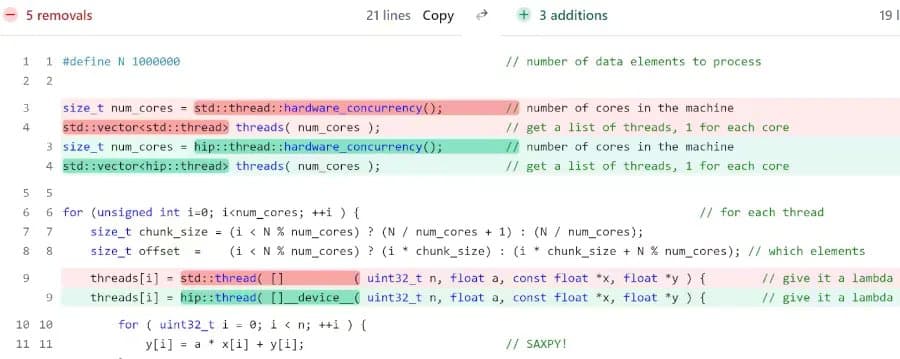
AMD has announced hipThreads, a new C++ concurrency library designed to simplify porting existing std::thread code to AMD GPUs by providing familiar thread, mutex, and synchronization primitives.
AMD has unveiled hipThreads, a new C++ concurrency library aimed at making GPU programming more accessible to developers already familiar with C++ threading patterns. The tool, part of AMD's ROCm/HIP ecosystem, allows developers to port their existing std::thread-based code to AMD GPUs with minimal friction.

What hipThreads Offers
The hipThreads library introduces GPU execution models that mirror the C++ Concurrency Support Library. Developers can use hip::thread, hip::mutex, hip::lock_guard, and hip::condition_variable in place of their std::thread counterparts, creating code that feels structurally similar to existing CPU programs.
According to AMD, this approach eliminates the need for developers to immediately grapple with kernel configuration, grid/block semantics, and ad-hoc synchronization that typically characterize GPU programming. Instead, hipThreads allows for incremental porting where teams can replace std::thread with hip::thread and adapt synchronization where needed without restructuring entire codebases into bulk kernels.
Target Audience and Use Cases
AMD positions hipThreads as particularly valuable for:
- C++ teams experiencing CPU bottlenecks looking to leverage GPU acceleration
- Developers lacking GPU expertise who want to avoid learning complex ROCm/CUDA parallel programming models
- Tool vendors seeking simple GPU integration options
Technical Requirements and Availability
The library is open-source under the Apache 2.0 license and available on GitHub. However, hipThreads has some limitations:
- Requires ROCm 7.0 or newer
- Currently supports Linux only
- Designed for incremental adoption rather than complete code rewrites
Industry Context
This announcement represents AMD's continued investment in making GPU programming more accessible. By providing tools that bridge the gap between traditional C++ development and GPU acceleration, AMD is positioning itself as a more approachable option for developers who might otherwise default to NVIDIA's CUDA ecosystem.
The incremental porting approach could be particularly appealing to enterprises with large existing codebases that cannot afford complete rewrites. Teams can identify performance-critical sections and gradually move them to GPU execution while maintaining the rest of their application on CPU.
Future Implications
While it remains to be seen how widely hipThreads will be adopted, the library addresses a real pain point in GPU programming: the steep learning curve for developers accustomed to traditional C++ concurrency models. If successful, hipThreads could help AMD expand its developer ecosystem and provide a more accessible on-ramp to GPU computing for the broader C++ community.
More information about hipThreads is available on the AMD ROCm blog and GPUOpen.
Comments
Please log in or register to join the discussion