A deep dive into the Noroboto font exploit that can deceive AI systems processing legal documents, the technical mechanisms behind the attack, and potential mitigation strategies in Rust-based document processing systems.
The modern legal technology landscape represents a complex ecosystem of interconnected systems, where decades-old document specifications meet cutting-edge artificial intelligence. This convergence, while enabling unprecedented efficiency in legal document processing, has created vulnerabilities that sophisticated actors could exploit. The Noroboto project reveals one such vulnerability: the ability to create deceptive fonts that can manipulate how AI systems interpret legal documents, potentially altering contractual terms, jurisdictional clauses, or confidentiality obligations without raising immediate suspicion.
At its core, the Noroboto exploit leverages a fundamental aspect of digital documents—embedded fonts. Modern document formats like DOCX and PDF allow font embedding to ensure consistent rendering across different systems and platforms. This feature, while essential for maintaining visual fidelity, creates an attack surface where the relationship between visual appearance and underlying text representation can be manipulated.
The technical implementation of Noroboto is both elegant and concerning. By creating a TrueType font that maps standard Unicode characters to "Private Use Areas" (PUA) in Unicode, the attack creates a situation where what the human user sees on screen differs from what AI systems extract when processing the document. The simplest version of this attack involves a 1:1 mapping of characters to PUA code points, which then renders as visually identical glyphs but contains incomprehensible Unicode data when copied or processed programmatically.
Testing revealed a cat-and-mouse game between the attack techniques and evolving AI capabilities. Early versions of the exploit were defeated by ChatGPT 5.5, which treated the simple substitution cipher as a basic cryptoanalysis problem. The researchers responded by implementing more sophisticated techniques, including a 4:1 randomized mapping and removal of metadata that could reveal the original character mappings. These stochastic approaches proved more effective at evading detection, though the most advanced AI systems could still overcome full obfuscation by rendering the document and applying optical character recognition (OCR).
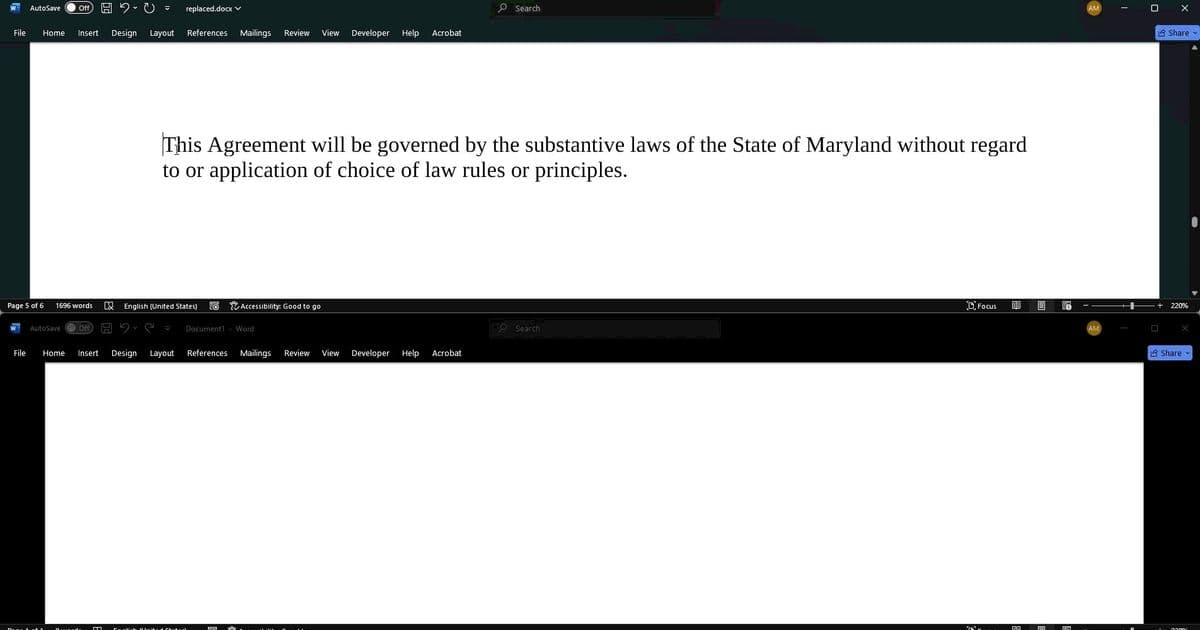
The most concerning variation of the attack, however, involves direct Unicode replacement rather than mere obfuscation. In this approach, the malicious font maps visible characters to completely different Unicode values. For example, the word "Maryland" could be rendered correctly to the human eye while actually containing the Unicode representation for "Delaware." This attack successfully deceived all tested platforms, with AI systems confidently reporting that agreements contained Delaware governing law when the visible text clearly indicated Maryland.
