
New research reveals speculative decoding's true potential for accelerating LLM inference hinges on a critical factor: domain-specific draft models. While theoretical gains promise 3x speedups, real-world implementations fall short without custom training – a crucial insight for latency-sensitive AI applications.

Large Language Models (LLMs) have transformed AI, but their autoregressive nature creates an inherent bottleneck: generating each new token requires a full sequential forward pass through billions of parameters. This results in high Inter-Token Latency (ITL) and chronically underutilized GPUs during inference. Speculative decoding emerged as a promising solution, leveraging a smaller "draft" model to predict token sequences ahead of time, verified in parallel by the main model. Yet, as engineers at BentoML discovered through rigorous testing, its real-world performance hinges critically on a factor often overlooked – the alignment between draft and target model distributions.
The Draft-Then-Verify Revolution
Speculative decoding replaces slow sequential generation with parallel verification:
- Draft Proposal: A smaller model predicts k potential next tokens.
- Parallel Verification: The target LLM processes all k tokens simultaneously.
- Acceptance Check: Tokens matching the target model's predictions are accepted; the first mismatch triggers a correction.
- Resampling: The target model generates the next token post-acceptance, restarting the cycle.
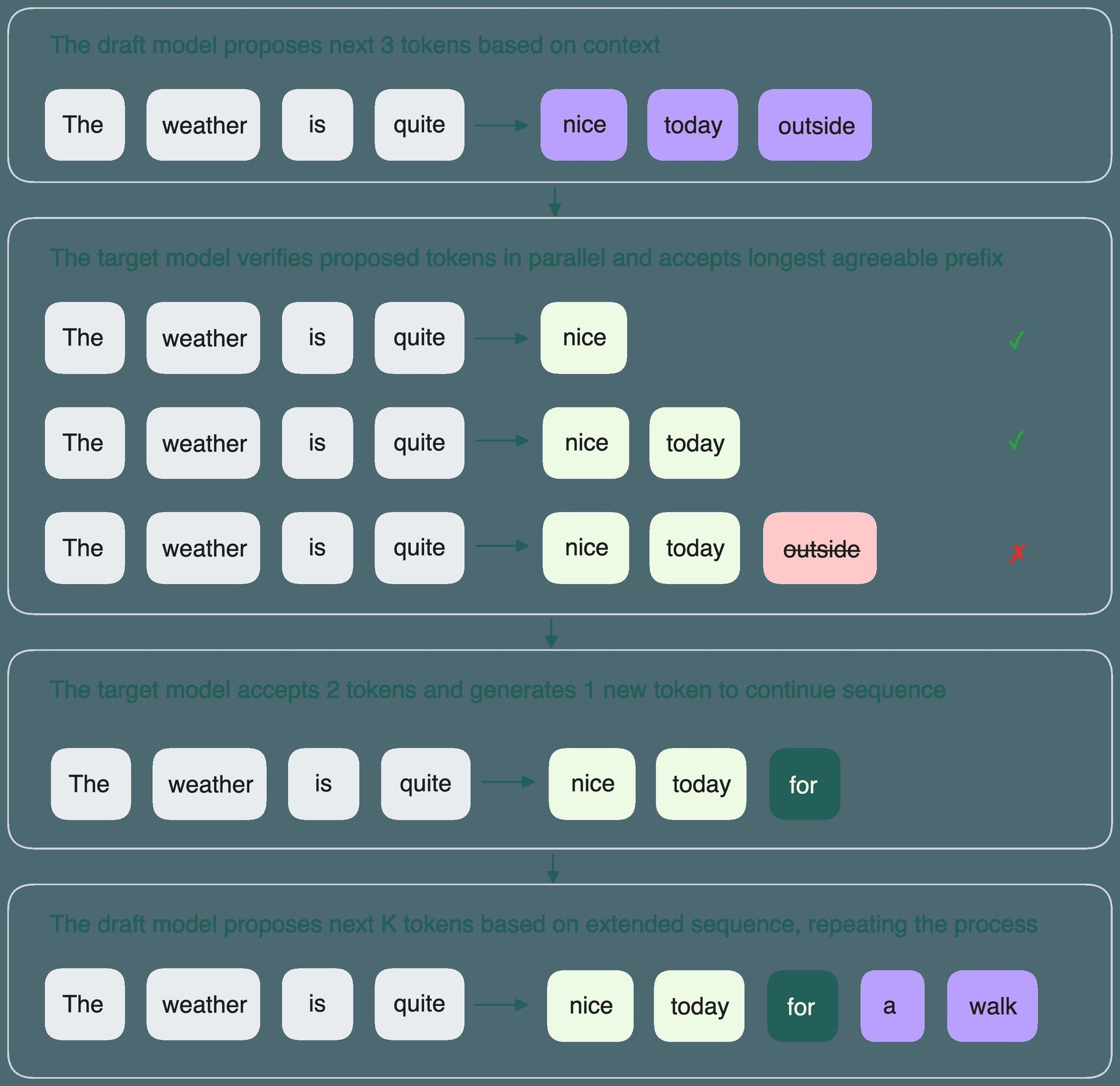
"This technique parallelizes the expensive part – the forward pass – replacing many slow sequential steps with batched verification," explain BentoML engineers Aaron Pham, Frost Ming, Larme Zhao, and Sherlock Xu. "It’s transformative for chat applications, real-time translation, and code completion where latency is critical."
