
Uber's HiveSync system manages 300+ petabytes of Hive data across regions, processing 5 million daily events with a 20-minute 99th percentile replication lag. Built on Airbnb's ReAir, it uses sharding, DAG orchestration, and a control/data plane separation to maintain cross-region consistency for disaster recovery while keeping secondary regions cost-effective.
Uber operates at a scale where data consistency across regions isn't just a nice-to-have—it's a survival requirement. Their HiveSync system, which manages approximately 300 petabytes of Hive data across data centers, processes over 5 million Hive DDL and DML events daily, replicating about 8 petabytes of data across regions. The system maintains a four-hour replication SLA with a 99th percentile lag of around 20 minutes, ensuring that Uber's analytics and ML pipelines can rely on consistent data regardless of which region they're running in.
The Problem: Idle Secondary Regions and Data Consistency
Before HiveSync, Uber's cross-region data strategy had two fundamental problems. First, secondary regions sat idle, incurring hardware costs equal to the primary region while providing no active value. Second, maintaining consistency between Hive and HDFS data across regions was manual and error-prone, making disaster recovery unreliable.
Uber's solution started with open-source foundations. They initially built on Airbnb's ReAir project, a batch replication system for Hive and HDFS. However, ReAir wasn't designed for Uber's scale or their specific requirements for near real-time consistency and disaster recovery.
HiveSync Architecture: Control Plane and Data Plane Separation
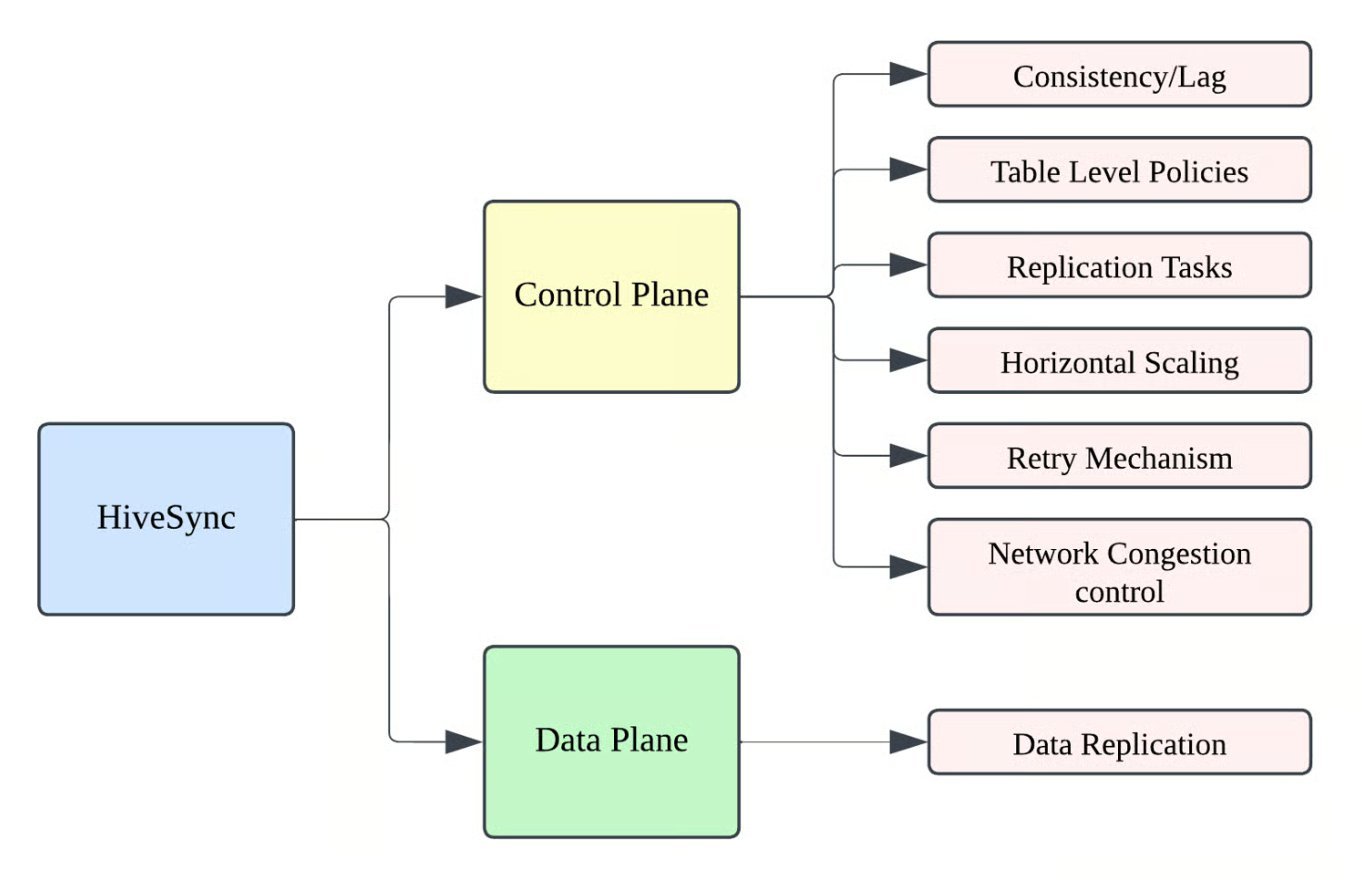
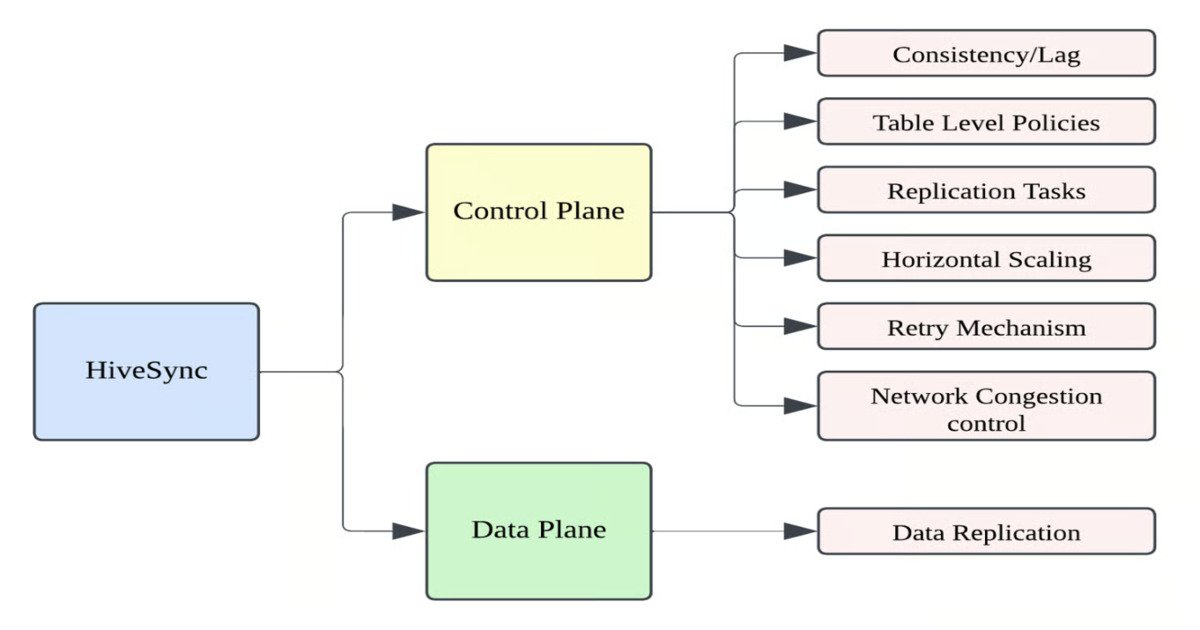
HiveSync's core architectural decision is the separation of control and data planes. The control plane orchestrates jobs and manages state in a relational metadata store (MySQL), while the data plane performs HDFS and Hive file operations.
