Modern SaaS platforms must treat AI agents as distributed backend services, not product features, to ensure production reliability and scalability.
How modern SaaS platforms must design APIs, workflows, and services to support production AI agents
The Demo-to-Production Gap
Most AI agents that fail in production don't fail because of the model. They fail silently — during a payment workflow, inside an async job queue, halfway through a tool call that had no retry logic. By the time the team investigates, the prompt engineering looks fine. The model outputs look reasonable. The failure is somewhere in the plumbing.
This is the problem that doesn't show up in demos. Controlled environments, predictable prompts, and a single user hide what production exposes immediately — that AI agents behave less like features and more like distributed backend services. They introduce long-running processes, unpredictable latency, external tool dependencies, and complex orchestration logic. At scale, this becomes an architecture problem before it becomes anything else.
Teams that successfully deploy AI agents at scale typically rely on API-first design, decoupled services, and asynchronous processing patterns to manage these new workload characteristics. Understanding this architectural shift is becoming essential for SaaS companies adopting AI-driven capabilities.
To understand why architecture matters, we must first understand how AI agents actually behave inside modern SaaS systems.
AI Agents Are Backend Systems, Not Product Features
One of the most common mistakes teams make is treating AI agents as product features rather than infrastructure components. From a system design perspective, an AI agent behaves much closer to a backend orchestration service than a UI feature. It coordinates workflows, calls tools, processes data, and makes decisions across multiple services.
A typical AI agent workflow might involve:
• Receiving a user request • Interpreting intent • Planning tasks • Calling internal APIs • Calling external APIs • Accessing knowledge bases • Managing state or memory • Assembling a response
This behavior resembles a workflow engine or orchestration service more than a traditional application feature. From an architectural viewpoint, an AI agent is essentially:
An orchestration layer that coordinates multiple services through APIs.
This means it introduces characteristics similar to distributed systems:
• Variable latency • Partial failures • Retry requirements • Dependency chains • Observability needs • Cost implications
If these characteristics are not accounted for in system design, AI quickly becomes a source of instability rather than innovation.
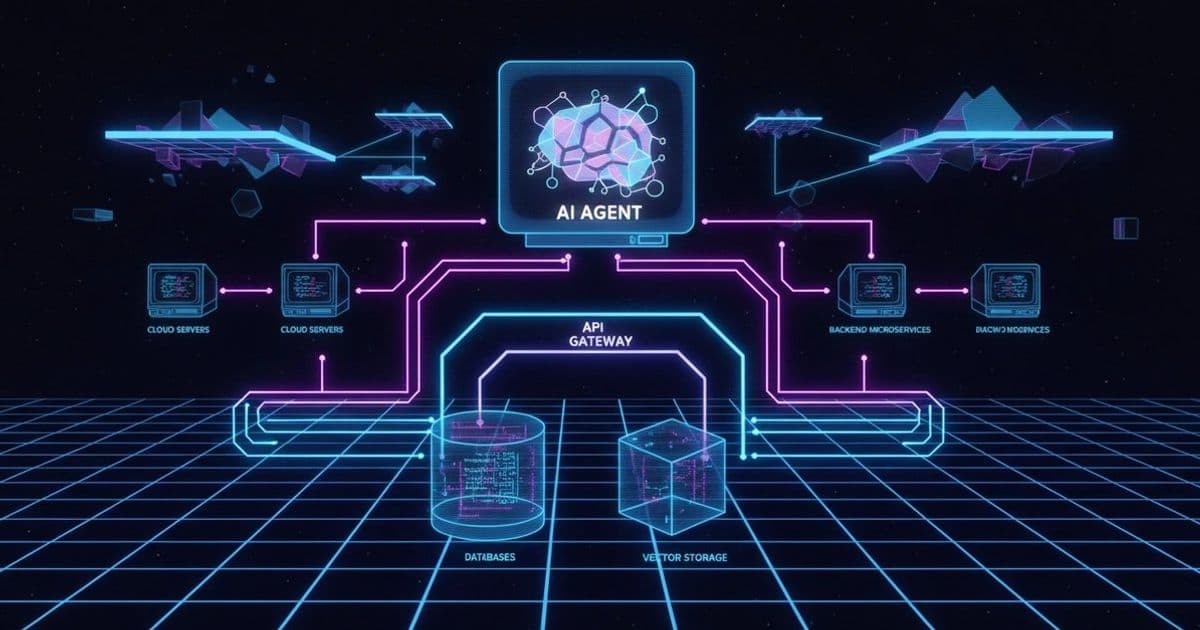
A simplified production AI agent architecture typically looks like this:
User Request ↓ API Gateway ↓ Agent Service ↓ Tool Services (Search, CRM, Payments, Internal APIs) ↓ Vector Database / Knowledge Store ↓ Response Aggregation Layer ↓ Final Response
This structure highlights an important reality: AI agents depend heavily on well-designed APIs. Without stable interfaces, the entire system becomes fragile.
Why API-First Architecture Becomes Critical
As AI agents increasingly act as orchestrators, APIs become the most important structural component of AI-driven SaaS systems. API-first architecture means designing services around clear, stable interfaces rather than tightly coupled internal logic. This approach allows AI agents to interact with systems predictably and safely.
Key benefits include:
Loose coupling Agents should interact with services through contracts, not internal logic. This prevents system breakage when services evolve.
Service discoverability Well-documented APIs allow agents to integrate tools consistently rather than relying on brittle integrations.
System scalability Independent services allow AI workloads to scale without affecting core application functionality.
Integration flexibility AI agents frequently require access to multiple systems. API-first design makes integration practical rather than risky.
