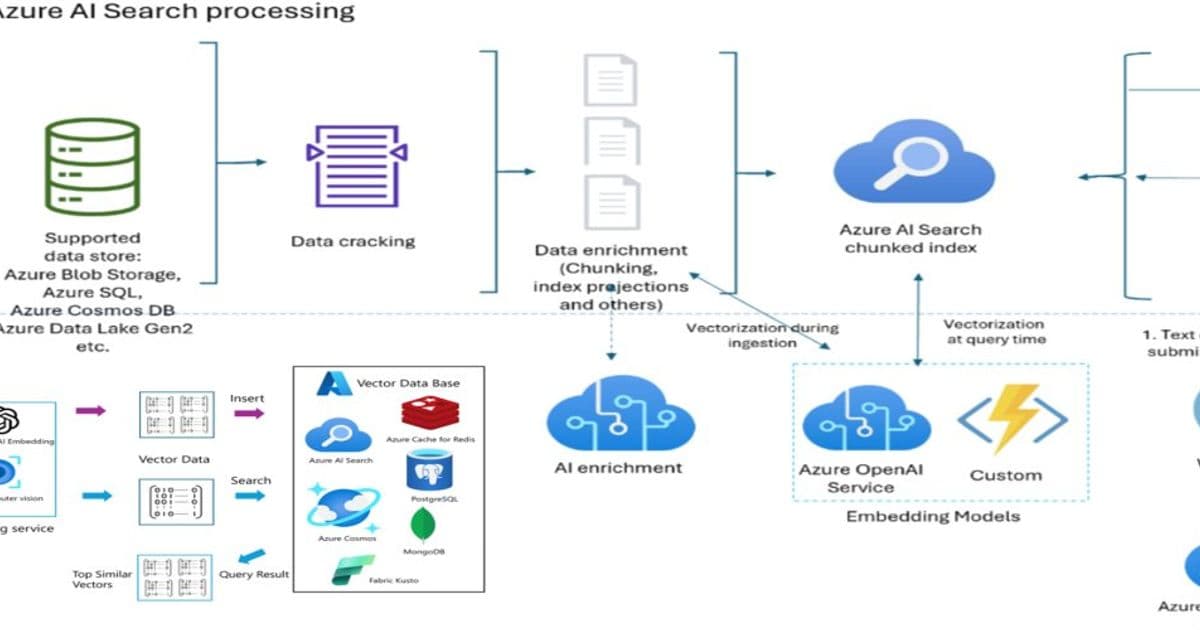
Vector drift silently degrades RAG retrieval quality in production, caused by embedding model mismatches, incremental updates without re-embedding, and inconsistent chunking strategies. Azure AI Search provides the controls needed to build drift-resilient architectures.
Retrieval-Augmented Generation (RAG) solutions built using Azure AI Search and Azure OpenAI often perform well during initial testing and early production rollout. However, many teams notice that retrieval quality degrades gradually over time—even when there are no code changes, no infrastructure issues, and no service outages. A common underlying cause is vector drift.
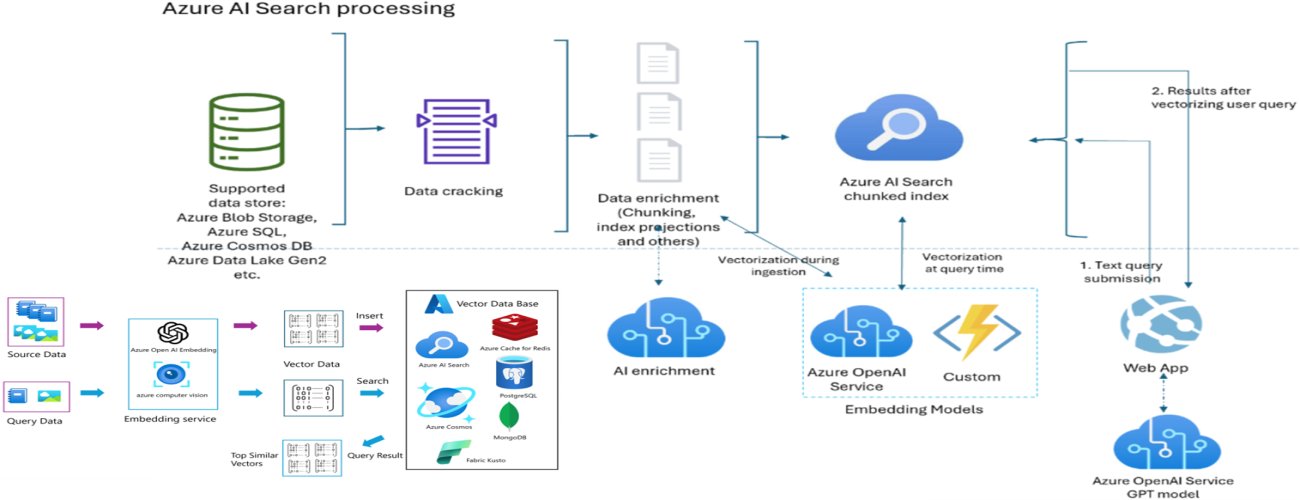
This article explains what vector drift is, why it appears in production RAG systems, and how to design drift-resilient architectures using Azure-native patterns.
