A practical breakdown of foundational AI architecture patterns, explaining component responsibilities and system design trade-offs.
Building AI applications introduces unique architectural challenges distinct from traditional software systems. The core confusion often isn't about selecting models, but about structuring components effectively: Where should conversational memory reside? When should external data be retrieved? What executes where? Understanding these boundaries prevents costly anti-patterns and creates maintainable systems.
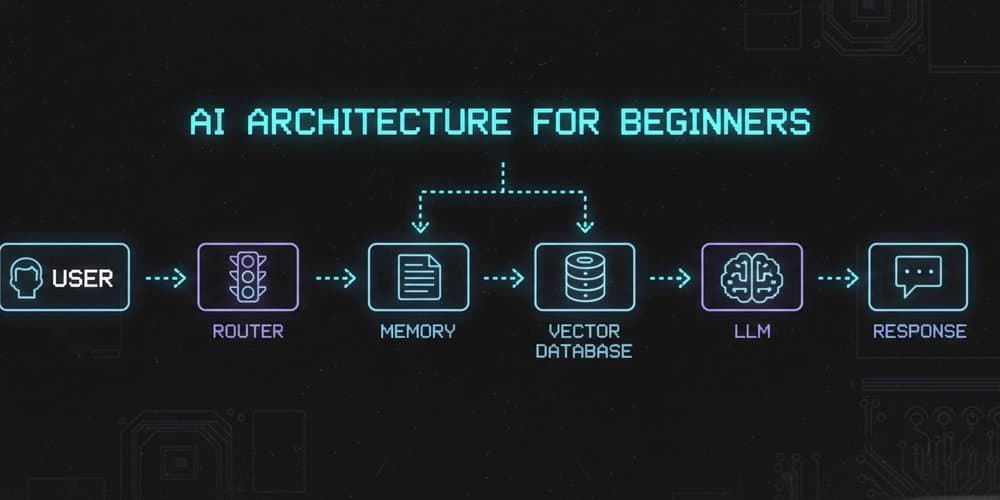
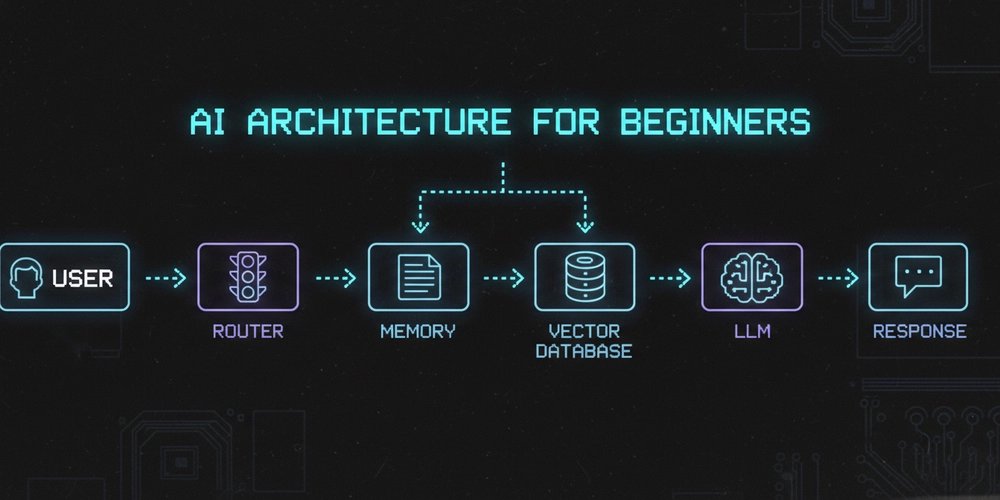
Core Architectural Components
AI applications typically decompose into four specialized components, each with explicit responsibilities:
Large Language Model (LLM) - Computational Engine
- Function: Performs text transformation tasks (generation, summarization, code explanation). Uses statistical patterns to process input sequences into output sequences.
- Constraints: Stateless by design. Cannot actively retrieve information or maintain conversation context beyond its fixed input window (typically 4K-128K tokens).
- Trade-off: High computational cost per token (~2-3x more than database queries) makes indiscriminate use prohibitively expensive. Requires careful request batching and optimization.
Router - Request Dispatcher
- Function: Determines request processing path based on content analysis. Decides whether to invoke the LLM directly, retrieve external data, or execute application logic.
- Implementation: Often rule-based (regex/pattern matching) or a lightweight classifier model.
- Trade-off: Adds latency (10-150ms) but reduces LLM costs 30-70% by avoiding unnecessary invocations. Failure points include misclassification cascades where valid requests get incorrect paths.
Memory - Short-Term Context Manager
- Function: Maintains ephemeral session state (last 5-10 message exchanges, user preferences). Provides conversation continuity within a single interaction session.
- Implementation: In-memory store (Redis/Memcached) with TTL expiration.
- Trade-off: Low-latency access (<5ms) but volatile storage. Not suitable for historical data retrieval. Scaling requires careful session sharding strategies.
Vector Database - Long-Term Knowledge Repository
- Function: Stores domain-specific data (docs, logs, FAQs) encoded as numerical vectors. Enables semantic similarity searches instead of keyword matching.
- Implementation: Tools like Pinecone, Chroma, or pgvector.
- Trade-off: Enables contextual accuracy with 90%+ relevance in retrieval-augmented generation (RAG) patterns. However, introduces 100-400ms latency per query and requires dedicated infrastructure.
System Flow: Authentication Failure Example
Consider a user query: "Why am I getting 401 errors on checkout?"
- Router analyzes request, determines external data needed
- Vector DB queries authentication logs using semantic similarity
- Memory injects recent conversation context ("user updated payment method 2 minutes ago")
- LLM synthesizes response from retrieved logs, context, and error patterns
Critical Anti-Patterns
- Monolithic Prompting: Combining routing, data retrieval, and generation in single LLM call increases token costs 300% and creates unpredictable failure modes.
- Memory Misuse: Using volatile memory for persistent storage causes data loss. Requires clear TTL policies and write-through to databases.
- Router Bypass: Sending all requests directly to LLMs ignores cost/accuracy benefits of retrieval systems.
- Vector DB Overfetching: Returning too many context chunks (exceeding LLM's context window) truncates critical information.
Architectural Trade-offs
| Component | Benefit | Cost |
|---|---|---|
| Modular Design | Independent scaling, easier debugging | Inter-component latency (50-200ms) |
| Router | Reduced LLM costs, targeted processing | Classification accuracy risks |
| Separate Memory/DB | Optimal performance for distinct use cases | Data synchronization complexity |
Scaling Considerations
- Stateless LLMs: Horizontally scale via load balancing
- Vector DBs: Require sharding and specialized hardware (GPU acceleration)
- Memory: Demands high-availability configurations to prevent session drops
This separation of concerns creates adaptable systems. You can integrate authentication via OAuth proxies, add monitoring with OpenTelemetry, or incorporate tool execution (Python/SQL) without structural changes. Understanding these boundaries transforms AI from perceived magic into predictable engineering discipline.
Heroku Integration Example
Tools like Cursor demonstrate how editors connect to platforms like Heroku via Managed Control Planes. This enables triggering deployments or scaling directly from your IDE, reducing context switching. See the Heroku-Cursor integration demo for implementation details.
Comments
Please log in or register to join the discussion