
Almog Gavra's systematic approach to database evaluation reveals how amplification metrics, PACELC constraints, and LCD tradeoffs shape modern data systems.
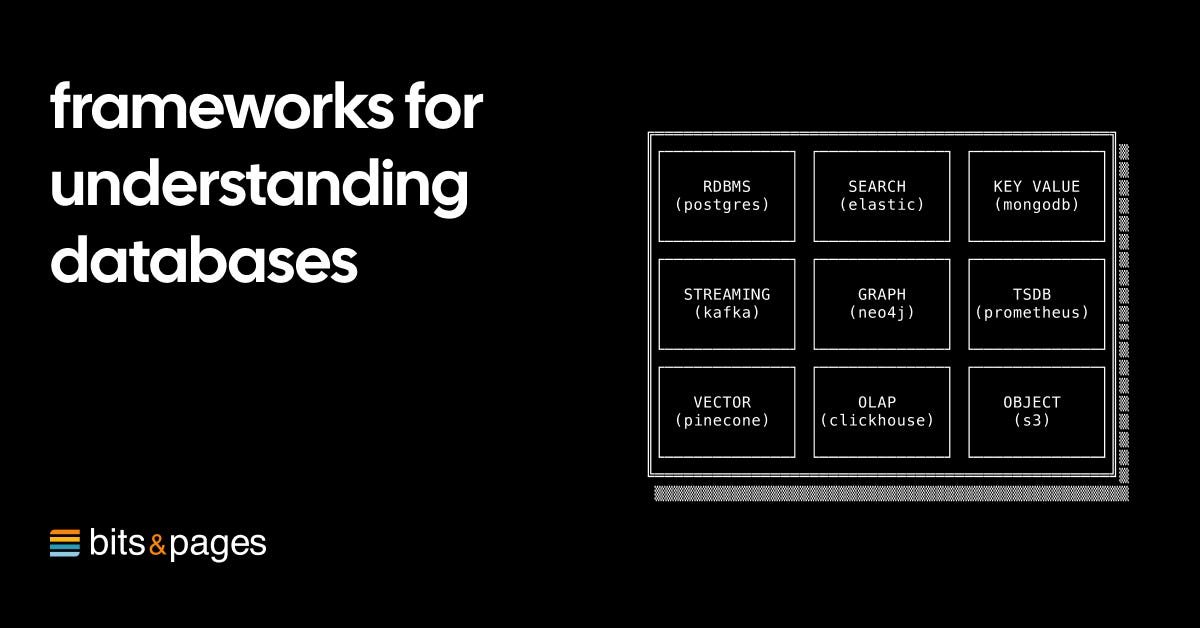
In an era where database technologies proliferate across specialized domains—from vector databases for AI to time-series systems for IoT—understanding their fundamental tradeoffs becomes increasingly critical. Almog Gavra's recent analysis provides engineers with a structured framework for evaluating database systems through three interdependent dimensions: performance, availability, and durability. This systematic approach transcends vendor-specific implementations to reveal universal architectural patterns.
The Performance Triad: Amplification Metrics
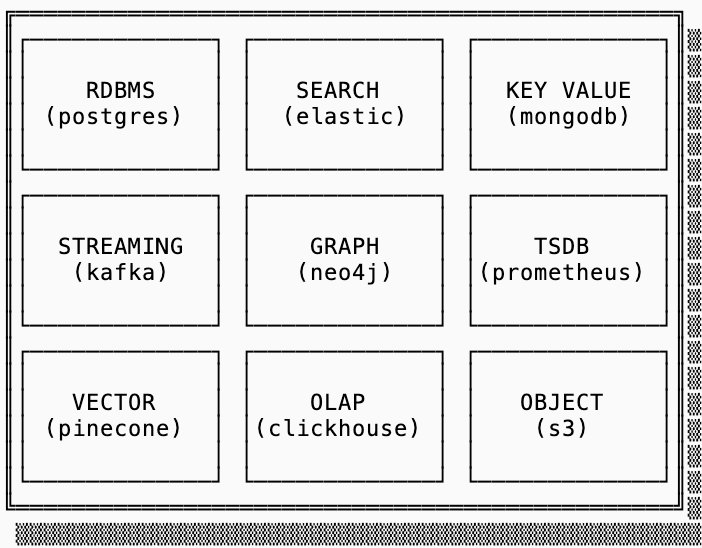 At the heart of performance analysis lies the quantification of amplification effects:
At the heart of performance analysis lies the quantification of amplification effects:
- Read amplification measures excess data scanned per query, particularly evident in write-optimized systems
- Write amplification quantifies overhead from index maintenance and compaction cycles
- Space amplification captures storage inefficiencies from fragmentation or redundant copies
These metrics directly connect to the RUM Conjecture, which posits that no index structure can simultaneously optimize for Read overhead, Update cost, and Memory utilization. Systems must consciously sacrifice one dimension to enhance others—a foundational tradeoff governing storage engine design.
