Sebastian Raschka's exploration of coding agents reveals that the true advancement in practical LLM systems lies not just in model capabilities but in the sophisticated scaffolding that surrounds them.
The Architecture of Coding Agents: Beyond the Model to the System
In his comprehensive analysis "Components of A Coding Agent," Sebastian Raschka provides a timely examination of what truly makes modern coding assistants effective. The article argues that the significant performance gap between plain LLM chat interfaces and specialized coding tools like Claude Code or Codex CLI stems not primarily from superior models, but from the sophisticated system architecture that surrounds them.
The Core Argument: The Model Alone Is Insufficient
Raschka establishes a crucial distinction that often gets lost in discussions about LLM capabilities: the difference between the raw model, reasoning models, and the agent harness. As he explains, "much of the recent progress in practical LLM systems is not just about better models, but about how we use them." This perspective challenges the common tendency to attribute coding performance improvements solely to model advancements.
The author introduces a helpful analogy: "the LLM is the engine, a reasoning model is a beefed-up engine (more powerful, but more expensive to use), and an agent harness helps us the model." This framework helps readers understand that coding agents represent a systems-level innovation, not merely a collection of incremental model improvements.
Six Pillars of Effective Coding Harnesses
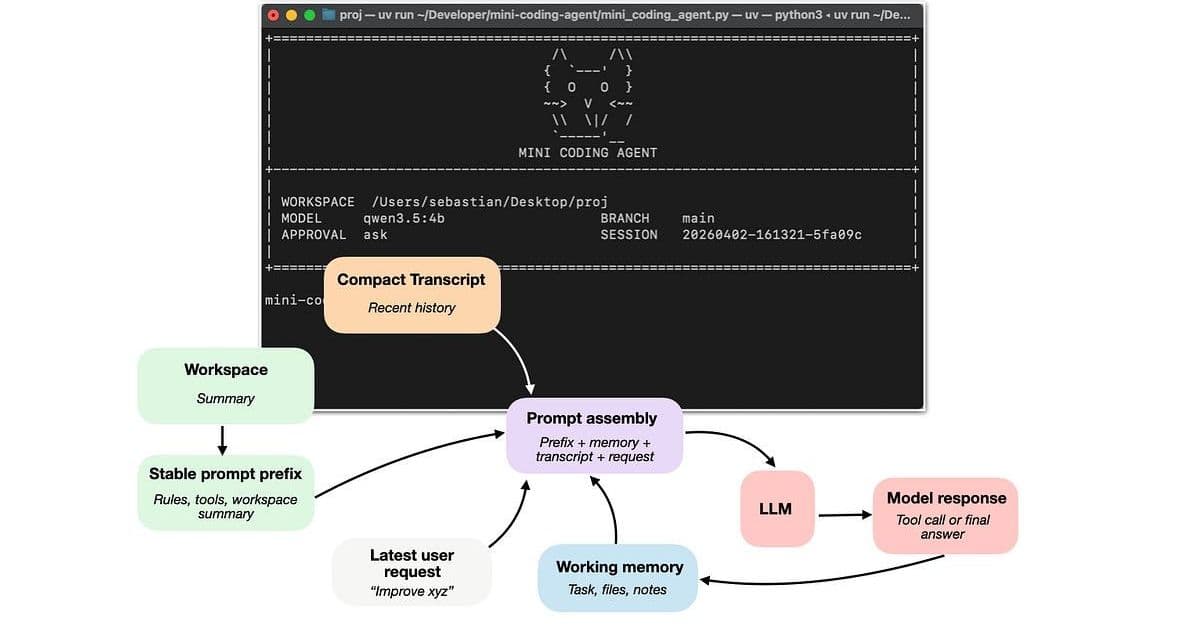
Raschka meticulously breaks down the architecture of coding agents into six interconnected components, each playing a critical role in transforming a language model into an effective coding assistant.
1. Live Repo Context
The first component addresses the fundamental challenge of providing the model with relevant project information. As Raschka notes, "when a user says 'fix the tests' or 'implement xyz,' the model should know whether it is inside a Git repo, what branch it is on, which project documents might contain instructions, and so on." This component creates a workspace summary that combines with user requests to provide contextual grounding.
This is particularly important because coding tasks are rarely self-contained. The model needs to understand the project structure, existing conventions, and current state to make appropriate decisions. The author suggests this upfront context gathering prevents the agent from "starting from zero, without context, on every prompt."
2. Prompt Shape And Cache Reuse
The second component addresses efficiency in prompt construction. Rather than rebuilding the entire prompt from scratch on each interaction, effective coding harnesses separate stable elements from dynamic ones. The "stable prompt prefix" contains information that changes infrequently—general instructions, tool descriptions, and workspace summaries—while dynamic elements like recent transcripts and user requests are updated more frequently.
