Researchers from Tilde introduce Aurora, a novel optimizer that addresses fundamental limitations in the Muon optimizer for tall matrices. By jointly optimizing for orthogonality and row-norm uniformity, Aurora prevents neuron death in MLP layers and achieves state-of-the-art performance on multiple benchmarks.
Aurora: A Leverage-Aware Optimizer for Rectangular Matrices
The field of neural network optimization has seen significant innovation in recent years, with the Muon optimizer emerging as a powerful alternative to traditional methods like Adam. However, as researchers from Tilde have discovered, Muon has a critical limitation when applied to tall matrices—those with more rows than columns—which can cause a significant portion of neurons in MLP layers to permanently die. Their new optimizer, Aurora, addresses this fundamental issue while maintaining the desirable properties of Muon.
The Muon Optimizer and Its Limitations
Muon has gained attention for its success in training large language models, particularly in the nanoGPT speedrun competition where it outperformed AdamW in wall-clock time to convergence despite requiring more computation per step. The core innovation in Muon is its use of the polar factor—an iterative algorithm that computes the closest semi-orthogonal matrix to a given matrix—which ensures that updates preserve the operator norm.
{{IMAGE:1}}
However, the researchers discovered a critical issue: for tall matrices (where m > n), Muon's update inherits row-norm anisotropy. This means that different rows of the parameter matrix receive updates of significantly different magnitudes. In MLP layers, this leads to a self-reinforcing feedback loop where neurons with small initial updates receive persistently small updates throughout training, effectively dying and contributing nothing to the model's capacity.
The Problem with Row Normalization
In response to this limitation, variants like NorMuon have been developed that add a row normalization step to Muon's update. While this helps prevent neuron death, it introduces a new problem: row normalization can significantly reduce the precision of the polar factor computation.
As the researchers demonstrate mathematically, a tall matrix cannot simultaneously be column-orthogonal and have uniform unit row norms. This fundamental tension means that forcing unit row norms necessarily introduces a precision defect into the orthogonalization routine.
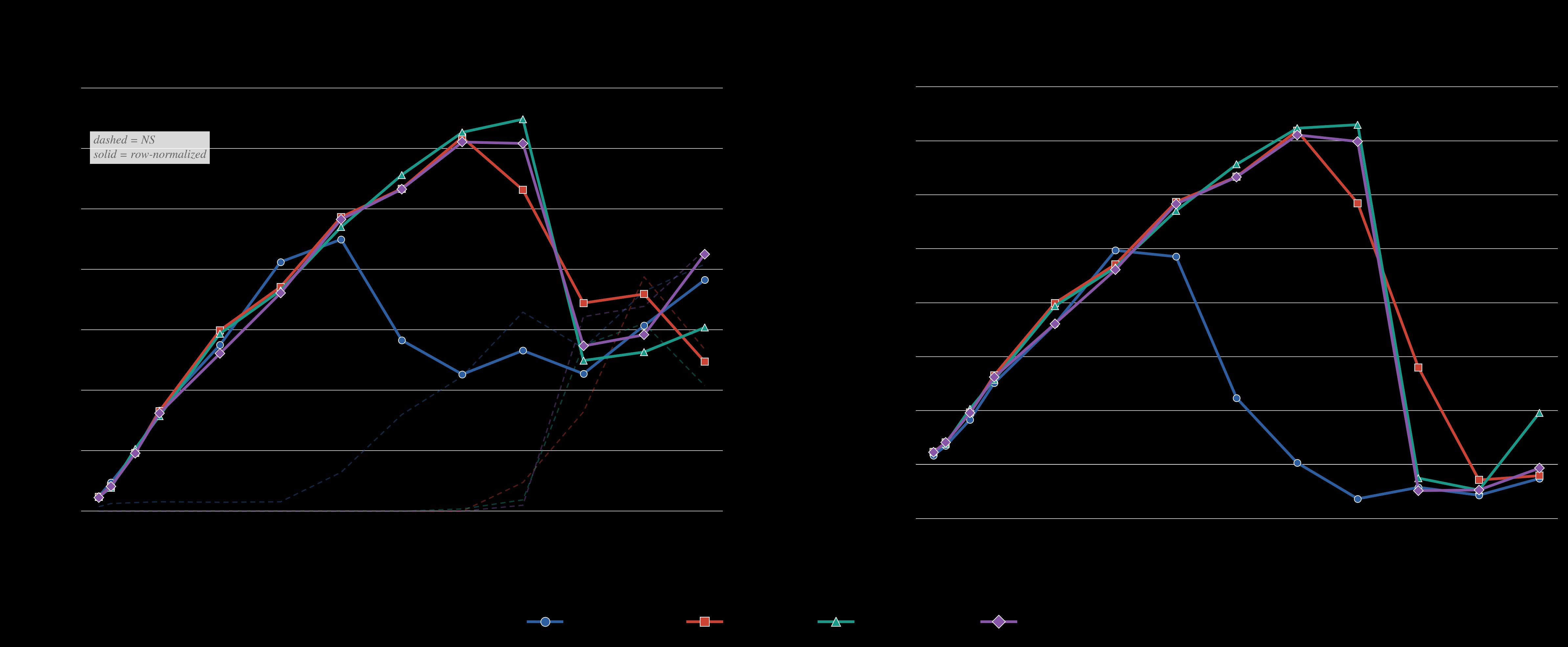
Figure 2 illustrates this effect. When the researchers sampled random 512×128 matrices with varying row norm standard deviations and orthogonalized them using different algorithms, they found that row normalization degrades precision significantly. At a row-norm standard deviation of 3, the orthogonality defect peaks at 0.06, which is much larger than the precision improvement gained by using more sophisticated algorithms like PE-8 versus quintic iteration.
