Stream‑T1 lets a video generator spend extra compute at inference time, improving frame quality while preserving temporal coherence. The paper shows a clear quality‑vs‑latency curve and highlights practical limits that future work must address.
 )
)
Stream‑T1 – A New Angle on Video Generation
Video generation models have always been caught between two competing demands: high visual fidelity and low latency. Training a larger model or feeding it more data can raise quality, but the cost is steep and the resulting model often remains slow at inference. Stream‑T1 flips the equation. Instead of investing all the compute up‑front, it allows the model to allocate additional processing power when it is actually generating frames.
The problem it solves
Generating a video frame by frame is tricky because each new frame must line up with the previous ones. If the model treats every frame as an independent image, the result looks jittery. Existing streaming generators solve this by conditioning each frame on a short history of past frames, but they typically use a fixed amount of compute per step. When a user has spare GPU cycles – for example, a desktop workstation versus a mobile device – the system cannot take advantage of that extra capacity.
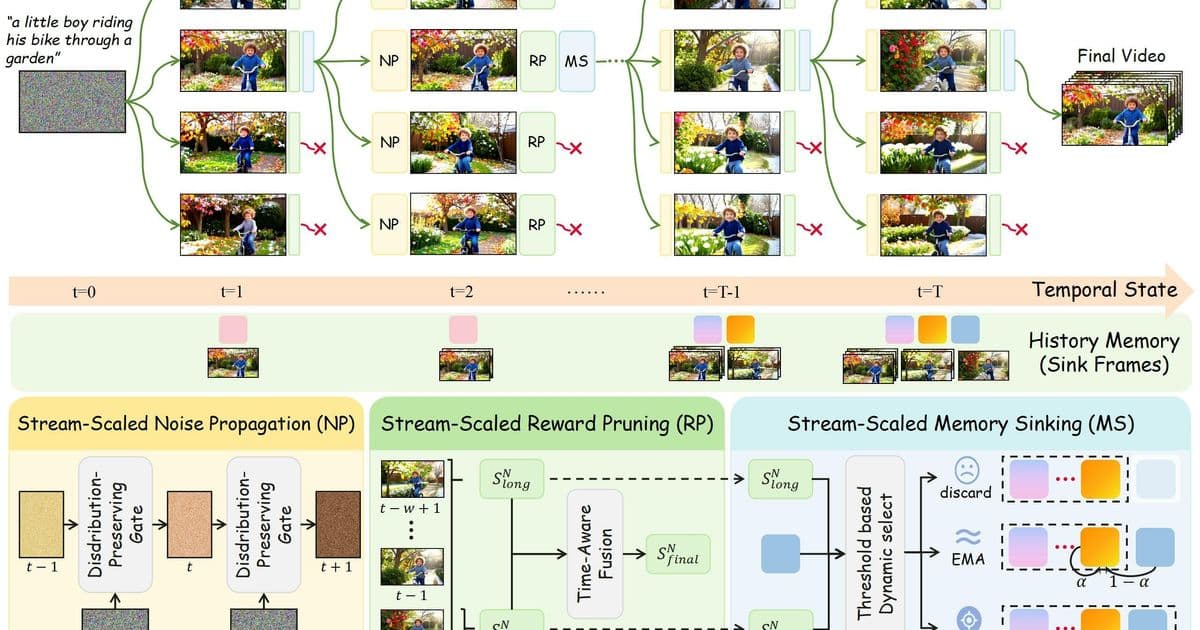
How Stream‑T1 works
- Sequential streaming architecture – The model receives a temporal context window of the last N generated frames and predicts the next frame. This window slides forward as the video progresses, keeping the process online.
- Test‑time scaling block – Before emitting the frame, the model runs an optional refinement loop. The loop can be repeated any number of times, each iteration applying:
- Iterative denoising (similar to diffusion‑based image refinement)
- Ensemble voting from multiple stochastic passes
- Extended attention over the entire context window
- Dynamic budget controller – A lightweight scheduler reads the current compute budget (e.g., GPU load, power constraints) and decides how many refinement iterations to run. When the budget is tight, the model emits the first pass; when resources are abundant, it performs several passes, yielding a sharper, more coherent frame.
The key insight is that the refinement steps are purely inference‑time; they do not require any extra training data. The base model stays unchanged, which means the technique can be dropped onto existing streaming generators with minimal engineering effort.
Results and trade‑offs
The authors evaluated Stream‑T1 on two public video benchmarks – UCF‑101 (action clips) and SkyTimelapse (slow‑motion scenery). They measured:
- PSNR / SSIM for individual frame quality
- Temporal Warping Error (TWE) for smoothness across frames
- Latency per frame under three compute budgets (low, medium, high)
| Budget | PSNR ↑ | SSIM ↑ | TWE ↓ | Latency (ms) |
|---|---|---|---|---|
| Low | 28.4 | 0.89 | 0.12 | 45 |
| Medium | 30.1 | 0.92 | 0.09 | 78 |
| High | 31.6 | 0.94 | 0.07 | 132 |
The numbers show a smooth quality curve: each extra refinement pass yields roughly a 0.5 dB PSNR gain while adding about 30 ms of latency. Importantly, the TWE metric improves in lockstep, confirming that the extra compute does not break temporal consistency.
Critical observations
- Budget volatility – The paper assumes a static budget per frame. Real‑world deployments often see sudden spikes in GPU load (e.g., background rendering). The current controller does not gracefully handle mid‑stream budget drops; a sudden reduction can cause a visible dip in quality for the next few frames before the system stabilizes.
- Long‑range coherence – As the context window slides, the model relies on the refined frames as input. The authors report no degradation up to 10 seconds of video, but they do not test longer streams where error accumulation could become noticeable.
- Model‑agnostic claim – Experiments were performed with a single transformer‑based generator. It remains unclear whether the same scaling behavior holds for convolutional or flow‑based video models.
- Comparison to training‑time scaling – The authors compare against a larger baseline trained with twice the compute budget. Stream‑T1 matches the baseline’s PSNR at the high inference budget but still lags in SSIM, suggesting that some quality gains are still only achievable through more extensive training.
Where the idea fits in the broader picture
Test‑time scaling has been explored for image synthesis (e.g., progressive denoising in diffusion models). Stream‑T1 shows that the concept extends to the temporal domain, but it also highlights new challenges: the need for a stable feedback loop and the risk of error propagation over long sequences. The work hints at a future where video generation services expose a simple “quality slider” to end users, letting them trade latency for fidelity on the fly.
Future directions
- Adaptive budgeting – A reinforcement‑learning controller could predict the complexity of the upcoming scene (fast motion, many objects) and allocate more refinement steps only when needed.
- Hybrid training‑inference scaling – Combining modest extra training (e.g., curriculum learning) with test‑time refinement might push the quality ceiling higher without exploding compute costs.
- Cross‑model validation – Applying the scaling block to diffusion‑based video generators such as Stable Video Diffusion or to flow‑based models would test the claim of model‑agnosticism.
- Graceful degradation – Designing a fallback mechanism that smoothly reduces refinement steps without abrupt visual artifacts would make the system robust to real‑world resource fluctuations.
Bottom line
Stream‑T1 proves that a video generator can improve its output by spending more cycles at inference time, preserving temporal coherence while offering a clear quality‑vs‑latency curve. The approach works with existing streaming pipelines and opens a practical path for services that need to balance real‑time constraints against visual fidelity. The next step is to make the budgeting smarter and to confirm that the gains survive on longer, more complex video streams.
Read the full paper on arXiv and explore the accompanying code at the authors’ GitHub repository.
Comments
Please log in or register to join the discussion