
AMD returns to the PCIe server AI accelerator market with the Instinct MI350P, a CDNA 4-based card that delivers half the performance of the flagship MI350X in a standard air-cooled form factor, filling a years-long gap left by vendors focusing on rack-scale OAM systems.
AMD has launched the Instinct MI350P, the company's first PCIe form factor accelerator based on the current-generation CDNA 4 architecture, and the first Instinct PCIe card released since the MI210 in 2022. This new accelerator targets data center operators and enterprises that need on-premise AI inference capabilities but cannot support the high thermal and power density of modern OAM-based rack-scale systems, or want to integrate accelerators with existing PCIe server hardware.

For the past several years, AMD and NVIDIA have focused almost entirely on rack-scale and modular OAM/SXM accelerators, which offer the highest compute density and proprietary interconnect performance for large-scale AI training and inference. This left a gap in the market for PCIe-based server-grade accelerators, as workstation-class GPUs like AMD's Radeon AI Pro series lack the HBM memory capacity, bandwidth, and full AI feature sets of flagship server accelerators.
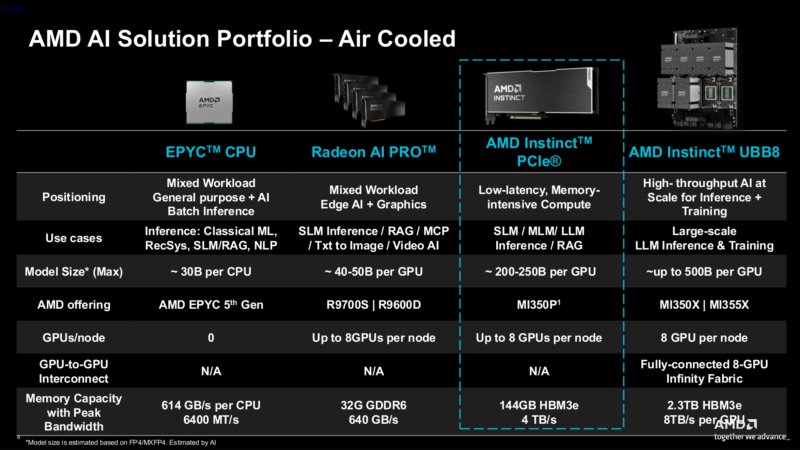
Workstation GPUs can handle some entry-level inference tasks, but they fall short for production workloads that require more than 48GB of memory (typical for high-end workstation cards) or the matrix compute performance of CDNA 4. NVIDIA has not announced any current-generation PCIe server accelerators, leaving AMD as the only vendor addressing this niche with the MI350P.
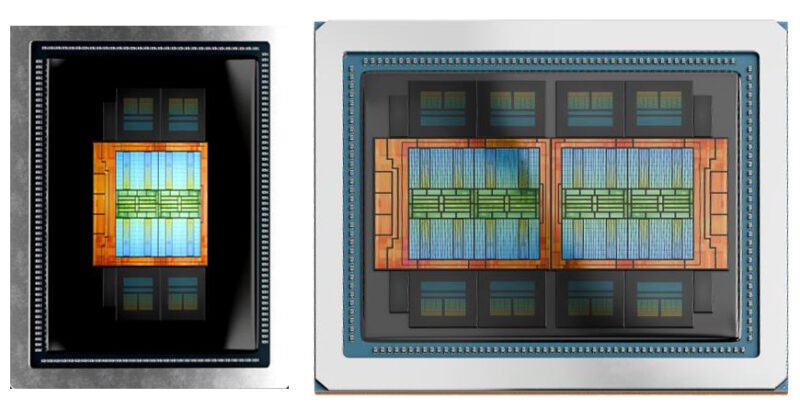
The MI350P is not a salvaged or binned MI350X chip. Instead, AMD used the chiplet design of the CDNA 4 architecture to create a purpose-built smaller accelerator. The flagship MI350X uses two I/O dies (IODs) paired with eight accelerator complex dies (XCDs) for a total of 256 compute units. The MI350P uses a single IOD with four XCDs, exactly half the compute die configuration of the MI350X.
Below are the key specifications for the MI350P compared to the flagship MI350X:
| GPU | MI350P | MI350X |
|---|---|---|
| Compute Units | 128 | 256 |
| Matrix Cores | 512 | 1024 |
| Peak Engine Clock | 2200MHz | 2200MHz |
| Memory | 144GB HBM3E | 288GB HBM3E |
| Memory Bandwidth | 4TB/sec (8Gbps x 4096-bits) | 8TB/sec (8Gbps x 8192-bits) |
| Matrix Perf (MXFP8) | 2.3 PFLOPS | 4.6 PFLOPS |
| I/O | PCIe Gen5 x16 | PCIe Gen5 x16, 7x Infinity Fabric (x16) |
| TBP | 600W (Optional: 450W) | 1000W |
| Form Factor | PCIe CEM, 10.5-inch FHFL DS | OAM |
| Architecture | CDNA 4 | CDNA 4 |
Halving the IOD and XCD count also halves the HBM3E stacks from 8 to 4, resulting in 144GB of memory and 4TB/s bandwidth, exactly half the MI350X's 288GB and 8TB/s. Peak matrix performance (MXFP8) is 2.3 PFLOPS, half the MI350X's 4.6 PFLOPS, as expected from the halved compute resources.
The MI350P is a full height, full length (FHFL) dual-slot card, designed for passive air cooling via server chassis airflow. Typical board power (TBP) is 600W, which matches the maximum power limit defined by the PCIe CEM 5.0 specification. For servers that cannot supply 600W per PCIe slot, AMD offers an optional 450W TBP mode that reduces performance slightly to lower power draw.

