An autonomous research loop applied to CPU design achieved remarkable results, outperforming human-optimized architectures by discovering microarchitectural improvements that increased performance by 92% in under ten hours.
When AI Meets Silicon: Auto-Arch Tournament's 92% CPU Performance Leap
What happens when you take an autonomous research loop out of its comfort zone and point it at a domain it has no business being good at? That's the question FeSens sought to answer with their auto-arch-tournament project, which applied AI agents to optimize CPU architecture with surprising results.
The Challenge: Beyond AI's Comfort Zone
Andrej Karpathy's autoresearch demonstrated that a coding agent, given just two days and a single-GPU setup, could find 20 training-time optimizations on its own. The recipe—propose, implement, measure, keep the wins—proved effective within Python's ecosystem, where gradient descent and well-known knobs provide familiar territory.
"I wanted to know if it generalized," explains the project's creator. "So I pointed it at a CPU."
The Auto-Arch Tournament System
The auto-arch-tournament is built around a 5-stage in-order RV32IM core written in SystemVerilog—the textbook pipeline you'd find in a graduate architecture class. Initially, it had no caches, no branch predictor, and no multi-issue capabilities. These weren't missing features but research hypotheses to be tested.
The system operates through a carefully orchestrated loop with three parallel slots running each round:
- Hypothesis Generation: The AI proposes microarchitectural changes as YAML, validated against schemas/hypothesis.schema.json
- Implementation: An implementation agent edits files under rtl/ in an isolated git worktree
- Evaluation: A comprehensive verification process that includes:
- RISC-V formal verification (53 symbolic BMC checks covering decode, traps, ordering, liveness, and M-extension)
- Verilator co-simulation against a Python ISS with ~22% random bus stalls
- 3-seed nextpnr P&R on a Gowin GW2A-LV18 (Tang Nano 20K)
- CoreMark CRC validation against canonical values
A diversity rotation forces each slot to pick a different optimization category (micro_opt | structural | predictor | memory | extension), preventing the agent from fixating on a single approach.
The Results: AI Outperforms Human Design
The baseline was locked at the same methodology VexRiscv publishes—full no cache, 2K data, -O3 optimization—achieving 2.23 CoreMark/MHz and 301 iterations per second. For comparison, VexRiscv's published human-optimized version reached 2.57 CoreMark/MHz at 144 MHz.
After running 73 hypotheses in just 9 hours and 51 minutes of wall-clock time, the system achieved remarkable results:
- End state: 2.91 CoreMark/MHz, 577 iterations/s, 199 MHz maximum frequency, 5,944 LUTs
- This represents a +92% improvement over the locked baseline and +56% over VexRiscv in iterations per second
- The final design used 40% fewer LUTs while achieving a higher clock frequency
