
As LLM agents become the primary interface, traditional observability metrics fall short. This deep dive explores the specialized blend of operational metrics and agent analytics that MCP server developers must adopt to ensure reliability, user satisfaction, and business value in the conversational AI era.
The shift from Graphical User Interfaces (GUIs) to conversational interfaces powered by Large Language Model (LLM) agents has introduced new complexities in product development and system maintenance. The Model Context Protocol (MCP), in simple terms, is a standardized communication layer that enables an LLM (the client) to discover and invoke external functions or services (the server-side tools). However, the nature of LLM reasoning and the non-deterministic structure of agent interactions render traditional web analytics insufficient. While latency and error rates remain important, they fail to capture the user's intent, satisfaction, and journey through a complex, multi-tool interaction.

To succeed, modern MCP server developers must adopt a specialized blend of observability and user analytics, focusing on a set of core operational and business metrics that go beyond traditional infrastructure monitoring.
Operationalizing the MCP Server
Effective MCP server management begins with rigorous attention to low-level operational statistics. These metrics are critical for guaranteeing the reliability and speed of the tool-calling mechanism.
The Latency Deep Dive
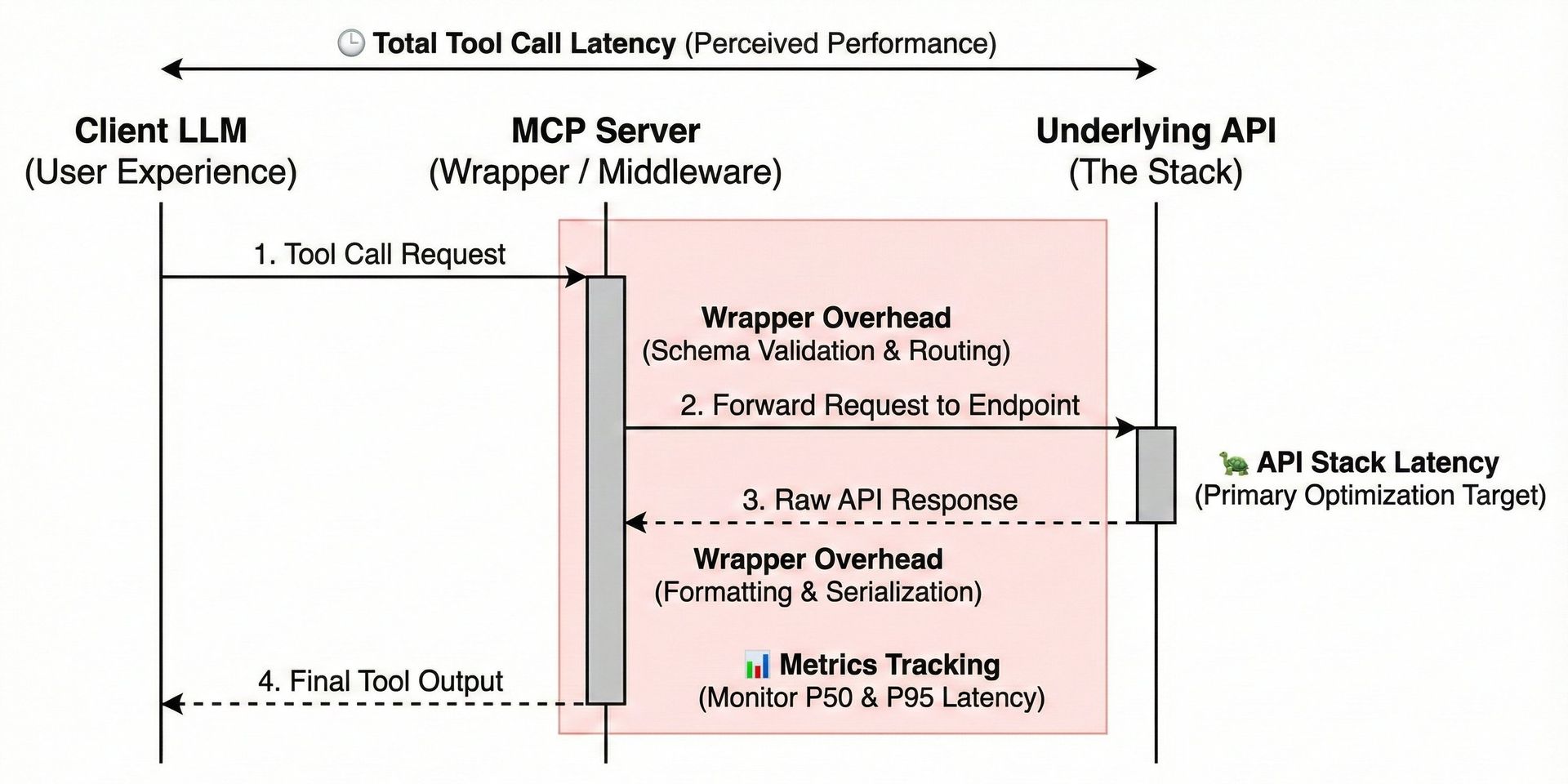
Tool call latency is one of the most significant factors affecting a client LLM's performance, as slower responses can degrade the overall agent experience and increase token consumption. Standard performance metrics, such as P50 (50th percentile) and P95 latency, must be tracked for every tool exposed by the MCP server.