Control Plane: Event-Driven Orchestration
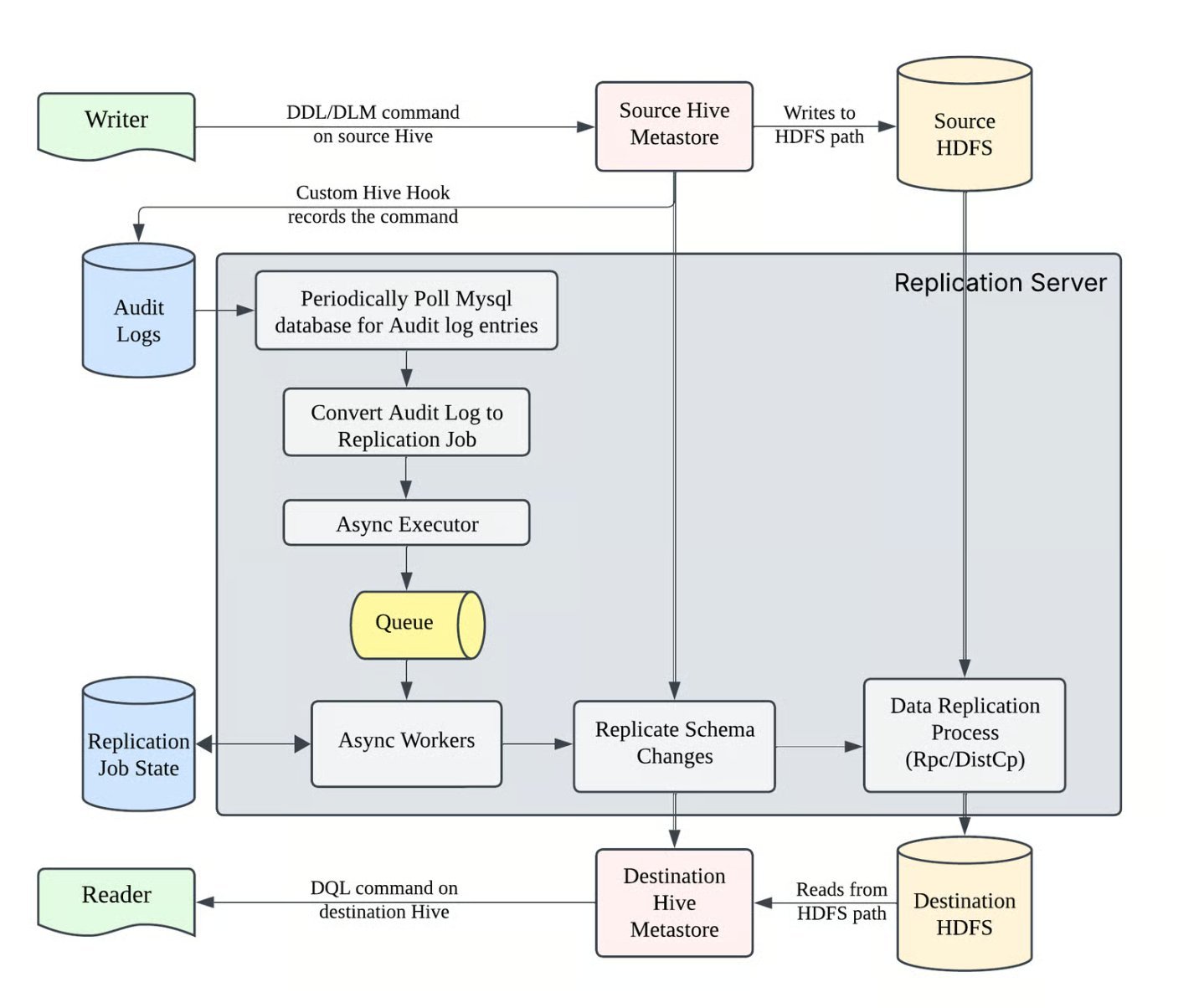
The control plane uses a Hive Metastore event listener to capture DDL and DML changes in real-time. When a table is created, altered, or data is inserted, the listener logs these events asynchronously to MySQL. These audit entries are then converted into asynchronous replication jobs.
Each job is represented as a finite-state machine with persisted states, enabling restartability and robust failure recovery. Uber uses a DAG manager to enforce shard-level ordering and locks, preventing race conditions during replication.