Neuron Death: A Critical Pathology
The researchers define neuron death through three criteria:
- Low effective gradient norm
- Low effective update norm
- Persistence over training
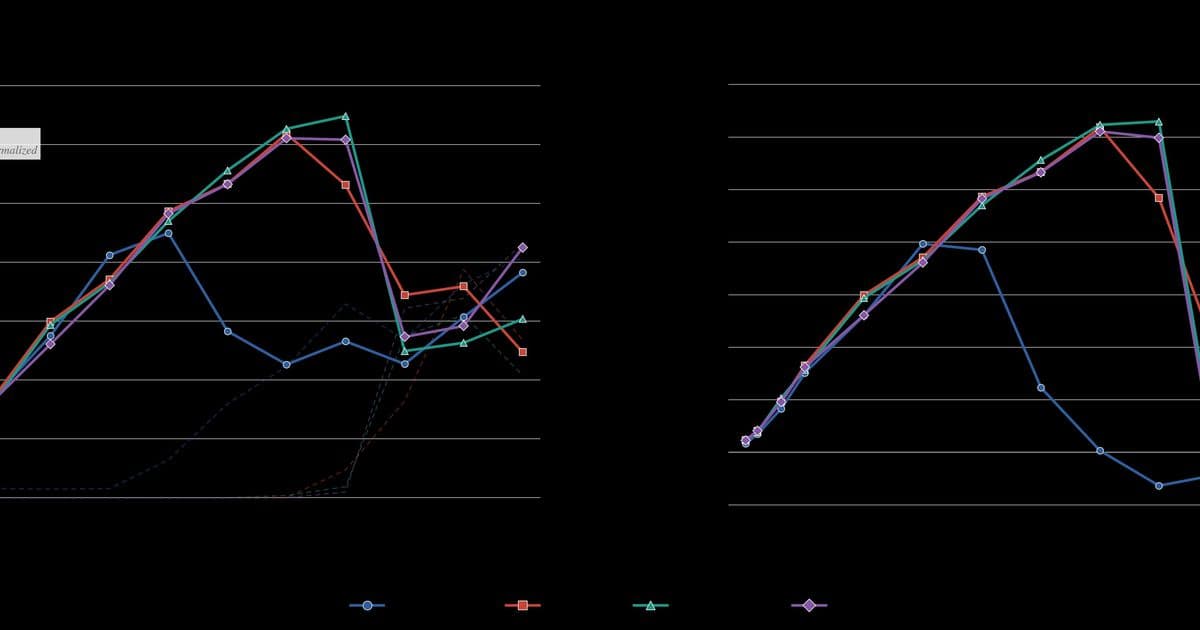
Their empirical analysis reveals that under Muon, a large fraction of neurons in MLP layers can die early in training and never recover. In one visualization, they show that by step 500, more than one in four neurons in a middle layer are effectively dead, producing a bimodal distribution of leverage scores.
