
Exploring why traditional offline evaluation fails for recommendation systems and how counterfactual methods like Inverse Propensity Scoring provide more accurate intervention-based assessment.
When beginning work with recommendation systems, many notice a fundamental disconnect in standard evaluation practices. We typically train models on historical interaction data and measure performance using metrics like recall or NDCG on held-out validation sets. At first glance, this supervised learning approach seems reasonable—but recommendation systems aren't observational problems where we passively predict outcomes. They're fundamentally interventional systems where the recommendations actively shape user behavior.
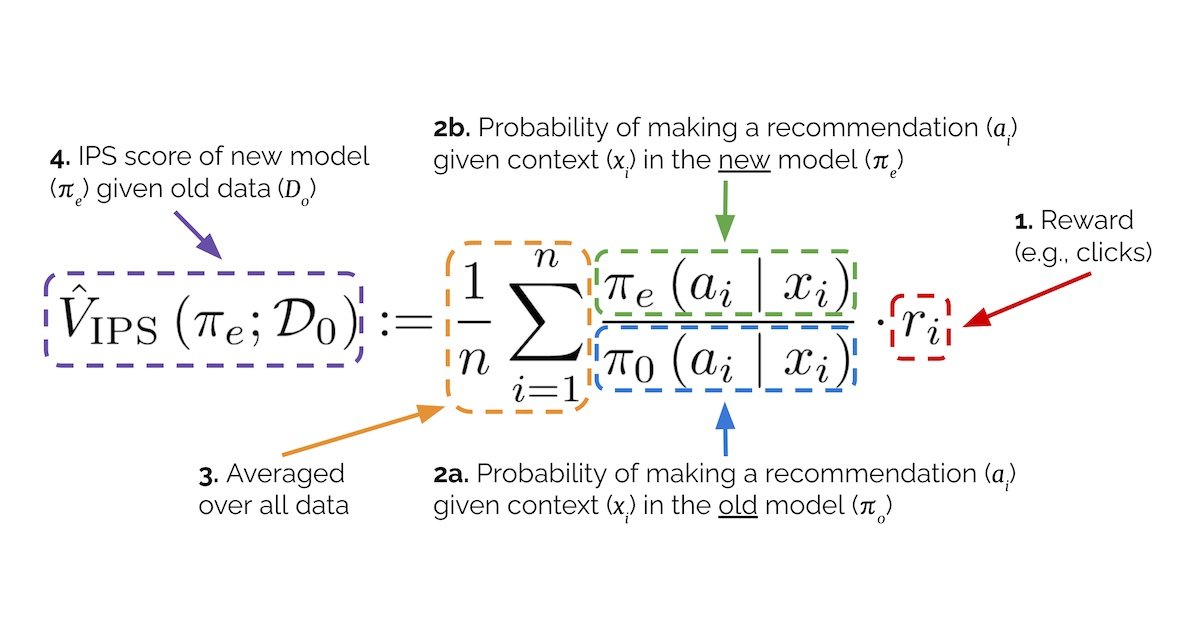
The core issue lies in using static historical data for evaluation. Since users can only interact with items presented to them, traditional offline assessment evaluates how well new recommendations fit existing logs rather than measuring how they'd actually change user behavior. This approach estimates P(click|historical views) when what we truly need is P(click|recommendation intervention).
The intervention-aware solution comes through counterfactual evaluation, which answers: "What would happen if we showed users our new recommendations instead of the current ones?" The most established technique—Inverse Propensity Scoring (IPS)—reweights logged interactions based on how recommendation probabilities differ between models. Consider an iPhone recommendation on a Pixel product page:
- Existing system (π0) recommends iPhone 40% of the time
- New system (πe) recommends it 60% of the time
The importance weight becomes πe/π0 = 1.5. Each logged iPhone interaction now counts as 1.5 events when estimating the new model's performance, since the recommendation would appear more frequently.
Implementation requires recommendation probabilities, obtainable through:
- Normalizing recommendation scores (Plackett-Luce)
- Frequency counts in recommendation stores
- Direct impression logging
IPS faces two main challenges. First, insufficient support occurs when new recommendations lack logged data (π0=0), solvable by exploratory data collection via deliberate randomization. Second, high variance emerges when probability ratios become extreme—like a 100x weight from a rare recommendation becoming common. Solutions include:
- Clipped IPS (CIPS): Caps weights at a threshold
- Self-Normalized IPS (SNIPS): Divides estimates by average weight
Recent comparisons using Open Bandit Pipeline show SNIPS outperforms IPS and CIPS in accuracy while avoiding parameter tuning. One tradeoff: SNIPS requires computing weights for all observations (not just positive interactions), increasing storage needs.
Traditional offline evaluation retains value for benchmarking and pre-deployment testing, especially with public datasets. But when online A/B tests prove impractical or offline metrics diverge from live results, counterfactual methods like SNIPS offer powerful alternatives. These techniques extend beyond recommendations to any scenario requiring offline A/B test simulation.
Comments
Please log in or register to join the discussion