Data Plane: Hybrid Replication Strategy
The data plane handles the actual file movement. For efficiency, smaller jobs use RPC calls, while larger jobs leverage DistCp on YARN. This hybrid approach optimizes for both latency and throughput.
Sharding: Horizontal Scaling and Fault Tolerance
HiveSync's sharding mechanism is critical for handling Uber's scale. With 800,000 Hive tables ranging from a few gigabytes to tens of petabytes, and partitions per table varying from a few hundred to over a million, a monolithic replication system would be impossible to maintain.
Sharding allows tables and partitions to be divided into independent units for parallel replication. Each shard can be replicated independently, providing fine-grained fault tolerance. If one shard fails, it doesn't block replication of others.
Uber employs both static and dynamic sharding:
- Static sharding assigns tables to shards based on predictable patterns (e.g., by business domain or data size)
- Dynamic sharding allows the system to rebalance shards as data volumes change
This approach ensures horizontal scaling while maintaining conflict-free replication.
Data Reparo: Continuous Reconciliation
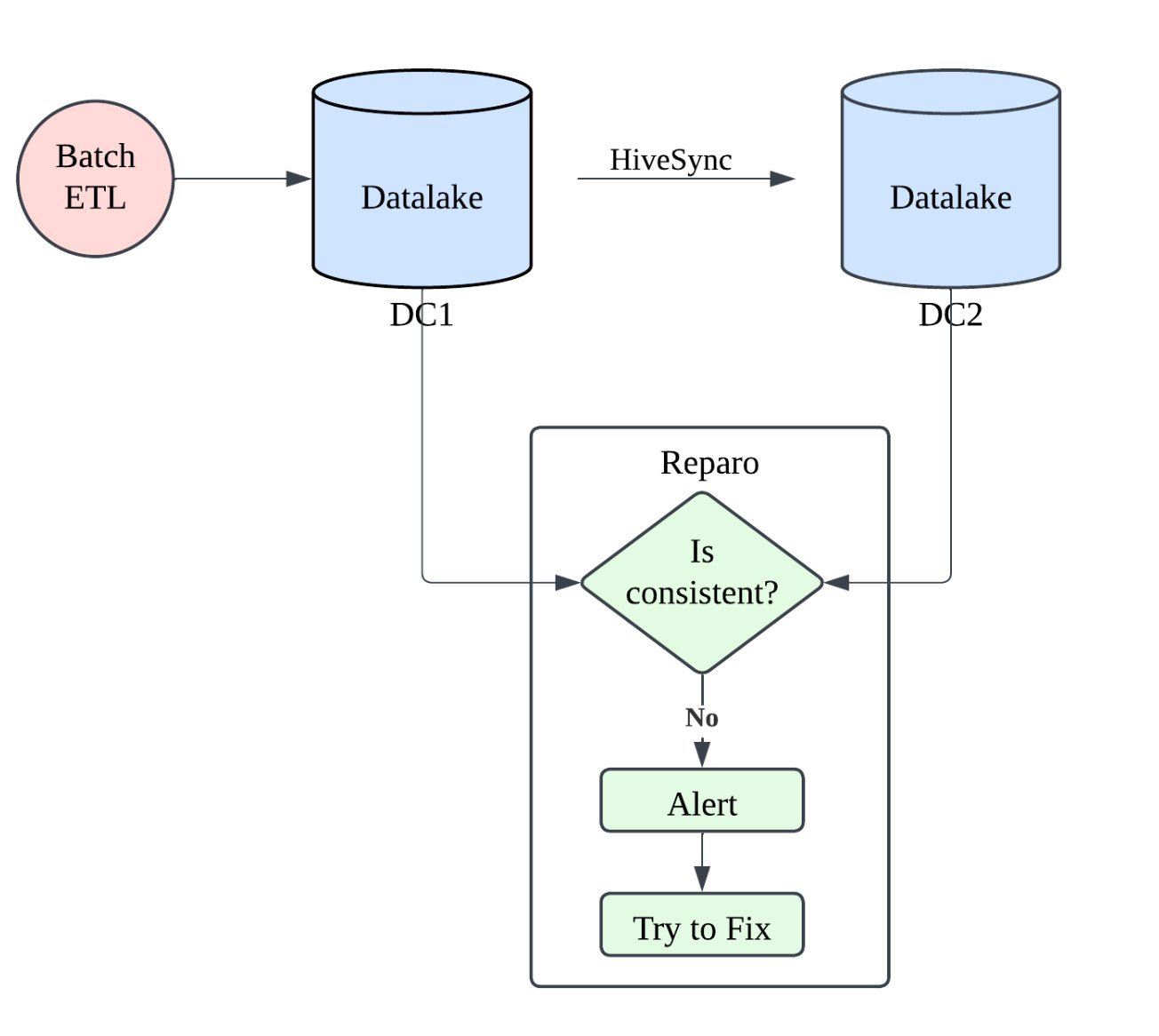
Even with robust replication, inconsistencies can occur due to network issues, out-of-band HDFS updates, or software bugs. Data Reparo is Uber's reconciliation service that continuously scans both data centers for anomalies.