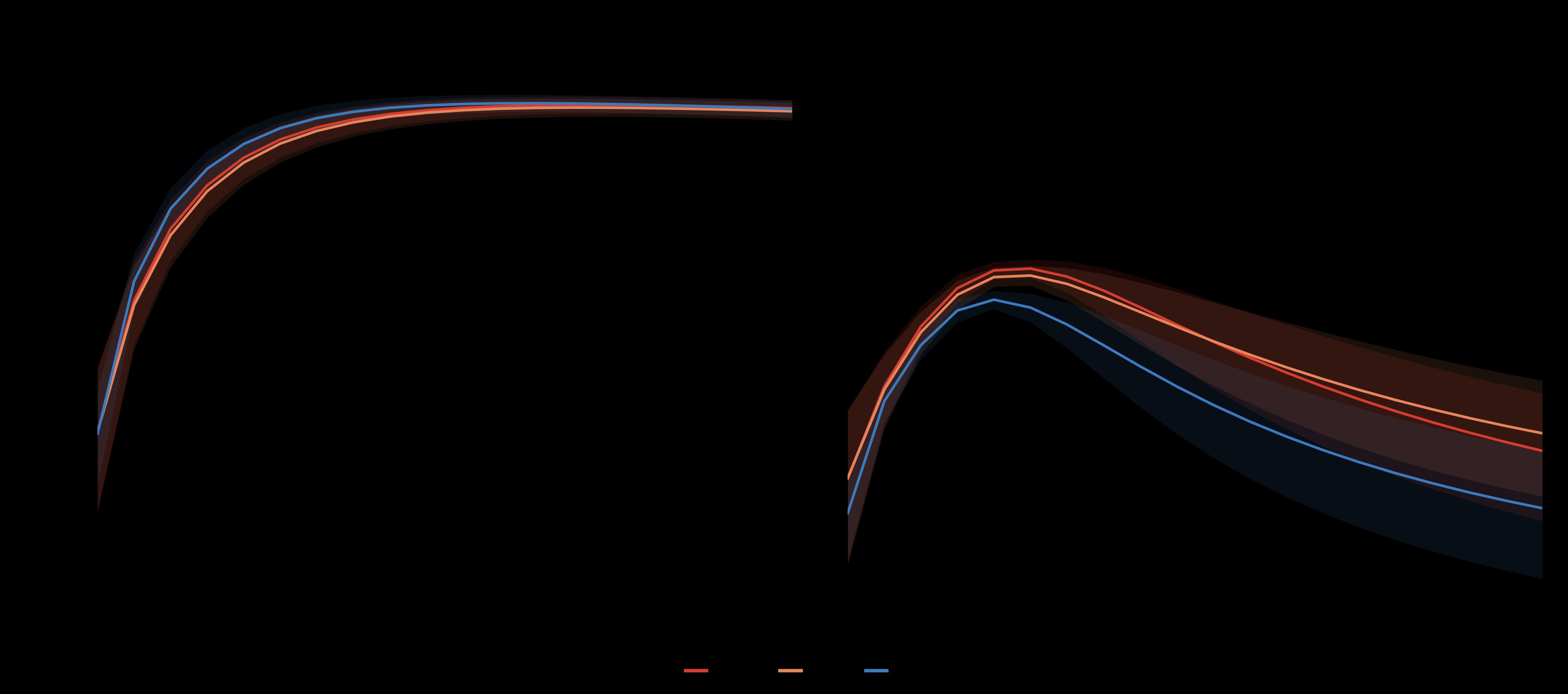
Figure 12 demonstrates an interesting finding: while row normalization directly affects only the up and gate projections in MLP layers, it indirectly benefits the down projection as well. By keeping rows in the up and gate projections alive, normalization ensures isotropic gradient flow into the down projection, stabilizing its column leverage without any direct intervention.
The Aurora Solution
Aurora is formulated as steepest descent under the joint constraint of row-norm uniformity and orthogonality. For tall matrices (m ≥ n), the optimizer enforces that all update row norms be equal to n/m rather than 1. This constraint fixes the squared Frobenius norm to n and forces all singular values to equal 1, making the update left semi-orthogonal.