Up to 8 MI350P cards can be installed in a single server tray, as the air-cooled form factor does not require the specialized liquid cooling setups of OAM accelerators.

Unlike the MI350X, the MI350P does not expose Infinity Fabric links for GPU-to-GPU communication. Multi-card setups are limited to PCIe Gen5 x16 bandwidth for inter-GPU data transfer, which is significantly slower than Infinity Fabric. This makes 8-card MI350P configurations better suited for running 8 separate inference models (one per card) than training or running a single large model that spans all 8 GPUs, as the PCIe bus would become a bottleneck for model weight sharing.
The MI350P retains the MI350X's partitioning feature, allowing the card to be split into up to 4 logical accelerators, each with 1 XCD and 36GB of HBM3E memory. This is half the partitioning capacity of the MI350X (which supports 8 partitions) due to the halved XCD count.
AMD has published both peak (theoretical) and delivered (real-world) performance figures for the MI350P, a practice they did not follow for the MI350X launch. Delivered performance is lower than peak across all metrics, as the 600W power budget cannot drive all compute resources to their maximum theoretical throughput. MXFP6 performance in particular is significantly lower than peak, as this data type is more sensitive to power and memory bandwidth constraints.
The MI350P is a strong fit for three specific use cases. First, enterprises with existing PCIe server infrastructure that want to add AI inference capabilities without replacing entire racks. Second, data centers with older cooling systems that cannot handle 11kW+ OAM compute nodes. Third, on-premise inference workloads that use smaller models (under 144GB) or run multiple independent models in parallel.
For system builders, pair the MI350P with PCIe Gen5-capable CPUs like the AMD EPYC 9004 series or Intel Xeon Scalable 5th Gen, as PCIe Gen4 would bottleneck the card's 16 lanes of Gen5 bandwidth. Server chassis must provide at least 300 LFM (linear feet per minute) of airflow per card to cool 600W TBP units, and power supplies must be rated for at least 500W per card plus system overhead. Avoid the MI350P if you need to train large language models (LLMs) over 144GB in size, or run multi-GPU inference for models that exceed single-card memory capacity, due to the lack of Infinity Fabric.
The MI350P fills a critical gap in the current AI accelerator market, offering server-grade CDNA 4 performance in a standard PCIe form factor that no other vendor currently provides. While it trades multi-GPU interconnect performance for broad compatibility, it delivers exactly what many data center operators have been asking for, a way to deploy current-generation AI hardware without adopting rack-scale OAM systems. AMD's early move into this niche gives them a significant lead over NVIDIA, which has not indicated any plans to release a PCIe-based current-gen accelerator.
Comments
Please log in or register to join the discussion