
Basic TTL caching fails under massive scale. Learn how Netflix, social platforms, and e-commerce giants prevent cache stampedes through jitter, locking, and proactive expiration.
If you are building an application, you know that caching is the secret to lightning-fast performance. Instead of asking your database to do heavy lifting for every single user request, you store frequently accessed data in fast, in-memory storage like Redis or Memcached. But what happens when your app scales to handle massive traffic, like a global Netflix deployment or a viral social media platform? A basic "store this data for 5 minutes" strategy will quickly crumble. Let's explore advanced caching strategies using real-world examples to understand how top-tier systems prevent catastrophic failures.
🚨 Why Basic TTL Caching is Not Enough
The most common caching method is setting a TTL (Time-To-Live), which acts as a self-destruct timer for your cached data. While simple, relying only on basic TTL can cause massive traffic spikes that crash your database.
How Cache Expiry Can Cause Traffic Spikes
Imagine an online coding contest with 30,000+ simultaneous users constantly refreshing the leaderboard. Generating this leaderboard requires joining multiple massive database tables, taking about 5 seconds to compute. If you use a simple local cache with a TTL of 1 minute on 100 different application servers, what happens when that 1 minute is up?
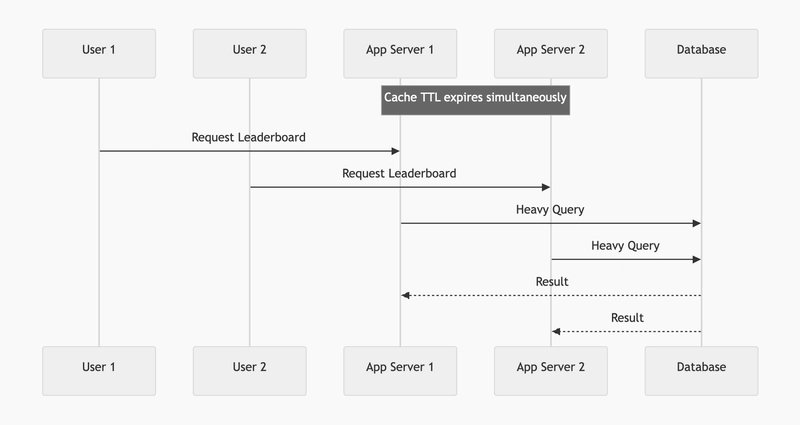
The TTL expires on all 100 servers simultaneously. In that exact moment, the next 100 users request the leaderboard. Because the cache is empty (a cache miss), all 100 servers hit the database at the exact same time to run that expensive 5-second query.
This phenomenon is known as a Cache Stampede (or "Thundering Herd"). Your database gets overwhelmed, queries queue up, and the entire system can crash.
A related issue is the Cache Avalanche. This happens when a massive batch of items—like 1,000 popular e-commerce products—are all loaded into the cache at 10:00 AM with a 1-hour TTL. At exactly 11:00 AM, they all expire at once, sending a synchronized wave of 1,000 queries directly to your database.
🛡️ Strategies to Prevent the Thundering Herd
To stop cache stampedes and avalanches, engineers have developed several advanced techniques to control exactly how and when data expires.
1. TTL Jitter – Adding Randomness to Expiration
To solve the Cache Avalanche problem, you use TTL Jitter. Instead of giving every product the exact same 1-hour (3600 seconds) expiration, you add a small, random amount of time (the "jitter") to each key.
For example, you set the TTL to: 3600 + random(0, 300) seconds
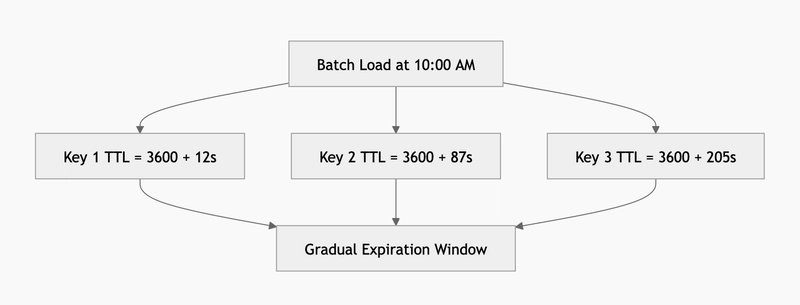
This ensures that your 1,000 product pages expire gradually over a 5-minute window rather than all at the exact same millisecond, beautifully smoothing out the load on your database.
2. Mutex / Cache Locking
To solve the Cache Stampede problem on a single wildly popular item (like a celebrity posting a viral tweet), you can use Cache Locking. This is often implemented using a pattern called Singleflight or Request Coalescing.
When the celebrity's tweet expires from the cache and millions of users request it:
- The very first request acquires a "lock" (a Mutex).
