
The modern data stack is rapidly consolidating around a handful of closed‑source, opinionated platforms that promise end‑to‑end analytics out of the box. This article contrasts those with open‑source, composable stacks, exploring the trade‑offs, the role of open standards, and why many enterprises are leaning toward bundled solutions.
Closed‑vs‑Open: When to Choose an Opinionated Data Platform

The data‑engineering landscape is shifting. Big players such as Databricks, Snowflake, and the recent Fivetran‑dbt merger are pushing a narrative that a single vendor can deliver ingestion, transformation, orchestration, and observability without the overhead of building a custom stack. At the same time, the open‑source community continues to thrive around tools like dbt‑core, Apache Spark, and Iceberg. Which path should a data team take?
What Is an Opinionated Data Platform?
An opinionated platform is a fully integrated, closed‑source solution that has made architectural decisions for you. Think of it as a kitchen where the chef pre‑selects the appliances, the layout, and the cooking style. The platform bundles data ingestion, transformation, scheduling, and metadata management into a single product, often exposing a no‑code UI and a declarative configuration language.
“It means the provider has beliefs about the data stack and has built all of its software around that approach.” – Source
Because the stack is pre‑wired, teams can start producing analytics in minutes, without spending weeks on CI/CD pipelines, Kubernetes clusters, or versioning each tool independently.
The Open‑Source Alternative
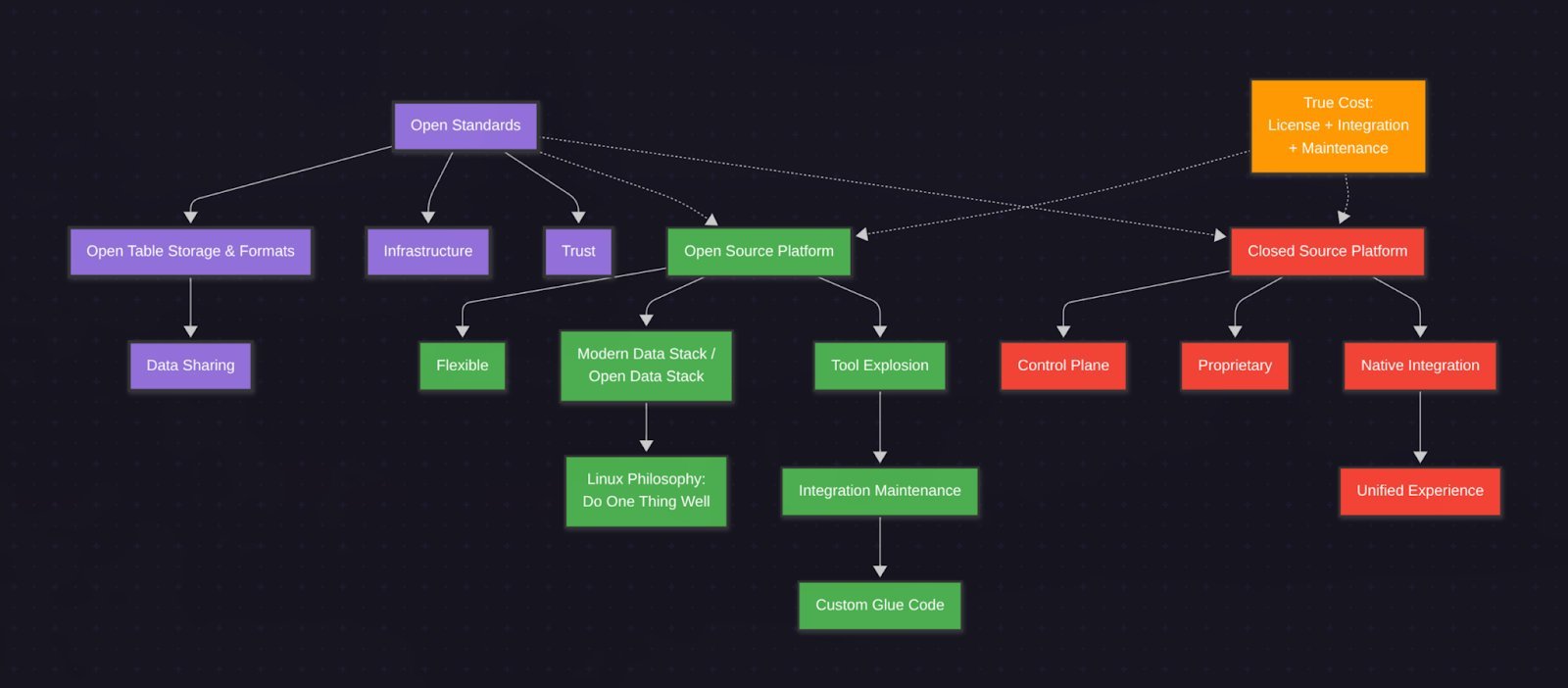
An open‑source, composable stack gives teams the freedom to pick individual tools—dbt for transformations, Airflow for orchestration, Spark for compute, and a storage layer like Iceberg or Delta Lake. This approach rewards technical depth and flexibility but demands significant engineering effort to glue components together, manage dependencies, and maintain the pipeline over time.
