any system that repeatedly serialises/deserialises hierarchical data structures (XML, Avro, custom binary formats) can benefit from similar ideas.
Looking ahead
The engineering team continues to monitor path coverage and plans to introduce a background job that periodically re‑evaluates the cached paths against the latest payload distribution. This will keep the accuracy high while preserving the low‑latency response path.
If you are interested in contributing to similar performance‑focused projects, Sensor Tower’s career page lists current openings for backend engineers, data engineers, and performance analysts.
Written by Leonardo Brito, Full‑stack Developer, November 2019
Comments
Please log in or register to join the discussion