
A technical deep dive into the architectural transformations required to scale from basic setups to systems handling millions of users, examining critical components and their trade-offs.

Building systems that scale from initial prototypes to massive user bases requires fundamental architectural shifts. This progression reveals essential distributed systems patterns and their operational implications.
1. The Monolithic Starting Point
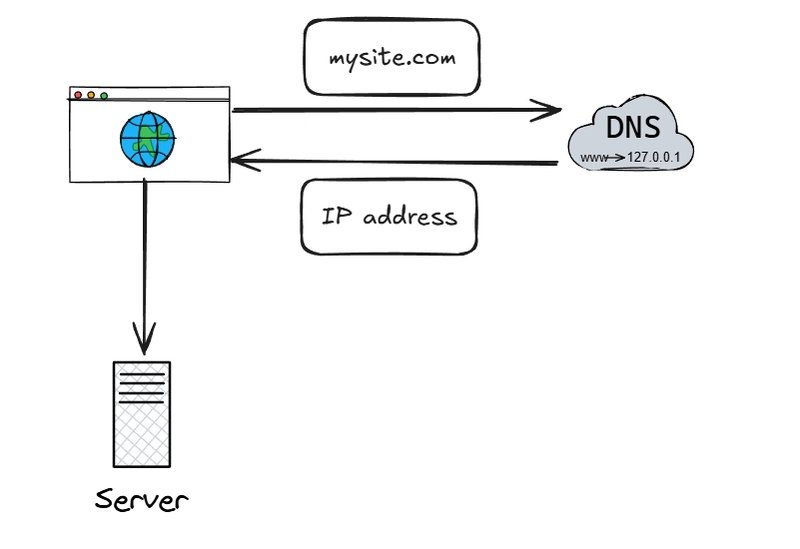 All systems begin with a single-server architecture where web application, database, and business logic coexist. While simple to deploy, this approach creates a single point of failure (SPOF) - any hardware failure or maintenance operation takes the entire system offline. Database queries compete with application logic for the same CPU and memory resources, creating artificial bottlenecks even before significant user growth.
All systems begin with a single-server architecture where web application, database, and business logic coexist. While simple to deploy, this approach creates a single point of failure (SPOF) - any hardware failure or maintenance operation takes the entire system offline. Database queries compete with application logic for the same CPU and memory resources, creating artificial bottlenecks even before significant user growth.
2. Database Specialization
When user counts reach ~5,000 daily active users, separating the database server becomes critical. This allows:
- Independent scaling of compute and storage resources
- Dedicated optimization for transactional workloads
- Separate backup and recovery strategies
NoSQL consideration: Document stores like MongoDB become viable when:
- Response times must stay <10ms at 99th percentile
- Schema flexibility outweighs transactional guarantees
- Write throughput exceeds relational database capabilities
3. Scaling Dimensions: Vertical vs Horizontal
Vertical scaling (Scale-up):
- Increases individual server capacity (CPU/RAM/SSD)
- Limited by physical hardware constraints
- Creates increasingly expensive failure domains
Horizontal scaling (Scale-out):
- Adds commodity servers to a pool
- Requires load balancing infrastructure
- Enables true elastic scaling
At ~50,000 users, horizontal scaling becomes economically mandatory. Cloud providers charge 3-5x premium for largest instance types compared to medium-sized instances with equivalent aggregate resources.
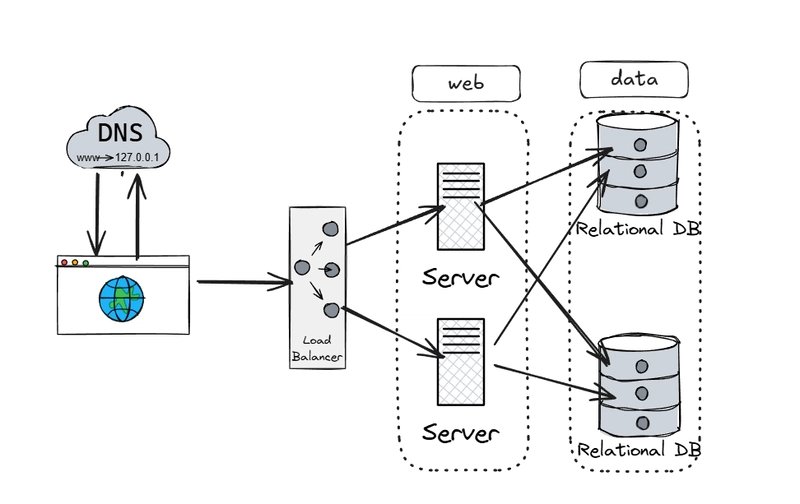
4. Load Balancing: The Traffic Cop
 Load balancers (LBs) distribute requests across server pools using algorithms like:
Load balancers (LBs) distribute requests across server pools using algorithms like:
- Round robin
- Least connections
- IP hash
Critical capabilities:
- Health checks remove unhealthy nodes
- SSL termination offloads crypto overhead
- Session persistence options
Modern systems use layered LBs - global DNS-based load balancers route to regional LBs, which distribute to availability zone-specific pools.