Without API-first thinking, teams often encounter problems such as:
• Hardcoded integrations • Tight coupling between AI logic and product services • Difficult refactoring • Performance bottlenecks • Unpredictable failures
In many failing AI implementations, the core issue is not AI capability — it is integration fragility. An API-first architecture turns AI agents into structured system participants rather than experimental add-ons.
Architectural Patterns That Support Production AI Agents
Successfully deploying AI agents requires adopting patterns already familiar in distributed system design. The difference is that AI workloads make these patterns mandatory rather than optional. Some of the most important patterns include:
Asynchronous Processing AI tasks often take seconds or minutes rather than milliseconds. Treating them as synchronous requests creates bottlenecks. Better approaches include:
• Job queues • Event-driven processing • Background workers • Status polling patterns
Instead of:
User request → AI response immediately
Use:
User request → Job creation → Processing → Result delivery
This prevents user experience degradation and protects system stability.
Service Isolation AI workloads should not compete with core business operations. Separating AI compute from critical systems prevents situations where increased AI usage affects:
• Authentication services • Payment processing • Core APIs • User dashboards
A common approach is isolating AI into dedicated services:
Core SaaS services ↓ AI orchestration service ↓ AI processing workers
This protects reliability.
Tool Abstraction Layer AI agents should interact with tools through standardized interfaces rather than direct service logic. Instead of:
Agent → Direct database logic Agent → Direct internal code calls
Prefer:
Agent → Tool interface → Service
This allows:
Tool swapping Service evolution Better testing Safer integrations
This is similar to dependency inversion principles used in software architecture.
Observability and Monitoring AI introduces non-deterministic behavior. Without observability, debugging becomes extremely difficult. AI systems should include:
Structured logging Tracing Execution history Cost tracking Failure monitoring
Without this, teams cannot answer basic questions such as:
Why did this agent make this decision? What failed? Where did latency occur?
Observability is not optional in AI systems — it is foundational.
Common Architecture Mistakes in AI SaaS Products
Many AI projects struggle not because of model limitations, but because of predictable architecture mistakes. Some of the most common include:
Treating AI requests as synchronous transactions AI calls can take seconds or minutes. Treating them like normal API calls creates timeouts and poor user experience.
Tight coupling to a single LLM provider Hardcoding logic around a single provider increases risk. Abstraction layers allow switching providers when needed.
Ignoring cost scaling AI usage costs grow with volume. Systems should include cost awareness and throttling mechanisms.
No fallback design AI can fail. Systems must include:
Retries Fallback responses Graceful degradation
Lack of retry strategies External API failures are common. AI workflows must assume failure and plan accordingly.
No workflow state management Complex agents require state tracking across steps. Without this, reliability suffers.
These mistakes are rarely AI problems. They are architecture discipline problems.
Example: AI-Powered Contract Review for a B2B SaaS
Consider a mid-stage B2B SaaS that adds an AI contract review feature for legal and procurement teams. Initial demos are clean — upload a PDF, get a structured risk summary in seconds. In production, the architecture breaks down fast.
Contracts range from 4 pages to 400. Processing time swings from 3 seconds to 4 minutes. The team built the feature synchronously — the API gateway holds the connection open while the agent processes the document. At 20 concurrent users, response times degrade across the entire platform. The payment service starts timing out. Support tickets spike.
The AI model performed exactly as expected. The system around it did not.
A production-ready architecture for this system looks different:
User uploads contract ↓ API gateway accepts request, returns job ID immediately ↓ Document stored, job queued ↓ Agent service picks up job asynchronously ↓ Chunking service splits large documents ↓ Processing workers extract clauses in parallel ↓ Vector store holds context across chunks ↓ Agent synthesizes risk summary ↓ Result stored, webhook notifies client
Key decisions that make this reliable:
Async from the first request — the gateway never holds a connection. The client polls or receives a webhook. This decouples user experience from processing time entirely.
Chunking as a dedicated service — document size variability is handled at the infrastructure level, not inside prompt logic.
Parallel processing workers — large documents don't block the queue. Workers scale independently.
Webhook delivery — the client is notified on completion rather than waiting. Standard distributed systems pattern applied directly to AI workload.
The AI contributes maybe 30% of what makes this system reliable. The other 70% is architecture discipline.
Design Principles for Production AI Systems
Based on emerging patterns across AI SaaS implementations, several design principles are becoming clear.
Design for latency AI is slow compared to traditional services. Systems must assume delay.
Design for failure External APIs fail. Models fail. Networks fail. Systems must assume partial failure.
Design for cost AI costs scale with usage. Efficient orchestration matters.
Design for observability AI must be explainable operationally even if not logically.
Design for evolution AI technology changes rapidly. Systems must allow adaptation.
Teams that follow these principles treat AI as infrastructure rather than experimentation.
Conclusion: AI Success Is an Architecture Discipline
The companies shipping reliable AI products in production are not always working with the most advanced models. In many cases, they are working with the same foundation models as everyone else. What separates them is engineering discipline applied before the AI was ever integrated.
Prompt engineering produces demos. API design, service isolation, async patterns, and observability produce systems that hold under real conditions — variable load, partial failures, cost pressure, and users who don't behave the way controlled tests assumed.
AI agents are not intelligence layers dropped into existing products. They are infrastructure participants with the same failure characteristics as any distributed service — and they demand the same design rigor.
The teams that understand this early build products that scale. The teams that don't spend months debugging failures that were never really about the AI.
Architecture decides. It always has.

About the author
Technical content writer specializing in SaaS architecture, backend systems, and AI agents. Writes about APIs, microservices, distributed systems, and the engineering realities behind production AI.
Comments
Please log in or register to join the discussion