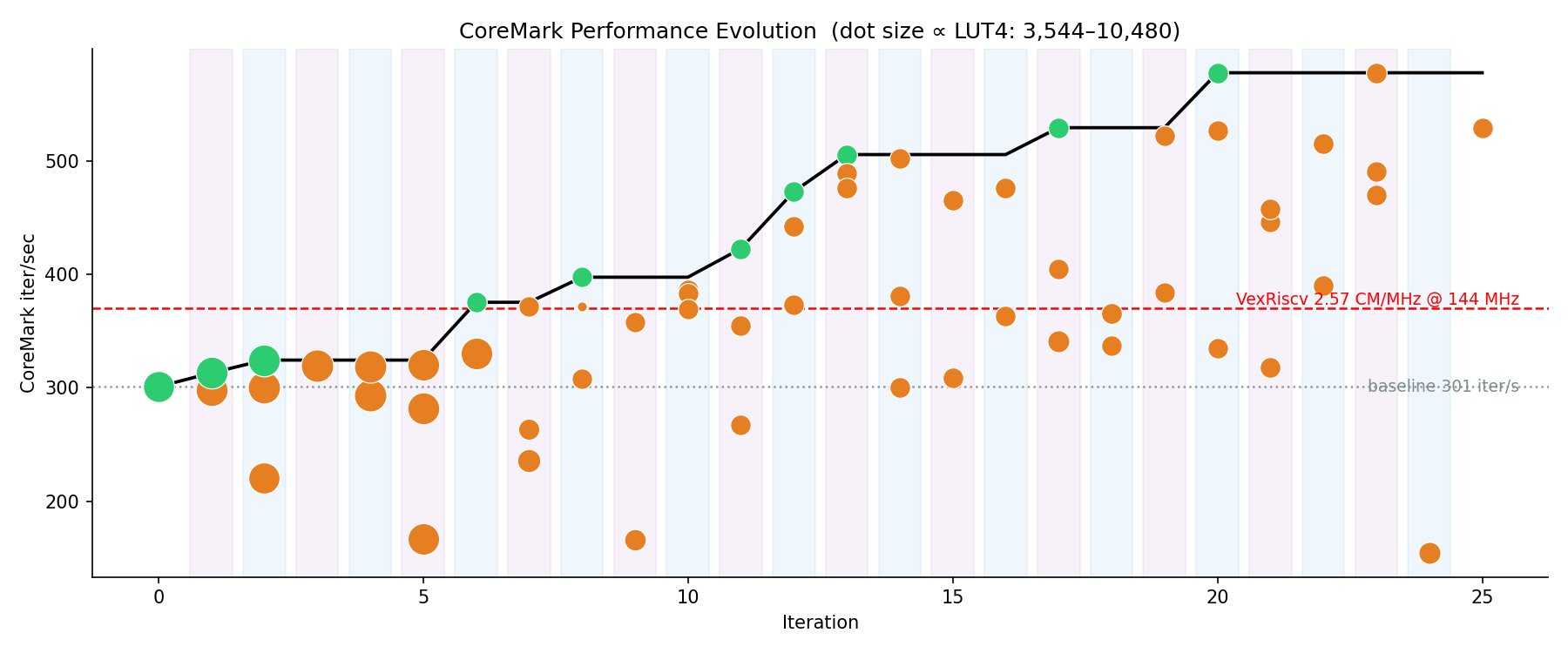 CoreMark progress throughout the tournament, with green dots showing accepted improvements and the black step-line tracking the best performance
CoreMark progress throughout the tournament, with green dots showing accepted improvements and the black step-line tracking the best performance
The Breakthrough Optimizations
The 10 accepted improvements, in chronological order, reveal an interesting pattern of architectural discovery:
- Backward-Branch Taken Predictor (0.4h): Simple branch prediction that improved performance to 2.32 CoreMark/MHz
- IF Direct-Jump Predictor (0.7h): Enhanced instruction fetching to reach 2.35 CoreMark/MHz
- Cold Multi-Cycle DIV/REM Unit (2.1h): Moving division operations off the critical path, achieving 2.35 CoreMark/MHz
- One-Deep Store Retirement Slot (2.7h): Improving memory operations to reach 2.37 CoreMark/MHz
- Segmented RVFI Order Counter (3.5h): Enhanced ordering logic that boosted performance to 2.89 CoreMark/MHz
- Registered Lookahead I-Fetch Replay Predictor (3.8h): Advanced instruction fetching reaching 2.89 CoreMark/MHz
- Compressed Resetless I-Fetch Replay Tags (4.0h): Further instruction fetching improvements
- RTL-Only Hot/Cold ALU Opcode Split (5.3h): Specializing ALU operations for different cases
- Banked Registered I-Fetch Replay Predictor (6.1h): Final fetching optimization reaching 2.91 CoreMark/MHz
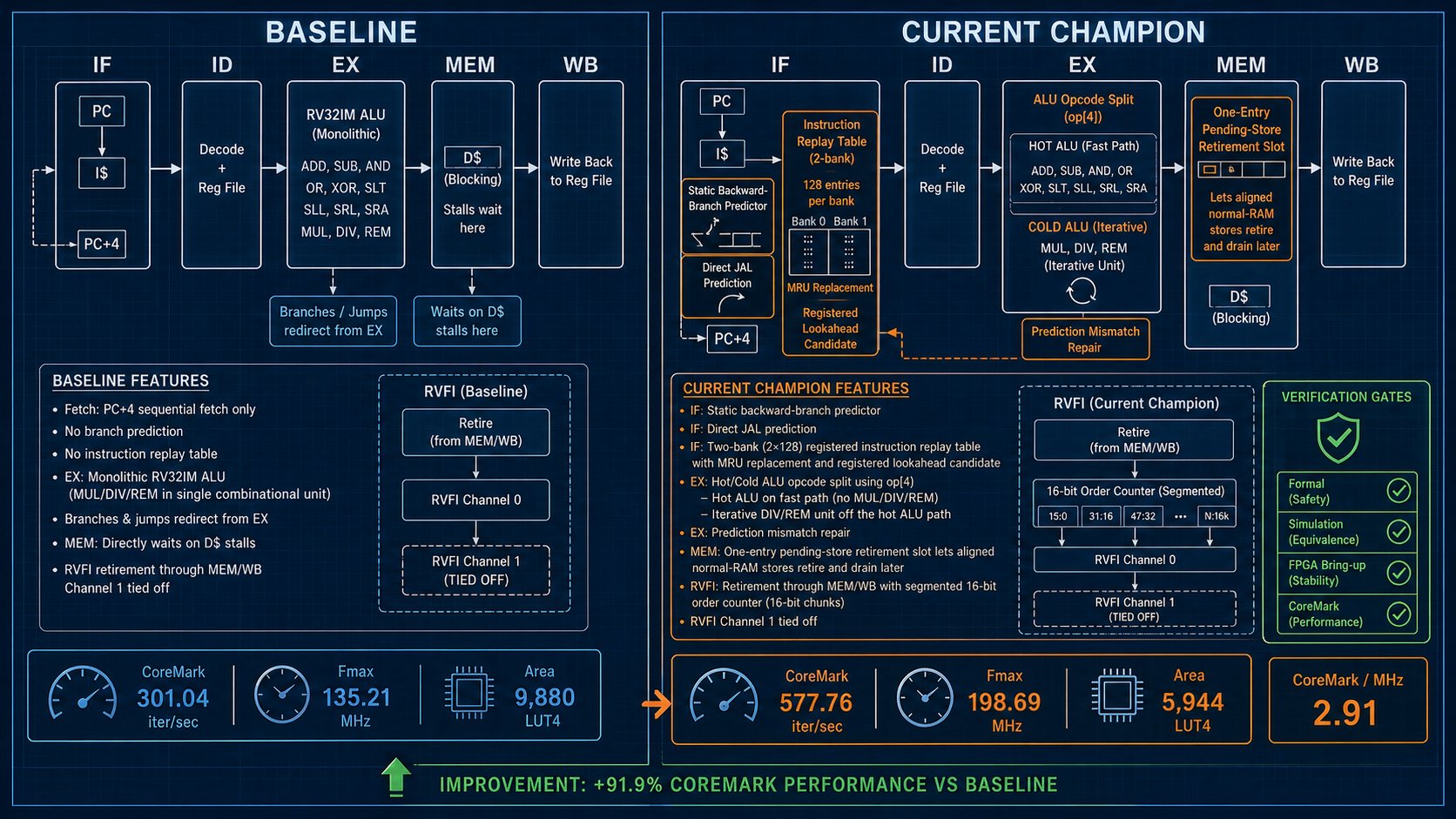 Side-by-side comparison of the baseline 5-stage pipeline versus the final optimized design with all accepted improvements
Side-by-side comparison of the baseline 5-stage pipeline versus the final optimized design with all accepted improvements
The most interesting discovery was the cold multi-cycle DIV/REM unit. The agent didn't initially know that moving division operations off the single-cycle path would also halve the LUT count. This emerged from the implementation and synthesis process—a serendipitous benefit that the autonomous system discovered through experimentation.
The Real Challenge: Verification
"The interesting part is not the loop," the project's creator emphasizes. "There is a lot of noise right now about agent loops. The loop is mostly a solved problem."
Of the 73 hypotheses generated, 63 failed in some way:
- 50 regressed performance
- 9 broke formal verification or co-simulation
- 4 failed placement on the FPGA
The verification system caught these failures through several mechanisms:
- Comprehensive Formal Checks: Beyond just instruction correctness, the system includes ill-formed, unique, liveness, and cover properties that catch subtle bugs
- Path Sandbox: The agent can only edit rtl/** and test/test_*.py files. Attempts to modify verification tools or the canonical CRC table are rejected before evaluation
- Multi-Seed P&R: Using three seeds instead of one provides statistically reliable timing results