Data Reparo detects:
- Missing partitions or tables
- Extra partitions or tables (indicating failed deletions)
- File-level inconsistencies (missing or corrupted files)
- Metadata mismatches
The service restores parity between DC1 and DC2, targeting over 99.99% accuracy. It runs continuously, ensuring that any drift is caught and corrected within hours.
Operational Metrics and SLAs
HiveSync operates at impressive scale:
- 800,000 Hive tables (300+ petabytes total)
- 5 million daily events (DDL/DML)
- 8 petabytes daily replication
- 20-minute 99th percentile lag
- 4-hour replication SLA
The system also supports one-time replication for bootstrapping historical datasets into new regions or clusters before switching to incremental replication.
Implementation Details
State Management
Each replication job is a finite state machine with states like:
PENDING: Job created, waiting for executionRUNNING: Currently executingSUCCESS: Completed successfullyFAILED: Failed, with retry logicRECOVERING: In recovery mode after failure
States are persisted to MySQL, allowing the system to recover from crashes and resume jobs from their last known state.
Conflict Resolution
When the same table is modified in both regions simultaneously (though rare in Uber's primary/secondary setup), HiveSync uses timestamps and sequence numbers to determine the correct order of operations. The DAG manager ensures that dependent operations execute in the correct sequence.
Monitoring and Observability
HiveSync emits detailed metrics for:
- Replication lag by shard and table
- Job success/failure rates
- Resource utilization (YARN containers, RPC calls)
- Data consistency checks from Data Reparo
These metrics feed into Uber's observability stack, enabling proactive issue detection.
Future Direction: Cloud Replication
Looking ahead, Uber plans to extend HiveSync for cloud replication use cases as batch analytics and ML pipelines migrate to Google Cloud. The same sharding, orchestration, and reconciliation mechanisms will be leveraged to maintain petabyte-scale data integrity across hybrid cloud environments.
Lessons for Practitioners
Start with open source, but extend for scale: ReAir provided a foundation, but Uber's specific requirements (near real-time consistency, disaster recovery, cost optimization) required significant extensions.
Separate control and data planes: This architectural pattern enables independent scaling and failure isolation. The control plane can be lightweight and highly available, while the data plane can be optimized for throughput.
Shard early, shard often: At Uber's scale, sharding isn't optional. It provides both horizontal scaling and fault tolerance.
Continuous reconciliation is essential: Replication alone isn't enough. You need active reconciliation to handle the inevitable inconsistencies that occur in distributed systems.
Design for restartability: With millions of events daily, failures are guaranteed. Finite-state machines with persisted state enable automatic recovery without manual intervention.
HiveSync demonstrates how large-scale data systems can maintain consistency across regions while keeping secondary regions cost-effective. The combination of sharding, DAG orchestration, and continuous reconciliation provides a robust foundation for disaster recovery at petabyte scale.
For more details, see Uber's engineering blog post on HiveSync, and explore the ReAir project that inspired the initial implementation.
Comments
Please log in or register to join the discussion