Crucially, developers must differentiate between latency originating in the MCP wrapper and latency originating in the underlying Application Programming Interface (API) stack. An MCP server acts as a middleware, wrapping existing API endpoints with function call schemas. If an API call is slow, the LLM client (and thus the end-user) perceives the entire tool call as slow, regardless of the wrapper's efficiency. Identifying and optimizing the API stack remains the most direct way to reduce tool call latency.
Client LLM Adaptation and Docstring Tuning
A unique challenge in the MCP ecosystem is the variability among client LLMs. Different LLMs may parse and reason over the provided tool definitions (docstrings and schemas) with varying degrees of success.
By tracking the origin of incoming tool calls—whether from a specific commercial LLM or a custom model—server operators can observe which client is experiencing the highest success rates and lowest latencies. This data-driven insight allows for an iterative optimization process known as Docstring Tuning. Developers can modify their function descriptions or parameter schemas in a targeted way, ensuring the documentation is maximally clear and precise for the client LLMs that use the service most frequently.
Reproducing Non-Deterministic Errors
LLM-driven interactions are inherently non-deterministic, making error reproduction one of the most frustrating aspects of MCP server development. A typical error might involve a client LLM generating an improperly formatted argument or invoking a tool with an illogical sequence, leading to an exception.
To address this, successful MCP servers must implement a Session Object or detailed transaction log that captures the exact input and output of every tool call within a user's session. This allows developers to instantly see the full context leading up to a failure, effectively transforming a non-deterministic error into a reproducible, traceable issue.
Unlocking Business Value through Agent Analytics
While technical metrics ensure the lights are on, the success of an MCP server as a product hinges on understanding and satisfying the end-user. This requires a transition from server-side observability to business-centric Agent Analytics.
The Identity Problem and Custom User Tracking
In a non-GUI, tool-focused environment, traditional web traffic data often fails to provide meaningful user identification. Server operators frequently lack the ability to answer the most critical business question: Who is using our tools? Differentiating between an indie hacker exploring the technology and an enterprise customer operating under a strict Service Level Objective (SLO) is essential for prioritizing support and feature development.
To solve this, a dedicated user identification mechanism is integrated into the MCP server lifecycle. This often takes the form of an identify hook within the SDK, which is called early in the request pipeline.
// MCP Server SDK Integration (e.g., in a fast-mcp environment)
import { MCPAnalytics } from '@mcp-analytics/sdk';
const analyticsClient = new MCPAnalytics(process.env.MCP_ANALYTICS_KEY);
// Define the identify function within the tool-calling handler
export function handleToolCall(request: IncomingRequest) {
// 1. Extract known business identifiers from the request, e.g., via Auth headers
const userId = request.headers['x-user-id'];
const accountTier = getAccountTier(userId);
// 2. Use the identify hook to tag the MCP session with custom business logic
analyticsClient.identify(request, {
user_id: userId,
segment: accountTier,
organization: 'Acme Corp',
api_key_hash: hash(request.headers['authorization'])
});
// 3. Proceed with tool invocation and subsequent call logging...
// ...
}
By utilizing the identify hook, developers can pass custom key-value pairs directly from their business logic to the analytics platform, allowing operators to track a specific entity across their entire agent journey.
