
A growing trend sees developers installing lightweight AI models like Gemma 3B locally using tools like Ollama, challenging cloud dependency while raising questions about practical applications.

In developer circles, a subtle shift is occurring: more technologists are installing AI models directly on their personal machines rather than relying solely on cloud APIs. Tools like Ollama simplify this process, enabling instant access to models like Google's Gemma 3B with minimal setup. This movement toward local AI execution represents both technological pragmatism and a quiet rebellion against cloud dependency.
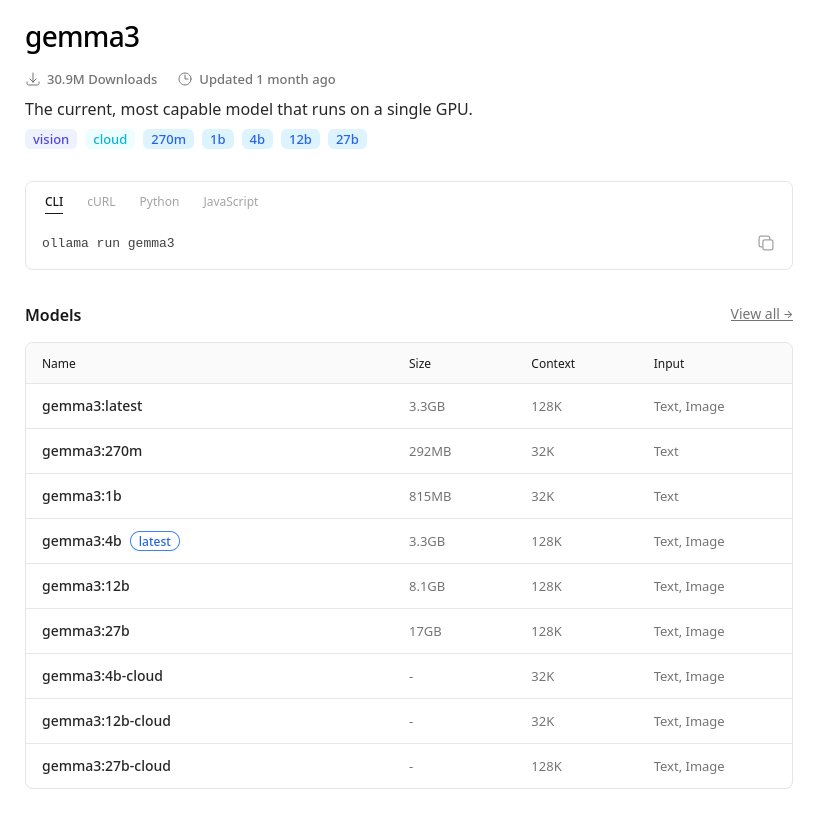
The appeal lies in Ollama's streamlined approach. With a single terminal command (curl -fsSL https://ollama.com/install.sh | sh), developers bypass complex environment configurations. Ollama's model library then provides access to optimized variants like gemma3:1b – specifically designed for resource-constrained environments. This 1.5-2GB RAM requirement makes it viable for standard laptops, addressing a key pain point for developers seeking immediate experimentation without infrastructure overhead.
Why this matters:
- Privacy Sovereignty: Sensitive data never leaves local machines
- Cost Elimination: Zero cloud compute expenses for prototyping
- Reduced Latency: Sub-second responses for interactive workflows
- Offline Capability: Development continues without internet access
Yet skepticism persists. Critics note Gemma 3B's limitations compared to cloud behemoths like GPT-4 or Claude 3. Its smaller parameter count restricts complex reasoning capabilities, making it unsuitable for advanced tasks like legal analysis or multi-step coding assistance. As one ML engineer noted: 'It's fantastic for quick Q&A or text summarization, but don't expect doctoral thesis analysis.'
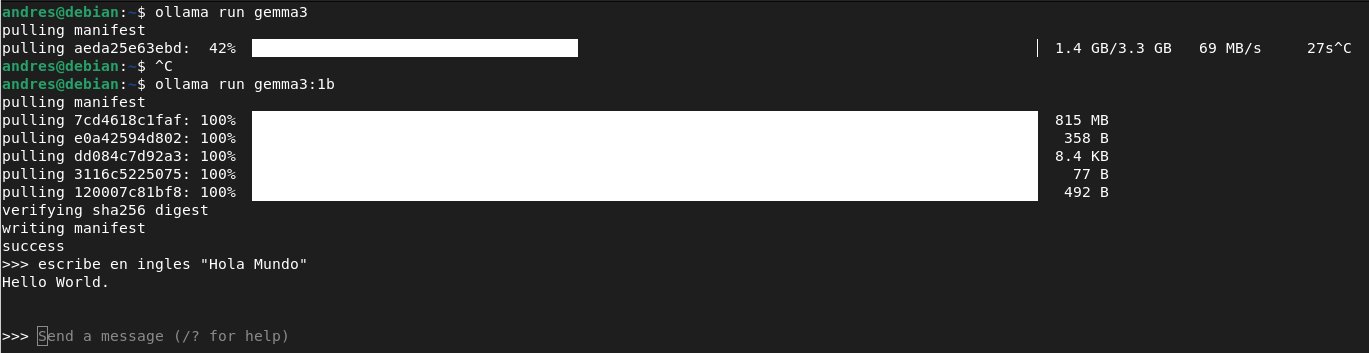
The installation workflow reveals thoughtful design choices. After installing Ollama, running ollama run gemma3:1b fetches the optimized model directly into a REPL interface. This immediacy lowers barriers – users interact with AI within minutes rather than wrestling with CUDA drivers or Python environments. Ollama's documentation emphasizes this simplicity, positioning it as a gateway tool rather than a production solution.
Adoption signals emerge from unexpected quarters:
- Educators running models on classroom Raspberry Pis
- Researchers preprocessing sensitive datasets offline
- Mobile developers prototyping on-device AI features
The trend reflects broader industry patterns. As noted in Ollama's documentation, their model optimizations prioritize CPU execution over GPU dependency – a deliberate choice for accessibility. Yet this democratization comes with tradeoffs. While Gemma 3B delivers impressive speed on modest hardware, its 1B parameter version lacks the nuance of larger models.
Counter-perspectives emerge:
- Cloud advocates argue hybrid approaches yield better results
- Privacy skeptics question if local execution truly enhances security
- Performance purists note quantization reduces model accuracy
As tools mature, the conversation evolves beyond installation simplicity. The real test lies in whether locally-run models can transition from curiosities to legitimate components in developer workflows. For now, Ollama and Gemma represent something profound: AI becoming tangible technology we control, not just consume.
Comments
Please log in or register to join the discussion