NVIDIA's newly open-sourced Dynamo framework rethinks large language model serving through disaggregated GPU processing, intelligent KV cache routing, and elastic resource management. This deep dive examines how its Rust-core architecture tackles the fundamental bottlenecks of LLM inference while slashing operational costs for reasoning models.
At GTC 2025, NVIDIA didn't just announce hardware—they open-sourced Dynamo, a radical reimagining of inference infrastructure that's already sending ripples through the AI engineering community. Unlike monolithic serving engines, Dynamo decouples the computationally distinct prefill and decoding phases of LLM inference across specialized GPU clusters, introducing what may be the most sophisticated distributed orchestration layer yet for production AI workloads.
The LLM Inference Bottleneck Problem
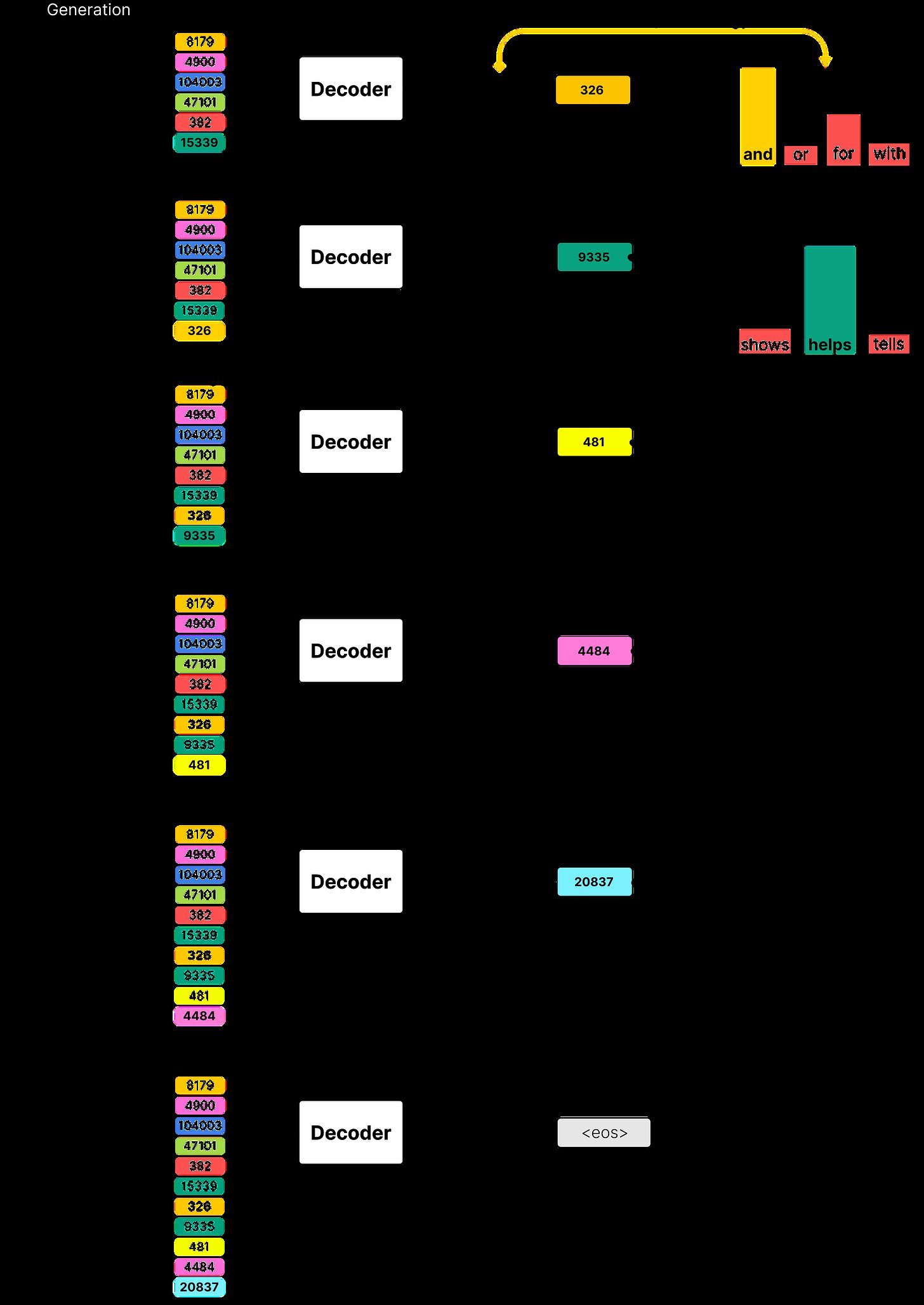
LLM inference operates in two distinct phases: the initial prefill (processing the entire prompt to generate the first token and populate KV caches) and subsequent decoding (auto-regressive token generation). Traditional frameworks handle both phases on the same GPU, creating inefficiencies:
- Prefill saturates GPU memory but is highly parallelizable
- Decoding is memory-bound and sequential
- KV cache management becomes chaotic at scale
This mismatch is exacerbated by reasoning models like DeepSeek-R1, where elongated reasoning tokens amplify resource contention. Dynamo's solution? Disaggregation.
