
AI
A Memcached for Attention: Inside the Cross-GPU KV Cache Marketplace for LLM Inference
11/12/2025
AI
Cascade's Predicted Outputs Turbocharges VLLM: Skip Regeneration, Not Tokens
10/10/2025
AI
The Inherent Bottleneck: Why Transformer Architecture Makes LLMs Slow at Inference
10/3/2025
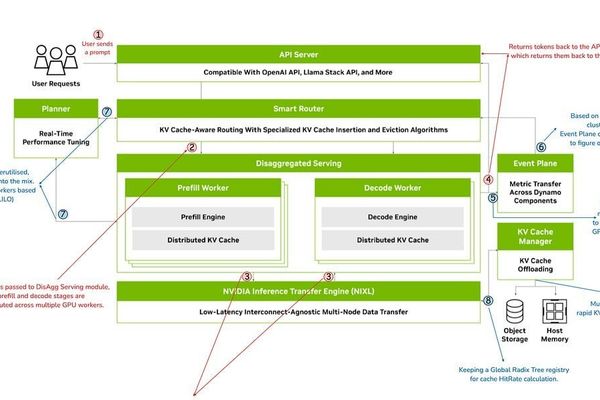
AI
Inside NVIDIA Dynamo: The Disaggregated Architecture Revolutionizing LLM Inference at Scale
9/5/2025

AI
Breaking the Autoregressive Bottleneck: How Custom Draft Models Unlock 3x LLM Speedups
8/9/2025