- CRC Validation: CoreMark incorrectly reports "Correct operation validated" even when wrong. The system re-validates against canonical values
- Precise Measurement: MMIO markers bracket the timed region to exclude warm-up and printf overhead
Each failure cost 5-15 minutes of compute, but without this verification, the system would have either corrupted the run or taught the AI that wrong approaches were correct.
Implications for AI-Driven Development
"The next wave of companies is not going to be people writing code," predicts the project's creator. "It's going to be people writing verifiers, with a loop running against them."
The autonomous research loop is becoming commoditized—model + prompt + tools + scoreboard + parallel slots. Everyone is converging on the same shape, and providers of these components are racing to zero margins.
The verifier, however, is not commoditized. It encodes what your business actually means by "correct."
- In a CPU, it's an ISA and formal property suite
- In a billing pipeline, it's ledger invariants
- In a compiler, it's differential testing against a reference
- In clinical software, it's FDA-approved properties
"If you can write the rules down, an agent will satisfy them faster than your team will," explains the creator. "If you can't—the rules live in three engineers' heads and a Confluence page nobody updated—the agent will satisfy a different set of rules, the ones it inferred from what it could observe. You will not notice until production."
Future Directions
The project is evolving from a sequential approach to a population-based search, where top-K designs are retained each round and mutations can come from any of them. This should expand the search space without linearly increasing model costs.
The team is also testing how well the optimizations generalize beyond CoreMark by swapping in Embench as the benchmark. This will reveal which improvements were fundamental architectural advances versus CoreMark-specific optimizations.
 Featured image for the auto-arch-tournament project
Featured image for the auto-arch-tournament project
The Frontier Remains Verification
As AI systems become increasingly capable of generating code and designs, the critical differentiator becomes verification. The companies that will succeed in this new era aren't those with the smartest planners or most sophisticated models. They're the ones who can precisely define what "correct" means for their domain and build robust verification systems to enforce those definitions.
"The more interesting question—for me, and for anyone shipping a product—is which parts of your business already have a verifier sharp enough to point a loop at," concludes the project's creator. "Find that, and your team's productivity stops scaling with headcount. The future is bright. The frontier is the verifier."
For more details on the auto-arch-tournament project, visit the GitHub repository or explore the documentation.
Comments
Please log in or register to join the discussion