Architectural Breakthroughs
Built primarily in Rust (55%) for performance-critical modules, with Go (28%) for orchestration and Python (10%) for glue code, Dynamo introduces four revolutionary components:
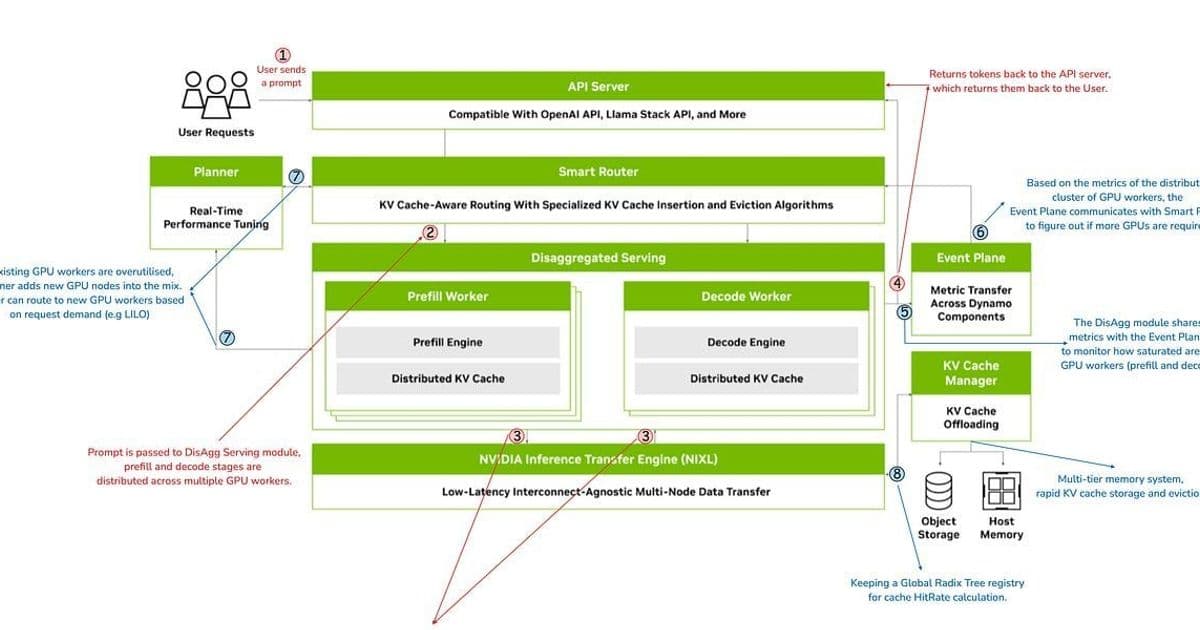
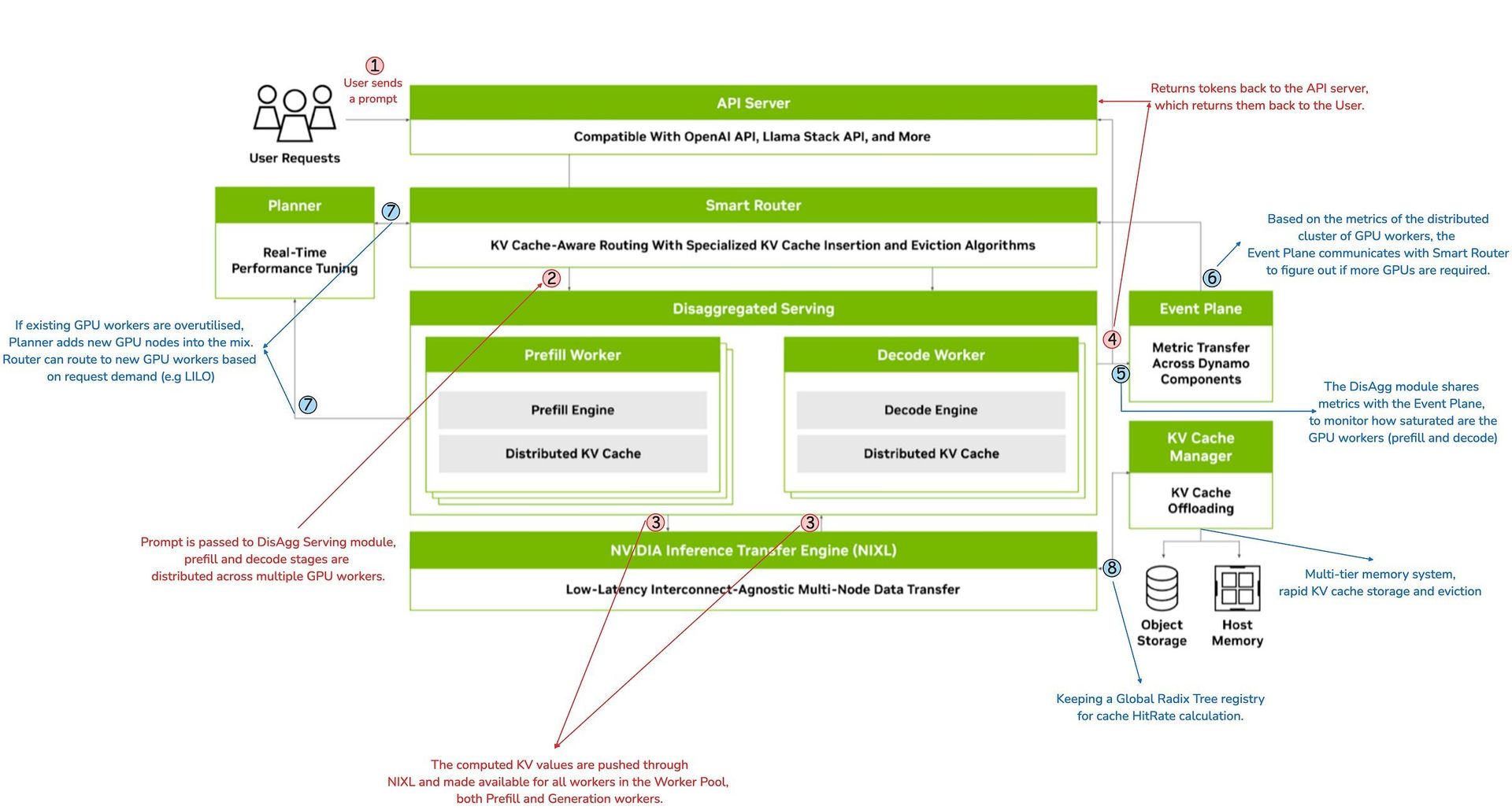
- Disaggregated Serving Engine
Dynamo dynamically routes prefill and decode workloads to specialized GPU pools. Short prefills execute locally via "piggybacking" on decode workers, while complex ones route to dedicated prefill queues backed by NATS streams. This separation allows optimal resource tuning for each phase's unique demands.
NVIDIA Inference Communications Library (NIXL)
The secret sauce enabling disaggregation. NIXL facilitates direct GPU-to-GPU KV cache transfers via RDMA, bypassing CPU bottlenecks. Its tensor-aware transport abstracts heterogeneous hardware, allowing KV blocks to move between A100s, H200s, or future architectures seamlessly.LLM-Aware Smart Router
This component uses global KV cache visibility to minimize redundant computations. Unlike vLLM's PagedAttention or SGLang's RadixAttention (which Dynamo can integrate via its event system), the router evaluates a cost function:
Route = argmin(Load + KV_{miss\_penalty})
It continuously balances cache locality against GPU utilization, dynamically routing requests to nodes with the highest relevant KV cache coverage and lowest load.
{{IMAGE:7}}
- Elastic GPU Planner & Memory Manager
