
A survey of 1,434 experienced C++ developers finds rapid growth in AI tool adoption, but persistent data privacy concerns and mistrust of AI output could expose firms to heavy regulatory fines under GDPR and CCPA.

The Standard C++ Foundation’s 2026 annual developer survey paints a contradictory picture of AI adoption among C++ programmers, with rising usage numbers clashing against deep-seated mistrust driven in large part by unresolved data privacy risks. The poll, which drew 1,434 respondents, a 38 percent increase over 2025’s count, focuses on developers highly engaged with C++’s evolution rather than the wider casual user base. More than 26 percent of respondents work on developer tools such as compilers and code editors, 60.5 percent have over 10 years of C++ experience, and 32.7 percent have more than 20 years in the language, making this a group of seasoned professionals whose tooling choices carry weight for the broader ecosystem.
AI usage has grown across every measured category since the 2025 survey. 39.8 percent of respondents now use AI for writing code frequently, up from 30.9 percent last year. Adoption for writing tests jumped from 20 percent to 33 percent, while use for debugging rose from 11.5 percent to 23.6 percent. Despite this growth, resistance remains high: 42 percent of respondents rarely or never use AI for coding or related tasks, down only slightly from 52.7 percent in 2025.
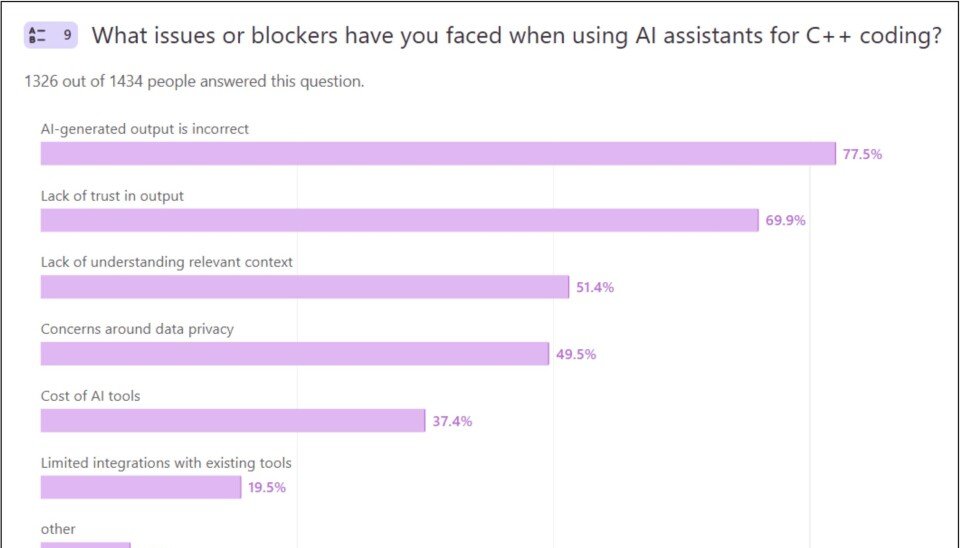
The survey highlights several core issues driving this resistance, including incorrect AI output, lack of trust in generated code, high tooling costs, and data privacy concerns. These privacy concerns are not minor technical quibbles. They represent tangible regulatory risks for developers and the companies that employ them, particularly those working in regulated industries such as healthcare, automotive, and finance where C++ remains a dominant language.
Legal frameworks such as the European Union’s General Data Protection Regulation (GDPR) and California’s Consumer Privacy Act (CCPA) impose strict rules on how personal data is collected, processed, and shared. GDPR applies to any organization handling personal data of EU residents, requiring explicit consent for data processing, data minimization, and transparency about how user information is used. Violations can result in fines of up to 4 percent of global annual revenue or €20 million, whichever is higher. CCPA grants California residents the right to know what personal data is collected about them, request deletion, and opt out of the sale of their information, with fines of up to $7,500 per intentional violation.
AI coding tools often collect user input, including code snippets, comments, and proprietary project details, to train underlying models. C++ developers working on systems that process user data, such as medical device software, automotive infotainment systems, or financial trading platforms, may accidentally input code containing personal data into these tools. If the AI vendor’s terms of service allow them to retain and reuse this data for training without explicit consent, both the developer and their employer could face regulatory penalties. Even inputting proprietary company code into non-compliant tools could violate data protection rules if that code contains user information or trade secrets protected under privacy laws.
The survey’s own data handling practices raise additional privacy questions. Write-in responses from participants are not published publicly. Instead, they are sent only to members of the ISO C++ standards committee (WG21) and product vendors, with an AI-generated summary released to the public. Respondents are not told which vendors receive their raw feedback, nor are they given an option to opt out of this sharing. For EU-based respondents, this could violate GDPR requirements for transparency about data recipients and the right to control how personal data is shared.
The AI-generated summary of write-in responses notes that C++ developers report struggles with using AI on large projects with complex build systems, alongside stronger criticisms from some participants who claim AI is "burning the planet." These technical and environmental concerns sit alongside privacy risks to create a barrier to adoption that tool vendors and standards bodies cannot ignore.
The impact of these privacy gaps extends far beyond individual developers. Companies that produce C++-based products for regulated markets face significant liability if their engineering teams use non-compliant AI tools. A single data breach caused by an AI tool leaking sensitive code or user data could trigger regulatory investigations, fines, and reputational damage. End users of these products are also at risk: if AI-generated code contains security flaws due to incorrect output, or if user data is exposed through tooling privacy gaps, millions of people could be affected. For example, a medical device running C++ code generated with a non-compliant AI tool could leak patient health data, violating HIPAA in the US or GDPR in the EU.
The C++ standards committee, which respondents generally view as essential and transparent, faces pressure to address these concerns. Many survey participants work on developer tools, meaning they are directly involved in building the AI integrations that raise privacy risks. The committee has already faced criticism for slow progress and over-complex language design, and adding privacy guidelines for tooling could further strain its resources. However, failing to address these issues could accelerate the shift to alternative languages such as Rust, which ranks 20th in RedMonk’s latest language popularity survey compared to C++’s 7th place, or Google’s Carbon, a proposed C++ successor that cites the language’s technical debt and slow evolution as key drivers for its development. The Carbon project aims to release a 0.1 evaluation version by the end of 2026, though it remains years away from production readiness.
Despite widespread dissatisfaction with C++’s complexity, including long build times, lack of a standard package manager, and memory safety gaps, usage continues to grow. SlashData estimates C++ developer numbers rose from 9.4 million in 2022 to 16.3 million in 2025, driven by demand for hardware-efficient languages in performance-critical applications. This growth makes addressing AI privacy risks even more urgent, as more developers adopt tools that could expose them to regulatory harm.
Several changes are needed to mitigate these risks. AI tool vendors must publish clear, accessible data handling policies, allow enterprise users to opt out of data collection for model training, and provide audit logs to demonstrate compliance with GDPR, CCPA, and other privacy frameworks. The C++ standards committee should develop voluntary privacy guidelines for tool vendors, and pressure survey organizers to publish anonymized write-in responses to comply with data access rights. Companies using C++ should implement strict policies governing AI tool use, train developers on privacy risks, and audit all third-party tools for compliance. Regulators should also issue targeted guidance for AI coding tools, which currently fall into a gray area in most privacy frameworks.
For now, the divide between rising AI adoption and persistent privacy concerns shows no sign of closing. C++ developers value the speed gains AI can provide but remain wary of tools that could put their projects, their companies, and their users at risk. Until privacy protections catch up with adoption, that mistrust will continue to hold back wider use of AI in one of the world’s most critical programming languages.
Comments
Please log in or register to join the discussion