The researchers present two formulations of Aurora:
- A Riemannian formulation that projects the gradient onto the joint Stiefel/equal-row-leverage manifold
- An iterative approximation that alternates between row normalization and polar factor computation
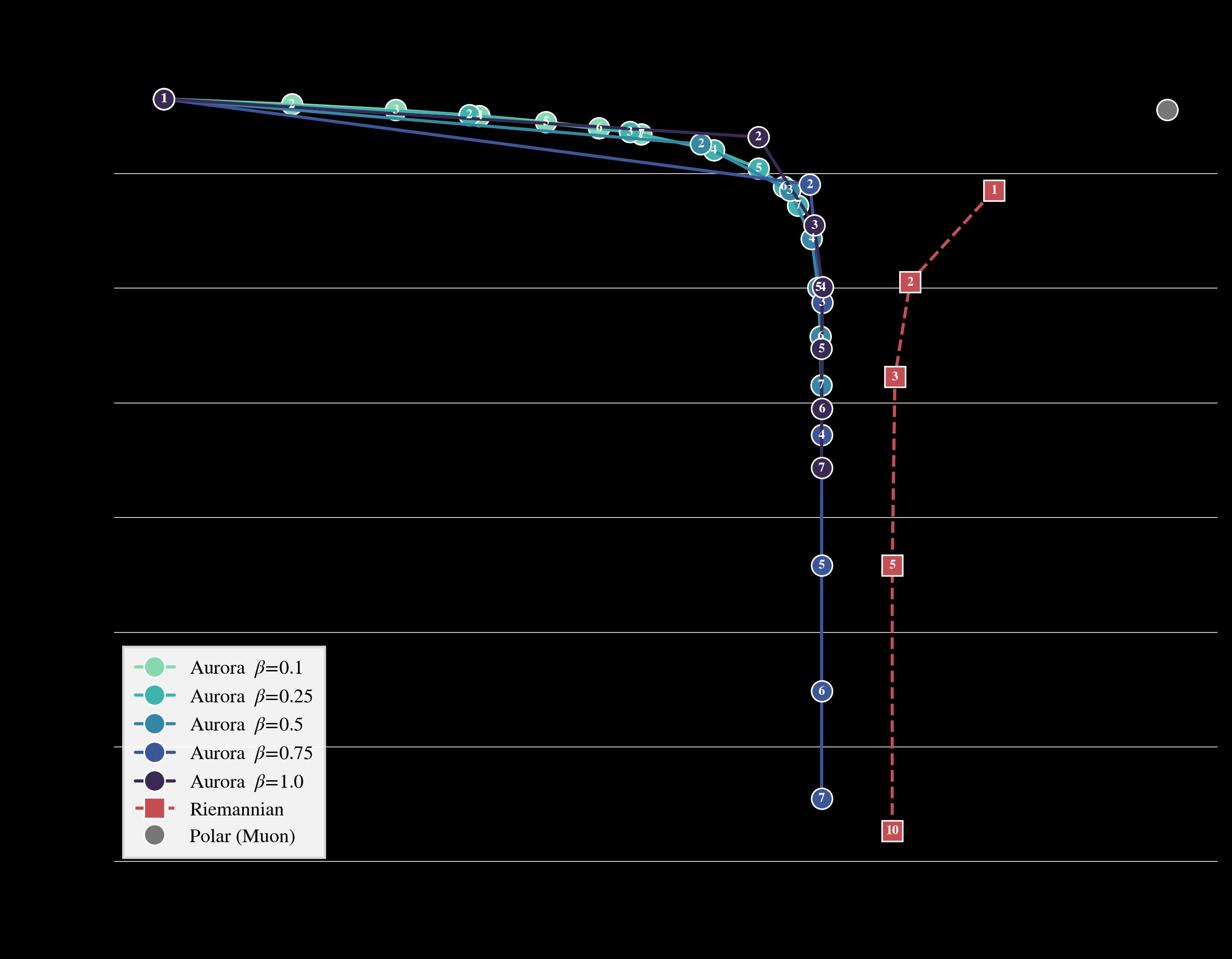
Figure 18 compares the tradeoff between gradient alignment and row-norm coefficient of variation for Aurora, Riemannian-Aurora, and standard Muon. While standard Muon achieves high alignment but poor row-norm uniformity, both Aurora variants converge to low CV with high alignment, though from different directions.
Empirical Results
The researchers evaluated Aurora on multiple benchmarks with impressive results:
nanoGPT Speedrun
Aurora achieved a new state-of-the-art on the modded-nanoGPT optimization track, reaching the target loss of 3.28 in just 3175 steps when combined with Contra-Muon and update/weight flooring techniques. This represents a significant improvement over the previous best of 3225 steps.
1.1B Pretraining
When training a 1.1B-parameter transformer on approximately 100B tokens of open-source internet data, Aurora achieved a final loss of 2.26, outperforming both Muon (2.31) and NorMuon (2.33).