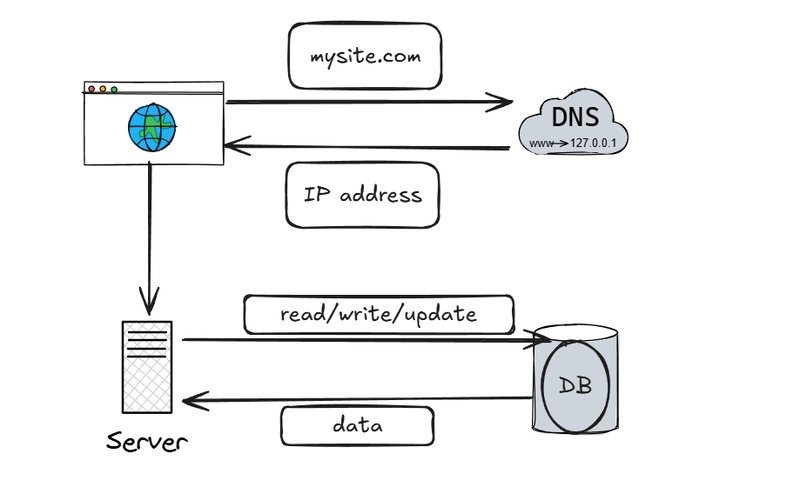
5. Database Redundancy Through Replication
 Master-replica replication provides:
Master-replica replication provides:
- Read scalability: Direct read queries to replicas
- Failure resilience: Automatic failover to replicas
- Geographic distribution: Place replicas near users
Consistency trade-offs: Asynchronous replication creates eventual consistency. Network partitions can cause stale reads. Synchronous replication impacts write latency.
6. Performance Accelerators: Caching & CDNs
Caching layers:
- Redis/Memcached for database query results
- Application-level object caches
- HTTP caching headers for browser caching
Content Delivery Networks:
- Cache static assets at edge locations
- Reduce latency through geographic proximity
- Offload >90% of static content traffic
Cache invalidation strategies become critical as systems scale - poorly implemented caching can serve stale data or create thundering herds.
7. Stateless Architecture Imperative
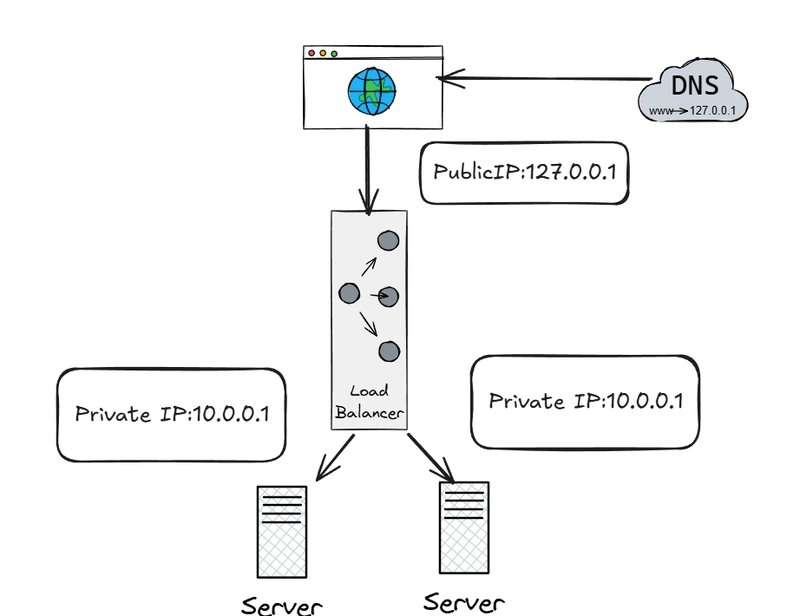 Horizontal scaling requires eliminating server-local state:
Horizontal scaling requires eliminating server-local state:
- Store sessions in distributed Redis cluster
- Use JWT tokens with expiration instead of server sessions
- Ensure any server can handle any request
Statelessness enables automatic scaling events - new instances can join pools without manual configuration.
8. Message Queues: Decoupling Components
Message queues (Kafka, RabbitMQ, SQS) provide:
- Asynchronous processing: Decouple resource-intensive tasks from request/response cycles
- Buffering: Absorb traffic spikes without overwhelming consumers
- Retry mechanisms: Automatic failed message reprocessing
Trade-off: Added complexity in message ordering, exactly-once delivery semantics, and dead letter queue management.
9. Database Sharding: The Nuclear Option
When database writes exceed a single node's capacity (~50,000 writes/sec for PostgreSQL), sharding partitions data across multiple machines:
Sharding strategies:
- Range-based (user IDs 0-1M on shard1, 1M-2M on shard2)
- Hash-based (consistent hashing of shard key)
- Directory-based (lookup service for shard locations)
Operational challenges:
- Cross-shard queries become distributed transactions
- Schema changes require coordination
- Data rebalancing consumes resources
10. Monitoring at Scale
Observability becomes critical with distributed components:
- Log aggregation: Centralized storage with Elasticsearch/Splunk
- Metrics collection: Prometheus for time-series monitoring
- Distributed tracing: Jaeger/Zipkin for request lifecycle analysis
Automated alerting based on SLOs (Service Level Objectives) enables proactive response before users notice degradation.
The Scaling Journey
Scaling to millions of users isn't about individual technologies but architectural patterns:
- Redundancy: Eliminate all single points of failure
- Distribution: Spread load across resources
- Decoupling: Separate components with clear interfaces
- Automation: Replace manual processes with code
Each scaling phase introduces new trade-offs - what simplifies operations at 100 users creates bottlenecks at 100,000 users. The most successful systems anticipate these transitions before they become emergencies.
Further reading:
Comments
Please log in or register to join the discussion