Data orientation further complicates performance decisions. Row-based storage (e.g., PostgreSQL) minimizes read amplification for entire-row retrieval but suffers during columnar aggregation. Conversely, columnar systems (e.g., ClickHouse) enable vectorized operations via SIMD yet incur massive read amplification when reconstructing complete rows. Gavra illustrates this with a striking example: reconstructing a single 16KB row in a columnar system can trigger over 100x read amplification versus 4x in row-oriented storage.
Availability Architecture Matrix
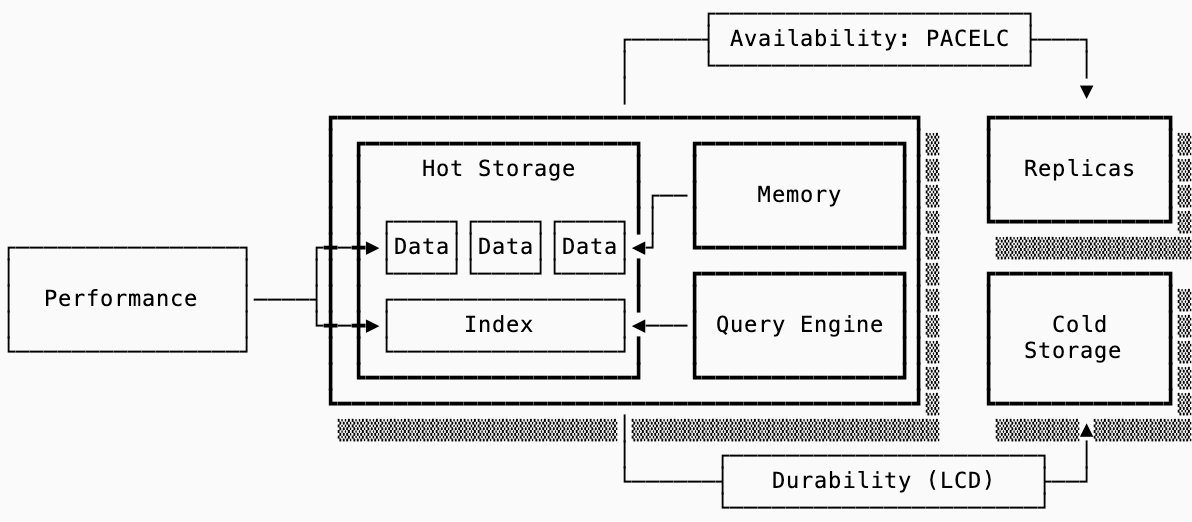 The analysis extends beyond performance to distributed system behaviors through the PACELC framework:
The analysis extends beyond performance to distributed system behaviors through the PACELC framework:
- During network partitions (P), systems choose between availability and consistency (CAP)
- Elsewhere (E), they trade latency (L) against consistency (C)
This framework contextualizes deployment architectures:
| Coordination | Coupled Storage | Disaggregated Storage |
|---|---|---|
| Single Writer | SQLite | SlateDB |
| Leader/Follower | Kafka | Warpstream |
| Leaderless | ScyllaDB | Quickwit |
Leader-based systems prioritize consistency at the cost of failover delays, while leaderless architectures favor availability through quorum-based writes. Disaggregation (offloading persistence to object storage) further reshapes these dynamics by separating compute scaling from data durability concerns.