This architectural decision represents a practical optimization that significantly reduces computational overhead while maintaining context. It recognizes that coding sessions are repetitive, with many elements remaining constant across interactions.
3. Tool Access and Use
This component marks the transition from chat-like interaction to true agency. Raschka explains that "a plain model can suggest commands in prose, but an LLM in a coding harness should do something narrower and more useful and be actually able to execute the command and retrieve the results." The harness provides a structured interface to tools rather than allowing the model to improvise arbitrary syntax.
The tool-use flow includes validation steps that check whether the requested action is known, whether arguments are valid, and whether user approval is needed. This structured approach not only enhances safety but also improves reliability by constraining the model's actions within well-defined boundaries.
4. Minimizing Context Bloat
Context management represents one of the most significant challenges in coding agents. Raschka correctly identifies that "coding agents are even more susceptible to context bloat than regular LLMs during multi-turn chats, because of repeated file reads, lengthy tool outputs, logs, etc."
Effective harnesses employ sophisticated strategies beyond simple truncation. These include clipping long outputs, deduplicating repeated file reads, and implementing transcript compression that maintains richer details for recent events while more aggressively compressing older ones. The author insightfully notes that "a lot of apparent 'model quality' is really context quality."
5. Structured Session Memory
This component distinguishes between transient and persistent state. The author explains that coding agents separate state into at least two layers: "working memory," which is a small, distilled state kept explicitly, and a "full transcript" that covers all user requests, tool outputs, and LLM responses.
The working memory serves task continuity by maintaining a small summary of what matters across turns, while the full transcript enables session resumption. This dual-layer approach balances the need for context preservation with the constraints of token limits.
6. Delegation With (Bounded) Subagents
The final component addresses the challenge of parallelizing work through subagents. Raschka explains that "it is useful to split that off into a bounded subtask instead of forcing one loop to carry every thread of work at once." Subagents inherit sufficient context to be useful but operate within constrained boundaries to prevent uncontrolled recursion or conflicts.
This architectural pattern enables more complex workflows where the main agent can delegate specific subtasks—such as symbol lookup or configuration checking—to specialized subagents without overwhelming the primary decision-making loop.
Implications for the Field
Raschka's analysis carries several important implications for the development and deployment of LLM systems:
The Rise of Systems Innovation: The article suggests we're entering an era where system-level innovation may outpace pure model improvements. The "harness"—the software scaffold around the model—becomes the primary differentiator between similar capabilities.
Specialization Over Generality: While general-purpose agents like OpenClaw have their place, coding agents demonstrate the value of specialization. The author notes that "coding agents are optimized for a person working in a repository and asking a coding assistant to inspect files, edit code, and run local tools efficiently."
The Importance of Engineering: As Raschka speculates, "if we dropped one of the latest, most capable open-weight LLMs... into a similar harness, it could likely perform on par with" proprietary models. This suggests that engineering excellence in the harness layer may level the playing field more than previously thought.
Context as a First-Class Citizen: The analysis elevates context management from an afterthought to a core architectural consideration. Effective context handling—through caching, compression, and structured memory—becomes as important as model selection.
Counter-Perspectives and Limitations
While Raschka's analysis is compelling, it's worth considering some counter-perspectives:
The Arms Race Continues: Despite the emphasis on systems innovation, model capabilities continue to advance rapidly. Future models may incorporate many of these harness features natively, potentially reducing the relative importance of the surrounding architecture.
Resource Requirements: The sophisticated architectures described require significant engineering effort and computational resources. This could create barriers to entry for smaller organizations or open-source projects.
Evaluation Challenges: The article doesn't address how to systematically evaluate these complex systems. Determining whether performance improvements stem from the model, the harness, or their interaction remains a difficult challenge.
The Generality-Specialization Tradeoff: While specialized coding agents offer clear advantages for their domain, more general-purpose agents like OpenClaw may ultimately prove more valuable as AI systems become increasingly integrated into diverse workflows.
Conclusion
Raschka's "Components of A Coding Agent" provides a valuable framework for understanding the next frontier in LLM systems development. By shifting focus from model capabilities alone to the sophisticated architectures that surround them, the article offers insights that will benefit both researchers and practitioners in the field.
The six components identified—live repo context, prompt caching, tool access, context management, structured memory, and delegation—represent a comprehensive approach to building effective coding assistants. As the author demonstrates through his Mini Coding Agent, these concepts can be implemented in relatively clean, minimalist code, suggesting they represent fundamental architectural patterns rather than proprietary secrets.
In a field often captivated by the latest model breakthroughs, this analysis reminds us that the most significant advances may come not from bigger models, but from smarter systems that know how to use them effectively.
Comments
Please log in or register to join the discussion