Full User Journey Mapping
For complex agents that chain multiple tool calls, understanding the sequence of actions is paramount. Full user journey mapping allows Product Managers (PMs) and developers to see exactly how an agent interacts with a service. This mapping traces the path of tool calls (e.g., read_file → search_files → write_file → delete_temp_file), revealing the agent's intent (e.g., "linting and fixing front-end code") and helping define common, valuable usage patterns that can be optimized or productized.
Sentiment Analysis: The Solution to the Broken Feedback Loop
Perhaps the most "hidden" and valuable metric is the sentiment and intent derived directly from the agent-user conversation. User feedback rates for agent interactions are notoriously low (sometimes less than 5%), leading to a broken feedback loop where developers cannot efficiently gauge user satisfaction or pain points.
Sentiment analysis bypasses this issue by automatically classifying the conversation that led to the tool use. By clustering conversations into categories like 'Frustrated,' 'Successful,' or 'Confused,' developers can immediately zoom in on the specific tool calls and sessions that caused user friction, identifying pain points without requiring explicit user input. This directly informs the product roadmap and dramatically simplifies the process of making the server more data-driven.
Behind the Scenes: MCP Logic and Privacy
The implementation of sophisticated agent analytics in an MCP server involves careful architectural trade-offs, particularly regarding data processing and user privacy.
Comparison to Traditional Observability
Traditional observability tools (like logs and traces) excel at reporting what happened in the infrastructure (e.g., latency, error status codes). Agent Analytics, in contrast, focus on the user's experience and intent—why it happened from a conversational perspective.
While existing frameworks like LangChain or ReAct focus on the agent's operational logic and control flow, MCP-focused analytics provide the crucial business-layer insights necessary for enterprise-grade deployment.
Architectural Decision: Classifier over Full LLM
Implementing real-time sentiment analysis for millions of MCP server calls requires efficiency. While an LLM would be ideal for dynamic topic generation and nuanced analysis, running every conversation fragment through a large LLM for classification introduces significant latency, token costs, and compliance overhead.
The initial architectural choice for scalable systems is often a simpler, more cost-effective classifier. This classifier is trained to aggregate and query conversations into a set of hardcoded, actionable clusters (e.g., 'API Schema Failure', 'Permission Denied', 'Successful Search'). This approach provides immediate, actionable insights while maintaining performance and avoiding the "different compliance and token issues" associated with running a second full LLM on all production data.
The PII and Privacy Challenge
Given that an MCP server processes the raw input/output of user-agent conversations, dealing with Personally Identifiable Information (PII) and sensitive data is a major concern. The responsibility for legal compliance (e.g., SOC 2, GDPR) ultimately rests with the MCP creator.
Technically, this is handled via client-side configuration. Developers must be provided with a simple, high-assurance mechanism to disable the capture of input/output data for specific tools or user segments. For example, the MCP SDK can include a configuration flag that prevents the user's raw input prompt and the tool's raw output from ever being transmitted to the analytics server, thus ensuring sensitive data integrity while still collecting essential metadata like tool name, latency, and success status.
The Future of MCP Analytics
The discussion around MCP server metrics reveals that the most complex and valuable problems in the agent economy are not purely computational—they are product and user experience problems. As LLM-based agents become the primary interface, the value of the underlying infrastructure is shifting from raw processing power to the quality of the tool ecosystem and the intelligence derived from its usage.
The architectural decision to initially use a fixed classifier for sentiment is a pragmatic one, prioritizing stability, cost efficiency, and compliance over the highly dynamic capabilities of a full LLM. However, the future clearly lies in a fully dynamic analytics engine that leverages specialized LLMs to identify novel user pain points and autonomously generate new usage clusters.
The most critical challenge moving forward remains the interplay between the technical demands of a high-performance protocol and the legal/ethical demands of handling conversational data. MCP creators must transparently disclose their data handling practices, and the underlying tooling must offer robust, client-side options for PII redaction and disabling data capture. Only through this careful balance of technical depth and ethical responsibility can the MCP ecosystem truly scale to enterprise-level adoption.
This article was inspired by insights from Shubham Palriwala, Cofounder and CEO of Agnost AI, who presented on operational and agent-focused metrics for MCP servers at the MCP Developers Summit. For more information, see the original source: The Hidden Metrics Behind Successful MCP Servers
Comments
Please log in or register to join the discussion