The Durability Trilemma
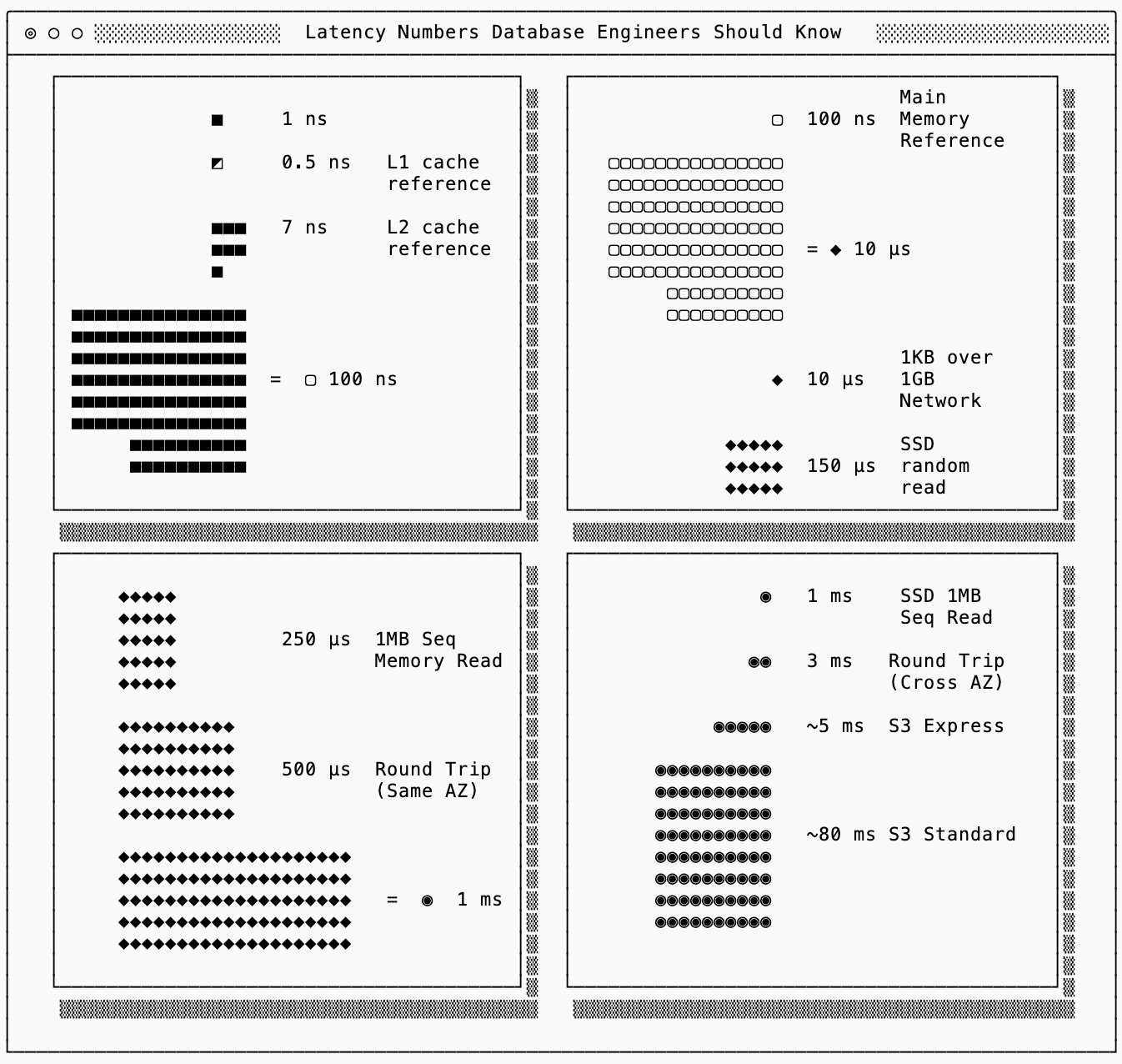 Cloud-native infrastructure introduces Gavra's LCD framework for durability: the impossibility of simultaneously optimizing Latency, Cost, and Durability. Storage choices reveal concrete manifestations of this trilemma:
Cloud-native infrastructure introduces Gavra's LCD framework for durability: the impossibility of simultaneously optimizing Latency, Cost, and Durability. Storage choices reveal concrete manifestations of this trilemma:
- In-memory only: Near-zero latency but zero durability
- Local disk: Moderate latency/cost with single-node durability
- Multi-zone replication: Higher latency/cost for failure-domain tolerance
Write-ahead logs (WALs) exemplify purposeful tradeoffs within this model. By persisting unprocessed writes immediately, systems accept higher write amplification (cost) to achieve lower-latency durability guarantees—an intentional optimization favoring UM (update/memory efficiency) in the RUM spectrum.
Implications for Engineering Practice
This systematic framework enables more informed technology selection:
- Workload alignment: Map query patterns to data orientation (row vs. columnar) to minimize amplification
- Failure modeling: Use PACELC to evaluate consistency requirements against availability needs
- Durability budgeting: Apply LCD principles to storage tiering strategies
As Gavra notes, few applications genuinely require more than 99.9% availability (~8.8 hours annual downtime)—a crucial reminder that over-engineering for theoretical failures often outweighs practical benefits. The forthcoming series on specific database types promises to apply this framework to concrete implementations, offering engineers a rare lens into the intentional compromises shaping modern data infrastructure.
For foundational knowledge, Gavra recommends the seminal Designing Data-Intensive Applications (updated edition forthcoming), while his future installments will examine key-value stores through this evaluative lens.
Comments
Please log in or register to join the discussion