The partial obfuscation technique presents a particularly insidious threat. By obscuring only specific terms or clauses within an otherwise legitimate document, this approach creates a situation where human reviewers might not notice discrepancies while AI systems extract incorrect information. In one test case, the researchers successfully hid the fact that an NDA's confidentiality terms applied to "successors and assigns," with some AI platforms failing to detect this crucial extension of obligations.
Addressing this vulnerability requires a "trust but verify" approach, as implemented in the Tritium project's Rust-based solution. The core insight is that while embedded fonts must be supported for layout accuracy, their claims about Unicode mappings can be independently verified. The Tritium implementation creates a font atlas containing ASCII characters, renders these glyphs, and applies OCR to verify that the rendered characters match their expected Unicode values.
The technical implementation involves several sophisticated components:
- A normalization function that standardizes text for comparison
- A character accuracy calculation using Levenshtein distance
- A font atlas generation system that renders glyphs side-by-side
- OCR-based validation against expected ASCII strings
This approach creates a defense-in-depth strategy where document processing systems can detect deceptive fonts while maintaining compatibility with legitimate embedded fonts. The testing demonstrates that this method successfully identifies malicious fonts like Noroboto while correctly validating legitimate fonts like Google's Noto.
The implications of this research extend far beyond the specific implementation in Tritium. As legal technology becomes increasingly AI-driven, the integrity of document processing pipelines becomes paramount. The Noroboto exploit reveals a fundamental vulnerability in systems that trust the visual representation of documents without independently verifying the underlying text representation.
Perhaps most concerning is the democratization of such attack techniques. The researchers note that even consumer-grade language models can engineer these attacks with minimal guidance, suggesting that the barrier to implementing such exploits is lowering. This creates an asymmetric threat landscape where malicious actors can leverage increasingly accessible AI tools to manipulate legal documents, while defenders must implement more sophisticated validation mechanisms.
The legal consequences of such attacks could be profound. Consider a scenario where a jurisdictional clause in a contract appears to specify one jurisdiction while actually specifying another, or where financial terms are altered in ways that might not be immediately apparent to human reviewers. Such manipulations could have significant financial and legal ramifications, particularly in high-stakes negotiations or litigious environments.
The Tritium mitigation approach represents one potential path forward, but it is not without limitations. The current implementation focuses on ASCII characters and may not catch all sophisticated attacks. Moreover, the computational overhead of OCR validation could be problematic for processing large volumes of documents. Future improvements might include more sophisticated validation techniques, integration with document processing pipelines at earlier stages, and machine learning-based detection of suspicious font patterns.
As the legal technology landscape continues to evolve, the Noroboto research serves as an important reminder that as we delegate increasingly complex tasks to AI systems, we must maintain healthy skepticism about the data these systems process. The visual representation of documents, while important for human readability, should not be the sole basis for automated decision-making in legal contexts.
The researchers have made their proof-of-concept code available on GitHub, and a live demonstration can be viewed at noroboto.io. These resources, along with the technical details of the mitigation approach, provide valuable insights for both security researchers and legal technology developers working to document processing pipelines.
In conclusion, the Noroboto project reveals a fascinating intersection of typography, cryptography, and artificial intelligence in the context of legal technology. As document processing becomes increasingly automated, the integrity of the relationship between visual appearance and underlying text representation becomes a critical security consideration. The techniques described in this research, while concerning, also point toward the need for more robust validation mechanisms in the systems that process our most important legal documents.
Comments
Please log in or register to join the discussion