- This single request is allowed to go to the database to fetch the fresh data.
- All other concurrent requests simply wait for the first request to finish.
- They then all share the newly fetched result.
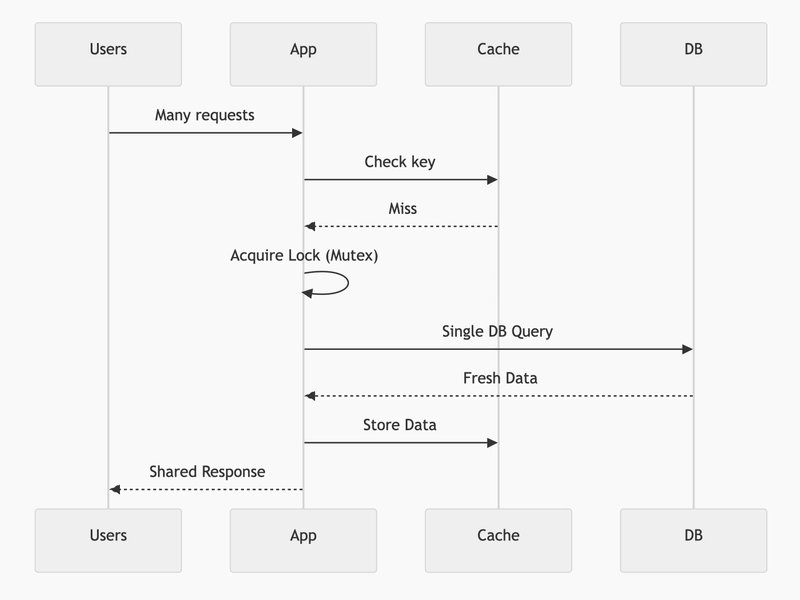
This guarantees that your database only receives one query, no matter how much traffic spikes.
3. Probability-Based Early Expiration (PER)
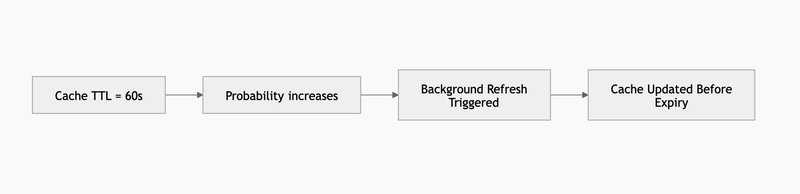
Also known as the XFetch algorithm, Probability-Based Early Expiration takes a brilliant mathematical approach to preventing stampedes. Instead of waiting for the cache to officially expire (which causes a sudden cache miss), the system randomly decides to refresh the cache before it expires.
As the expiration time gets closer, the mathematical probability of a request triggering an early background refresh increases. Because the cache is proactively rebuilt in the background before the TTL officially hits zero, users never experience a cache miss or a latency spike.
🔄 Handling Stale Data Gracefully
Stale-While-Revalidate (SWR) Strategy
Caching is always a balance between performance and freshness. The Stale-While-Revalidate strategy allows your cache to instantly serve slightly outdated (stale) content to the user, while it asynchronously fetches a fresh version from the database in the background.
This completely hides database latency from your users. For example:
- If a user requests data that just expired, they instantly get the stale version.
- Meanwhile, the system fetches a fresh version in the background.
- The next user receives the updated data.
Systems like Amazon CloudFront and modern CDNs use this heavily alongside stale-if-error (which serves stale data if the main database crashes) to ensure the system appears 100% available to users.
🔥 Proactive Caching
Cache Warming / Pre-Warming
Why wait for a user to trigger a cache miss? Cache Warming is the practice of proactively loading your cache with the most frequently accessed data before the traffic hits.
For example, before a major e-commerce flash sale:
- Run a scheduled background job.
- Fetch the top 100 products from the database.
- Push them into the cache in advance.
This can be done when the application first starts up, or via scheduled cron jobs during off-peak times, ensuring your database is protected from the initial flood of eager shoppers.
📋 When to Use Which Strategy?
Use TTL Jitter: When you are loading a massive batch of items into the cache at the same time (like a nightly catalog update) and want to prevent a database avalanche when they expire.
Use Mutex / Singleflight: When you have extremely "Hot Keys" (a viral post, a live match score) and need to ensure only one request hits the database when the cache expires.
Use Probability-Based Early Expiration (PER): When you want to entirely eliminate cache misses for high-traffic items and have the compute resources to refresh data in the background just before it dies.
Use Stale-While-Revalidate (SWR): When lightning-fast response times are your absolute highest priority, and serving data that is a few seconds old (like YouTube view counts or recommendations) is perfectly acceptable.
Use Cache Warming: When you have predictable traffic patterns (like a scheduled online contest or a morning flash sale) and want to prepopulate data before users arrive.
Comments
Please log in or register to join the discussion