Hidden Costs of Fragmentation
- Engineering time – Building and maintaining a custom stack can consume 30–50% of a data engineer’s time.
- Onboarding friction – New hires must learn multiple tools and integration patterns.
- Upgrade pain – Each component has its own release cadence, leading to patch mismatches.
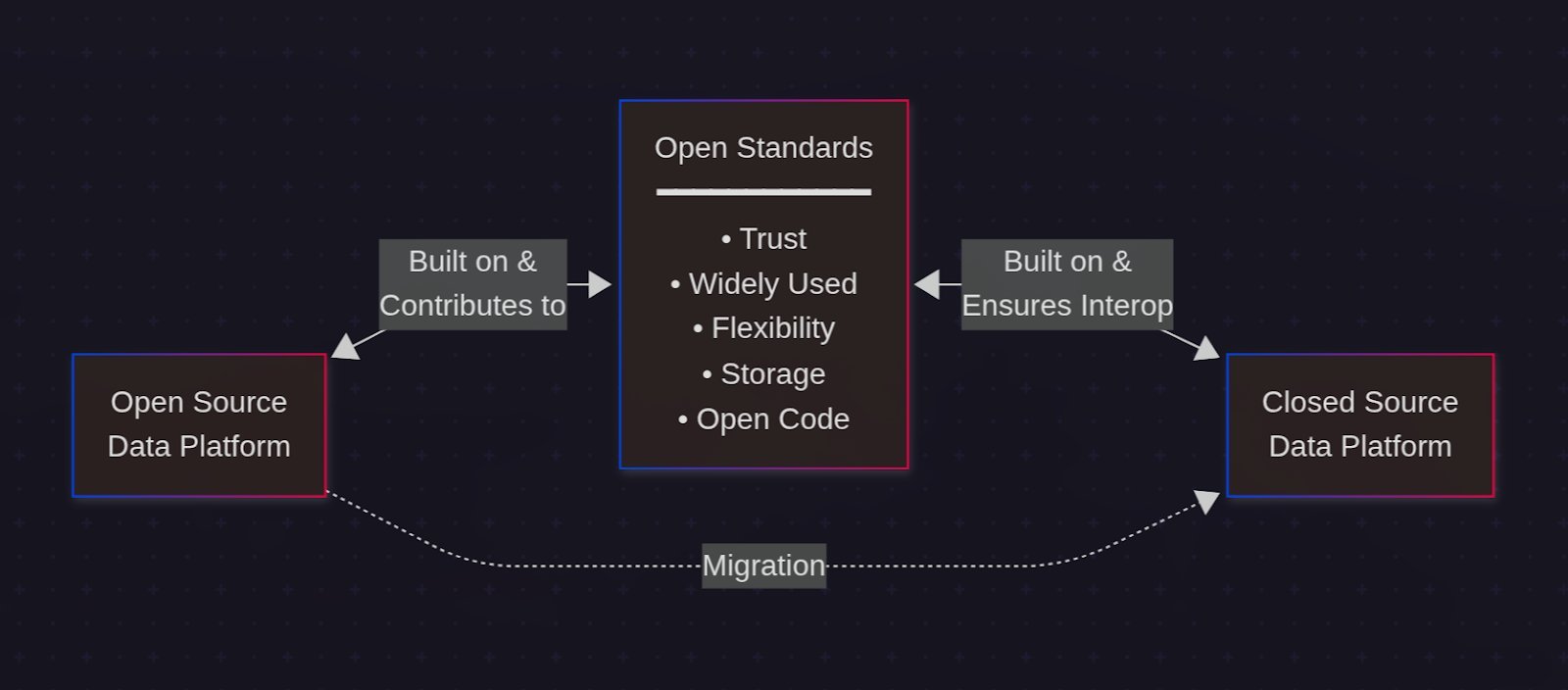
Open Standards: The Common Ground
Both closed‑source platforms and open‑source stacks increasingly rely on open standards to avoid vendor lock‑in:
- Table formats – Apache Iceberg, Delta Lake, and Hudi enable storage‑agnostic data lakes.
- Data interchange – Apache Arrow provides a columnar in‑memory format that eliminates costly serialization.
- Infrastructure as Code – Terraform and Kubernetes are widely adopted, making deployment reproducible.
These standards let organizations migrate parts of their stack or mix and match components without rewriting business logic.
The Rise of Bundled Solutions
The Fivetran‑dbt merger is a case study in consolidation. Fivetran’s ingestion layer, dbt’s transformation engine, and a unified metadata layer aim to deliver a seamless experience. The promise is clear: pay for a single subscription, get a fully managed, end‑to‑end platform.
