
Cloudflare has expanded its R2 SQL capabilities with native aggregation support, enabling SUM, COUNT, AVG, MIN, and MAX operations directly on object storage data. This architectural shift moves analytical workloads from centralized warehouses to the edge, using a distributed scatter-gather execution model to process Parquet row groups across compute nodes.
Cloudflare's announcement of aggregation functions in R2 SQL represents a significant architectural evolution for serverless data processing. The new capability allows developers to execute analytical queries directly on data stored in R2, Cloudflare's object storage service, without requiring separate data warehouse infrastructure or data movement.
From Filtering to Analytics: The SQL Expansion
R2 SQL previously supported basic filtering operations, limiting its utility to simple data retrieval. The addition of aggregation functions—SUM, COUNT, AVG, MIN, and MAX—combined with GROUP BY and HAVING clauses, transforms R2 from a passive storage layer into an active analytical platform.
Jérôme Schneider, Nikita Lapkov, and Marc Selwan from Cloudflare's engineering team explain the architectural motivation: "Whether you are generating reports, monitoring high-volume logs for anomalies, or simply trying to spot trends in your data, you can now easily do it all within Cloudflare's Developer Platform without the overhead of managing complex OLAP infrastructure or moving data out of R2."
This approach addresses a fundamental tension in cloud architecture: the trade-off between data locality and analytical capability. Traditional data warehouses excel at analytical queries but require data duplication and ETL pipelines. Object storage provides cost-effective, scalable storage but lacks native query capabilities. R2 SQL's aggregation engine attempts to bridge this gap.
Distributed GROUP BY: Scatter-Gather Architecture
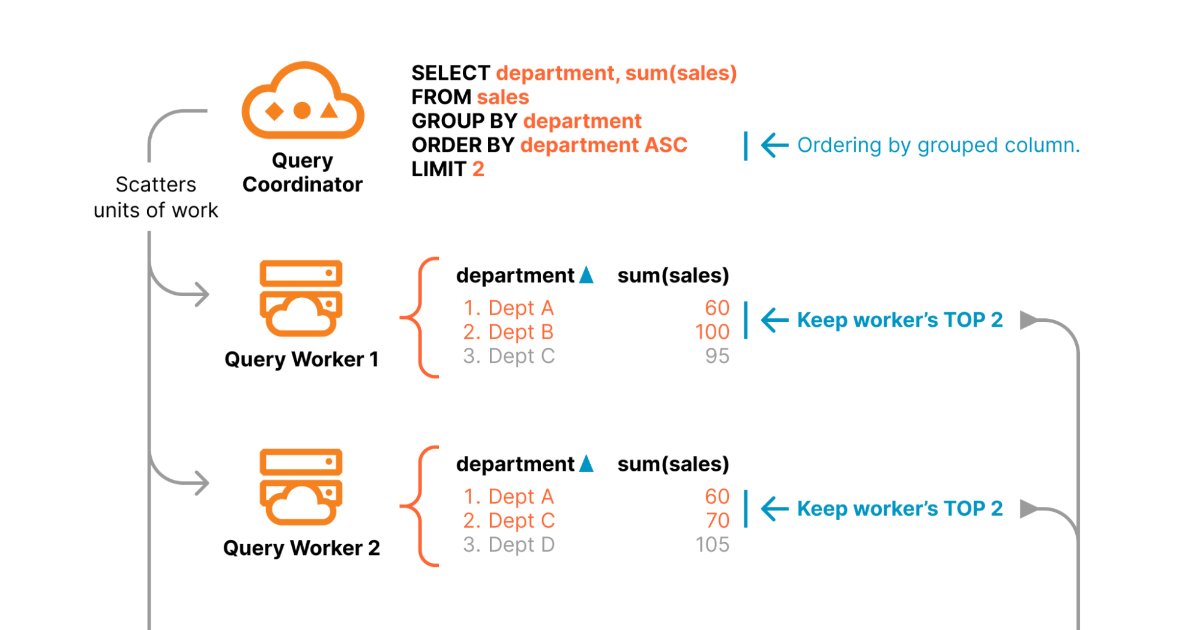
The technical implementation reveals how Cloudflare achieves analytical performance on object storage. The distributed query engine uses a coordinator-worker pattern with specific optimizations for aggregation queries.
