Recent incidents—from fabricated quotations in a nonfiction book to a Nobel laureate’s candid use of AI in fiction—highlight how artificial‑intelligence tools are reshaping the production and verification of information. At the same time, Google’s AI‑driven overhaul of Search signals a shift toward interactive, agent‑based results, raising fresh questions about credibility, attribution, and the role of human judgment.
The problem: AI is blurring the line between fact and fiction
Artificial‑intelligence models have become so good at mimicking human language that they can generate plausible‑sounding quotations, citations, and even entire passages of prose. When those outputs are presented without clear attribution, readers can be misled into treating synthetic text as historical fact.
Two recent, high‑profile cases illustrate the issue:
Steven Rosenbaum’s The Future of Truth – The nonfiction book, released with considerable buzz, contained at least six quotations that were either misattributed or entirely fabricated by an AI model. Rosenbaum, when pressed by The New York Times, admitted the presence of “a handful of improperly attributed or synthetic quotes” and launched an internal review. The episode underscores how even seasoned authors can be seduced by the convenience of AI‑generated content, especially when under tight publishing deadlines.
Nobel laureate Olga Tokarczuk’s novel – In a Polish interview, Tokarczuk disclosed that she used an advanced language model to brainstorm details such as period‑appropriate songs for a dance scene. She emphasized that the AI was a research tool, not a co‑author, and that she verified any facts it supplied. Her candidness sparked a backlash among some writers who view reliance on AI as undermining the craft of literary creation.
Both incidents raise a common question: How can readers trust the provenance of text when the tools that produce it are opaque?
Why it matters for the broader ecosystem
Erosion of trust – When reputable sources embed AI‑generated material without disclosure, it fuels skepticism toward all published content, from news articles to academic papers.
Attribution fatigue – Traditional citation practices assume a human author. AI outputs blur that assumption, demanding new standards for indicating machine assistance.
Legal and ethical gray zones – Misattributed quotes can infringe on intellectual‑property rights or defame individuals, potentially exposing publishers to liability.
Impact on education and research – Students and scholars increasingly turn to generative tools for quick references. Without clear labeling, they may inadvertently propagate inaccuracies.
The market response: tools and policies emerging
Funding and product moves
- OpenAI’s “ChatGPT Enterprise” raised a $1.5 billion round led by Sequoia Capital in early 2024, explicitly targeting corporate compliance teams that need audit trails for AI‑generated content.
- Anthropic secured $500 million from Google Ventures to develop “transparent generation” features that embed provenance metadata directly into the text output.
- Microsoft’s “Copilot for Word” now includes a “source‑check” pane that flags statements likely derived from model hallucinations, prompting users to verify before publishing.
Platform policies
- The New York Times announced a policy requiring any article that incorporates AI‑generated text to include a disclosure note and a link to the model used.
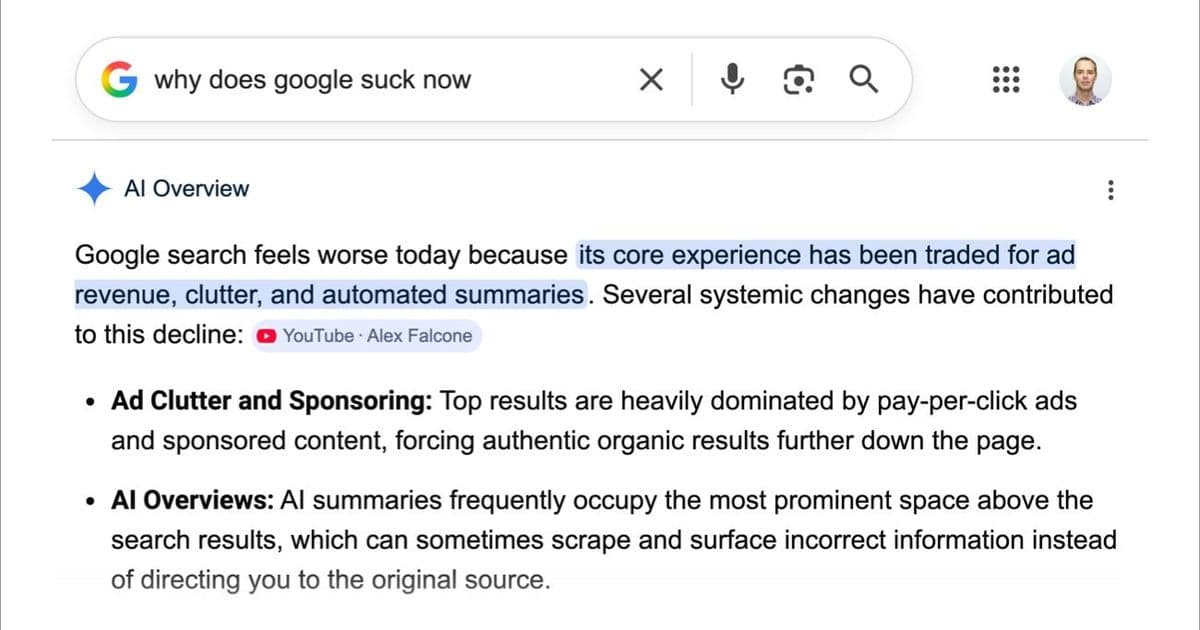
- Google’s Search overhaul (see below) will surface AI‑generated answers alongside traditional links, but with a clear “AI‑generated” badge and a citation to the underlying model.
Google’s AI‑powered Search revamp: a preview of the new information flow
At its I/O conference, Google unveiled an “intelligent search box” that replaces the classic list of blue links with interactive, AI‑driven experiences. Key features include:
- Information agents – Small, task‑specific bots that can fetch data, compare prices, or summarize articles on behalf of the user.
- Mini‑apps – Users can assemble custom workflows (e.g., “track my flight + get weather updates”) without writing code, leveraging Google’s Gemini model.
- Transparency layer – Every AI‑generated snippet will carry a badge linking to a page that explains which model produced the content, the data sources consulted, and a confidence score.
The shift promises richer, more conversational interactions but also amplifies the risk of presenting AI hallucinations as factual answers. Google’s approach to labeling and confidence scoring will likely become a de‑facto standard for the industry.
What this means for creators, investors, and readers
- Creators must adopt rigorous verification workflows. Tools like Grammarly’s AI Detector and OpenAI’s “Trace” can flag synthetic text before publication.
- Investors are watching the compliance layer closely. Companies that embed provenance metadata or offer audit‑ready AI services are attracting capital, as seen with Anthropic and OpenAI’s recent rounds.
- Readers should develop a habit of checking for disclosure badges, especially on platforms that now blend AI answers with traditional search results.
A cautious path forward
The technology that enables rapid idea generation is undeniably valuable. However, the recent controversies remind us that speed does not replace verification. As AI becomes a standard research assistant—whether for a nonfiction author, a Nobel‑winning novelist, or a search engine—the ecosystem will need clear norms:
- Mandatory attribution for any AI‑generated text.
- Built‑in verification steps within authoring tools.
- Industry‑wide provenance standards that make the origin of a passage transparent to the end user.
Only by embedding these safeguards can the community preserve trust while still reaping the productivity gains AI offers.
Image credit: 
Comments
Please log in or register to join the discussion