When Closed‑Source Wins
- Rapid time‑to‑value – No need to set up CI/CD or orchestrate containers.
- Operational simplicity – The vendor handles upgrades, scaling, and security patches.
- Unified observability – Lineage, monitoring, and alerting are baked in.
When Open‑Source Is Preferable
- Maximum flexibility – Teams can experiment with cutting‑edge tools.
- Avoidance of lock‑in – Data and pipelines remain portable.
- Cost control – No subscription fees, only infrastructure costs.
A Real‑World Example: Ascend.io
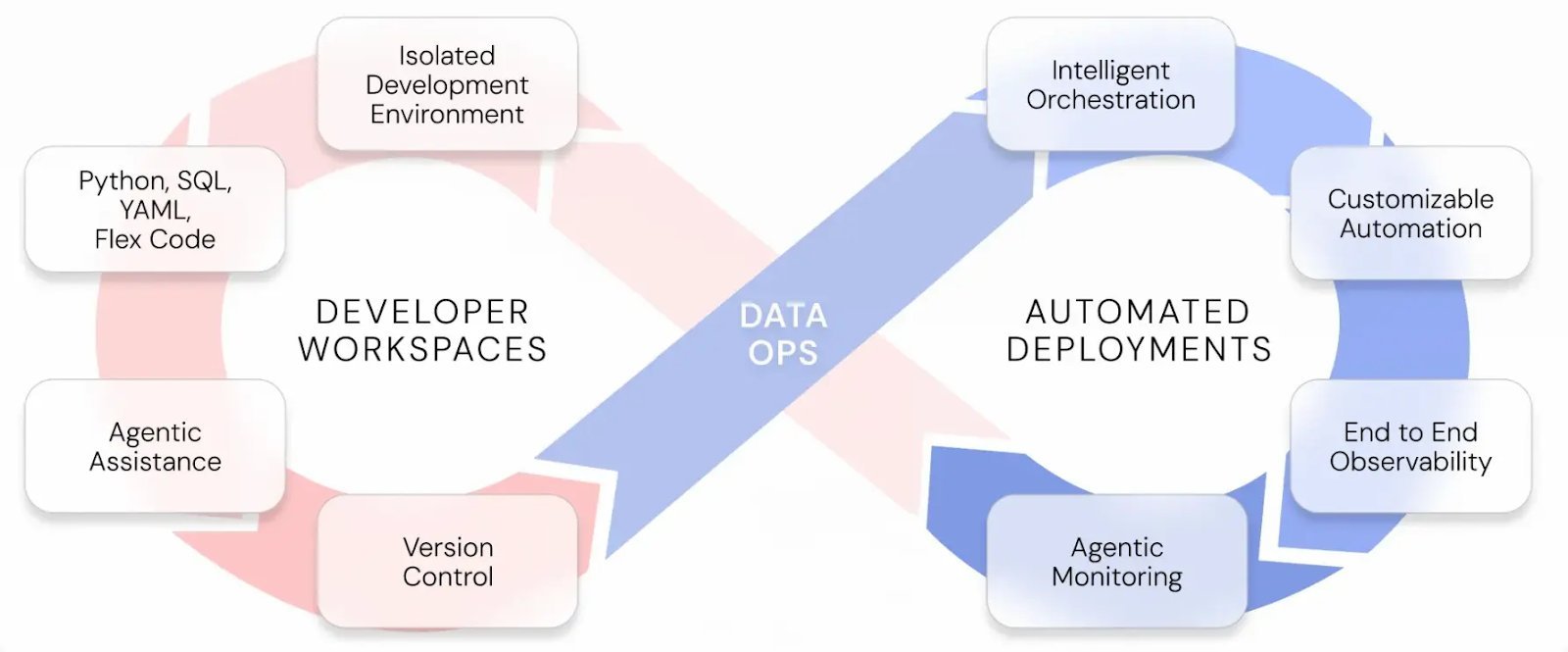
Ascend.io presents a modern, opinionated platform that automates DAG creation, separates development workspaces from deployment environments, and integrates AI agents to aid troubleshooting. While the product is proprietary, its architecture illustrates the broader trend: automation + AI + open‑standards compliance.
DataOps: The Glue That Holds It All Together
DataOps is not a tool; it’s a set of practices that span the entire data lifecycle—from ingestion to analytics. A unified platform can embed DataOps principles—version control, automated testing, continuous delivery, and monitoring—into a single workflow.
The Bottom Line
If you have deep engineering expertise and need granular control, an open‑source stack is the way to go.
If your priority is speed, reliability, and minimal operational overhead, a closed, opinionated platform can deliver value faster.
Both paths benefit from open standards, which ensure that data remains portable and that teams can evolve their stack over time.
Comments
Please log in or register to join the discussion