For aggregation queries without HAVING and ORDER BY clauses, the system employs a scatter-gather strategy. A coordinator node analyzes the query and consults the R2 Data Catalog to identify which Parquet row groups contain relevant data. Each row group represents a manageable unit of work that a single compute node can process efficiently.
The coordinator distributes these row groups across multiple worker nodes, each processing its assigned segment independently. Workers compute partial aggregates for their assigned data, which the coordinator then combines to produce the final result. This parallel execution model scales horizontally with data volume, avoiding the single-node bottlenecks that plague traditional database approaches.
For more complex queries with HAVING or ORDER BY clauses, the architecture shifts to a shuffle-based execution model. This requires redistributing intermediate results between nodes, introducing network overhead but enabling more sophisticated analytical operations.
Complementary Infrastructure: Snapshot Expiration and Compaction
Cloudflare has simultaneously enhanced the R2 Data Catalog with automatic snapshot expiration for Apache Iceberg tables. This metadata management feature works in concert with existing automatic compaction, which optimizes query performance by merging small data files into larger ones.
Marc Selwan notes the synergy: "These go hand in hand because the metadata cleanup/management that snapshot expiration helps with will speed up performance of these aggregation queries, especially with compaction enabled."
The relationship between these features illustrates a critical principle in distributed data systems: query performance depends as much on metadata efficiency as on compute power. Snapshot expiration prevents metadata bloat that would slow query planning, while compaction reduces the number of files the query engine must scan.
Architectural Implications and Trade-offs
This development reflects a broader trend toward edge analytics, where data processing occurs closer to the data source rather than in centralized warehouses. Jeremy Daly, director of research at CloudZero, observes: "Cloudflare continues to push data closer to the edge with aggregation support in R2 SQL, expanding the kinds of workloads developers can realistically run there."
The architectural trade-offs are significant:
Advantages:
- Reduced data movement costs and latency
- Simplified architecture with fewer moving parts
- Real-time analytics on fresh data
- Cost-effective for workloads that don't require full warehouse capabilities
Limitations:
- R2 SQL remains in public beta, with grammar and features subject to change
- Performance characteristics differ from dedicated analytical databases
- Complex analytical workloads may still require specialized tools
- The scatter-gather model introduces network latency for distributed queries
Practical Applications and Use Cases
The aggregation capabilities enable several concrete use cases:
Log Analytics: Organizations can monitor high-volume logs for anomalies directly in R2, identifying patterns without shipping logs to separate analytics platforms.
Report Generation: Business metrics can be computed on-demand from operational data stored in R2, reducing the need for pre-aggregated reporting tables.
Trend Analysis: Time-series data can be aggregated to reveal patterns, with queries running directly against the source data.
Data Exploration: The addition of schema discovery commands (SHOW TABLES and DESCRIBE) enables interactive exploration of datasets stored in R2.
Implementation Considerations
Developers adopting R2 SQL aggregations should consider several factors:
Query Complexity: The current implementation has limitations documented in the official documentation. Complex analytical queries may require architectural adjustments.
Data Organization: Effective aggregation queries depend on appropriate data partitioning and file organization in R2. The Parquet format's row group structure significantly impacts performance.
Cost Model: While R2 storage is cost-effective, compute costs for distributed query execution should be evaluated against traditional warehouse pricing.
Migration Path: Organizations with existing analytical pipelines should assess whether R2 SQL can replace or complement their current data warehouse infrastructure.
The Broader Context
This announcement fits within Cloudflare's ongoing expansion of its Developer Platform. Recent additions include global read replication for D1 database, remote bindings for local development, and containers in public beta. Each enhancement moves Cloudflare toward a comprehensive edge computing platform that spans storage, compute, and data processing.
The aggregation engine in R2 SQL represents a specific architectural choice: bringing analytical capabilities to object storage rather than moving data to analytical databases. This approach aligns with the principle of data locality, reducing network transfer costs and latency while maintaining the scalability and cost-effectiveness of object storage.
For organizations evaluating their data architecture, R2 SQL aggregations offer a middle ground between simple key-value storage and full data warehouses. The scatter-gather execution model provides a scalable foundation for analytical workloads, though with different performance characteristics than traditional OLAP systems.
As R2 SQL continues its public beta journey, the supported SQL grammar and performance optimizations will evolve. The current implementation provides a functional foundation for edge analytics, with architectural patterns that may influence how distributed query engines approach object storage in the future.
Resources:
Comments
Please log in or register to join the discussion