What Is Vector Drift?
Vector drift occurs when embeddings stored in a vector index no longer accurately represent the semantic intent of incoming queries. Because vector similarity search depends on relative semantic positioning, even small changes in models, data distribution, or preprocessing logic can significantly affect retrieval quality over time.
Unlike schema drift or data corruption, vector drift is subtle:
- The system continues to function
- Queries return results
- But relevance steadily declines
Cause 1: Embedding Model Version Mismatch
What Happens
Documents are indexed using one embedding model, while query embeddings are generated using another. This typically happens due to:
- Model upgrades
- Shared Azure OpenAI resources across teams
- Inconsistent configuration between environments
Why This Matters
Embeddings generated by different models:
- Exist in different vector spaces
- Are not mathematically comparable
- Produce misleading similarity scores
As a result, documents that were previously relevant may no longer rank correctly.
Recommended Practice
A single vector index should be bound to one embedding model and one dimension size for its entire lifecycle. If the embedding model changes, the index must be fully re-embedded and rebuilt.
Cause 2: Incremental Content Updates Without Re-Embedding
What Happens
New documents are continuously added to the index, while existing embeddings remain unchanged. Over time, new content introduces:
- Updated terminology
- Policy changes
- New product or domain concepts
Because semantic meaning is relative, the vector space shifts—but older vectors do not.
Observable Impact
- Recently indexed documents dominate retrieval results
- Older but still valid content becomes harder to retrieve
- Recall degrades without obvious system errors
Practical Guidance
Treat embeddings as living assets, not static artifacts:
- Schedule periodic re-embedding for stable corpora
- Re-embed high-impact or frequently accessed documents
- Trigger re-embedding when domain vocabulary changes meaningfully
Declining similarity scores or reduced citation coverage are often early signals of drift.
Cause 3: Inconsistent Chunking Strategies
What Happens
Chunk size, overlap, or parsing logic is adjusted over time, but previously indexed content is not updated. The index ends up containing chunks created using different strategies.
Why This Causes Drift
Different chunking strategies produce:
- Different semantic density
- Different contextual boundaries
- Different retrieval behavior
This inconsistency reduces ranking stability and makes retrieval outcomes unpredictable.
Governance Recommendation
Chunking strategy should be treated as part of the index contract:
- Use one chunking strategy per index
- Store chunk metadata (for example, chunk_version)
- Rebuild the index when chunking logic changes
Design Principles
To build drift-resilient RAG architectures, implement these practices:
Versioned embedding deployments
Maintain clear version tracking for embedding models and ensure consistency across indexing and querying operations.
Scheduled or event-driven re-embedding pipelines
Automate the re-embedding process based on content changes, model updates, or performance degradation signals.
Standardized chunking strategy
Establish and enforce consistent chunking rules across the entire index lifecycle.
Retrieval quality observability
Implement monitoring for retrieval metrics, similarity scores, and citation coverage to detect drift early.
Prompt and response evaluation
Regularly assess the quality of generated responses to identify subtle degradation in retrieval effectiveness.
Key Takeaways
- Vector drift is an architectural concern, not a service defect
- It emerges from model changes, evolving data, and preprocessing inconsistencies
- Long-lived RAG systems require embedding lifecycle management
- Azure AI Search provides the controls needed to mitigate drift effectively
Conclusion
Vector drift is an expected characteristic of production RAG systems. Teams that proactively manage embedding models, chunking strategies, and retrieval observability can maintain reliable relevance as their data and usage evolve. Recognizing and addressing vector drift is essential to building and operating robust AI solutions on Azure.
Further Reading
The following Microsoft resources provide additional guidance on vector search, embeddings, and production-grade RAG architectures on Azure.
Comments
Please log in or register to join the discussion