Autoscaling meets AI infrastructure. The planner monitors throughput metrics via Dynamo's event plane, adding/reallocating GPUs based on request patterns (e.g., routing long-context queries to H200 nodes). The memory manager tieringly offloads inactive KV caches to cheaper storage without degrading latency.
Operationalizing Dynamo
Deploying Llama-3.2-3B demonstrates Dynamo's practicality:
# Single-node deployment
dynamo run in=http out=vllm Llama-3.2-3B-Instruct-Q4_K_M.gguf
# Multi-node cluster
node1$ dynamo run in=http out=dyn://llama3B_pool
node2$ dynamo run in=dyn://llama3B_pool out=vllm ~/models/Llama-3.2-3B-Instruct
The framework abstracts distributed complexity—developers interact through standard OpenAI API endpoints while Dynamo handles cross-node orchestration under the hood.
The New Inference Paradigm
Dynamo isn't just another serving engine; it's a fundamental shift toward treating inference clusters as composable units. By decoupling phases, introducing cache-aware routing, and enabling hardware heterogeneity, NVIDIA addresses the trillion-parameter elephant in the room: unsustainable inference costs. As reasoning models dominate the landscape, Dynamo's disaggregated approach may well become the blueprint for the next generation of AI infrastructure—where efficiency isn't optimized per GPU, but across entire data centers.
Source: Analysis based on NVIDIA Dynamo technical documentation (GitHub: ai-dynamo/dynamo) and Alex Razvant's original research (Multimodal AI Substack)
Comments
Please log in or register to join the discussion