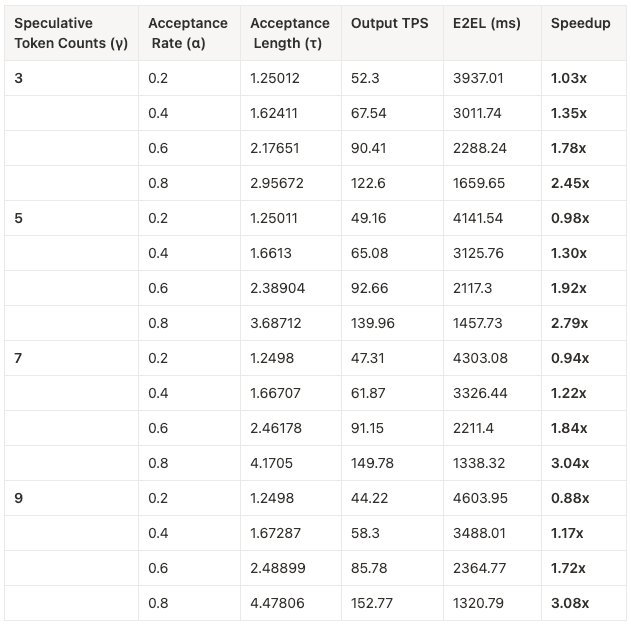
The catch? Performance lives and dies by the acceptance rate (α) – how often the target model validates the draft's predictions. Low α means wasted computation; high α delivers exponential speedups.
The Acceptance Rate Imperative
Using patched vLLM simulations, BentoML quantified α's impact:
- Theoretical Speedups: At near-perfect acceptance (α=0.95), throughput triples with 5-token drafts.
- Real-World Reality: Acceptance rates below 0.8 yield diminishing returns, sometimes even slower than baseline.
The acceptance length (τ) – average tokens accepted per round – follows:
τ = \frac{1 - α^{k+1}}{1 - α}
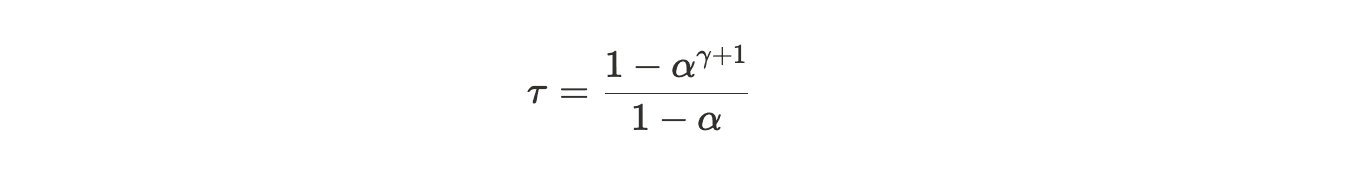
Why Off-the-Shelf Draft Models Fall Short
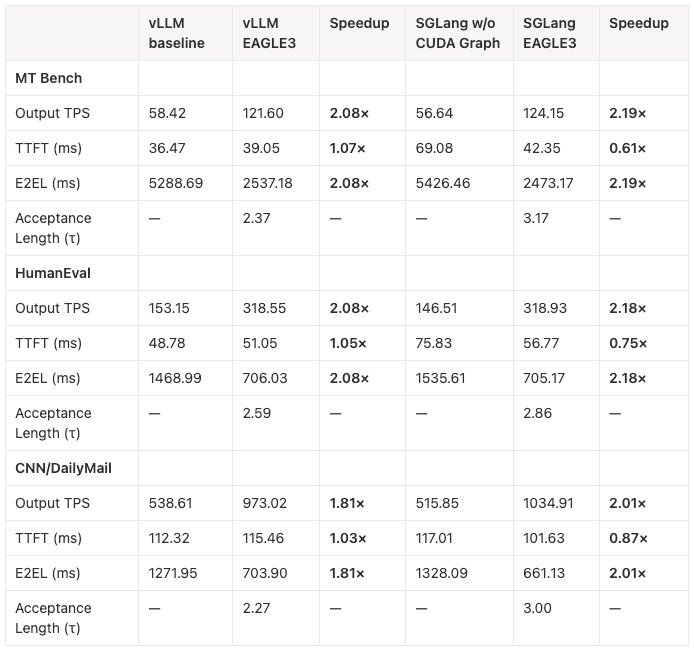
Testing EAGLE 3 (an advanced speculative technique reusing target model features) on Llama2-7B/13B revealed gaps:
| Model | Baseline TPS | EAGLE TPS | Speedup | Acceptance Length (τ) |
|---|---|---|---|---|
| Llama2-7B | 24.7 | 47.5 | 1.92x | ~2.5 |
| Llama2-13B | 17.1 | 30.9 | 1.81x | ~2.3 |
Two critical limitations emerged:
- Domain Mismatch: Draft models trained on general data struggle with specialized domains (e.g., medical, legal, code).
- Decoding Strategy Misalignment: Techniques like nucleus sampling (top-p) reduce predictability versus greedy sampling.
The Custom Draft Model Breakthrough
True acceleration requires domain-specific draft models. BentoML validated this by training an EAGLE draft model using UltraChat-200k and ShareGPT data:
# Convert datasets to ShareGPT format
python scripts/prepare_data.py --dataset ultrachat
python scripts/prepare_data.py --dataset sharegpt
# Train draft model (10 epochs)
python train.py --model meta-llama/Llama-2-7b-chat-hf --dataset ultrachat sharegpt
Results showed dramatic τ improvements, nearing theoretical speedups when the draft model understood the target domain.
Beyond Token Generation: The Latency Frontier
Speculative decoding isn't a plug-and-play panacea – it demands careful tuning. As alternative approaches like LayerSkip and MTP emerge, the core lesson remains: Acceleration requires alignment. For engineers deploying latency-sensitive LLMs, investing in custom draft model training isn’t optional; it’s the key to unlocking orders-of-magnitude gains. The era of generic inference optimization is over – specificity is the new benchmark.
Source: BentoML
Comments
Please log in or register to join the discussion