Downstream Evaluations
Aurora's improvements translated to consistent gains across standard benchmarks:
- HellaSwag: 67.6% (2.5 point improvement over Muon and NorMuon)
- ARC-Challenge: 43.5%
- Winogrande: 63.1%
- MMLU: 37.9% (10 point improvement over Muon)
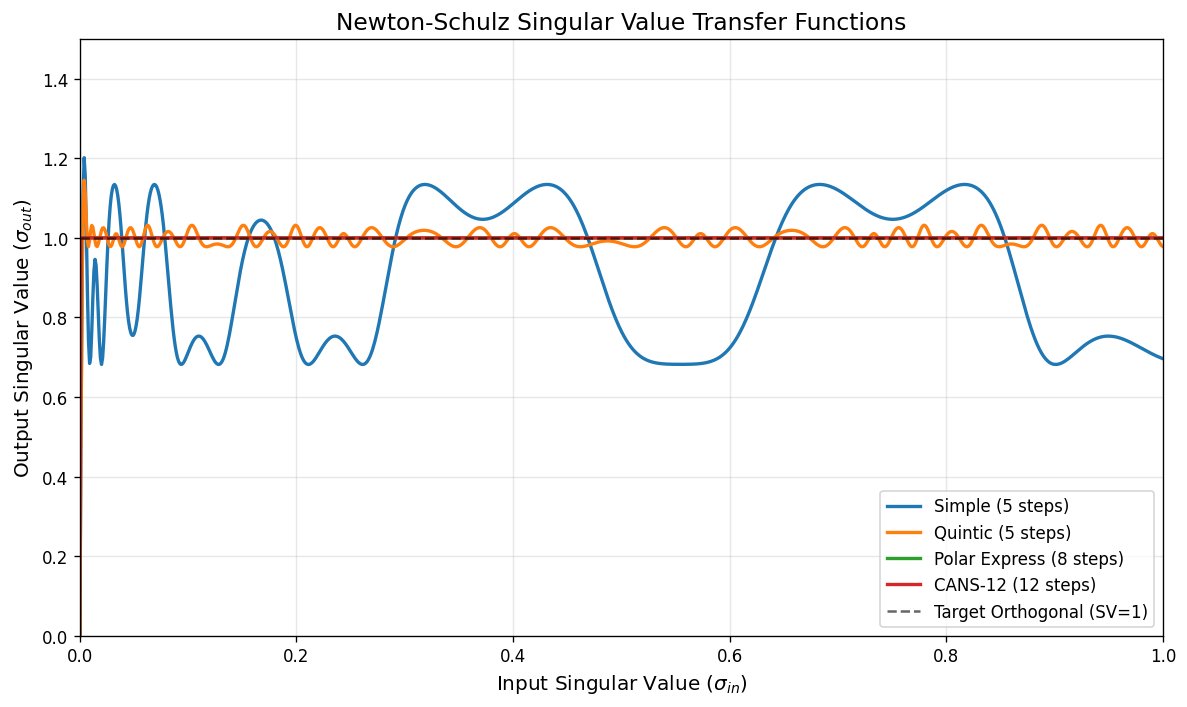
Figure 5 shows the transfer functions for different Newton-Schulz iterations. PE-8 and CANS-12 converge to machine precision, while quintic retains a persistent spectral error of ~0.03. This precision is important for maintaining the orthogonality that makes Muon effective.
Implications and Future Directions
The researchers identify four key aspects of their work that are particularly exciting:
Strong empirical gains: Aurora achieved 100x data efficiency on several key benchmarks, demonstrating that significant improvements are possible through better optimization.
Architecture-Optimizer Codesign: Aurora is specifically designed for up and gate projections, correcting a fundamental pathology in model training dynamics under Muon. The advantage grows monotonically with MLP expansion factor, suggesting that wider MLPs amplify exactly the pathology Aurora corrects.
Compression/Dense Solutions: Aurora's row uniformity constraint encourages more effective utilization of parameters in MLPs, leading to denser solutions.
Bottom-Up Optimizer Design: Unlike the top-down approach that dominates optimizer research, Aurora was derived by mechanistically studying a specific pathology and designing the minimal objective that corrects it.
The researchers open-sourced their implementation at github.com/tilde-research/aurora-release, making both the practical damped-iteration Aurora optimizer and the Riemannian-Aurora reference solver available to the community. They also released the Aurora 1.1B pretrained model at tilde-research/aurora-1.1B.
Conclusion
Aurora represents a significant advancement in neural network optimization, addressing a fundamental limitation of the Muon optimizer while maintaining its desirable properties. By jointly optimizing for orthogonality and row-norm uniformity, Aurora prevents neuron death in MLP layers and achieves state-of-the-art performance across multiple benchmarks.
The researchers' bottom-up approach—identifying a specific pathology and designing a targeted fix—offers a compelling alternative to the top-down methods that dominate optimizer research. As the field continues to scale to larger models and more complex architectures, optimizers like Aurora that address fundamental limitations in training dynamics will become increasingly important.
The work also highlights the value of architecture-optimizer co-design, showing that understanding how optimizers interact with specific architectural components can lead to significant improvements in model performance and efficiency.
Comments
Please log in or register to join the discussion