
Aleksey Charapko's analysis reveals why metastable failures—self-sustaining performance collapses—are systemic threats in distributed systems and why they defy simple solutions.
When distributed systems fail, the most dangerous scenarios aren't transient glitches but self-perpetuating death spirals. Aleksey Charapko's latest work dissects metastable failures—a class of systemic collapse where an initial fault triggers a positive feedback loop that persists even after the root cause disappears. These cascading failures plague everything from cloud infrastructure to financial systems, yet their prevention remains notoriously elusive.
The Anatomy of a Feedback Loop
At the heart of metastable failures lies a destructive cycle: a problem causes degraded performance, which prompts reactive behaviors that unintentionally amplify the issue. Charapko illustrates this with the classic retry storm scenario:
- A server experiences transient overload, slowing response times
- Clients timeout and retry requests
- Retries compound server load
- Latency worsens, triggering more retries
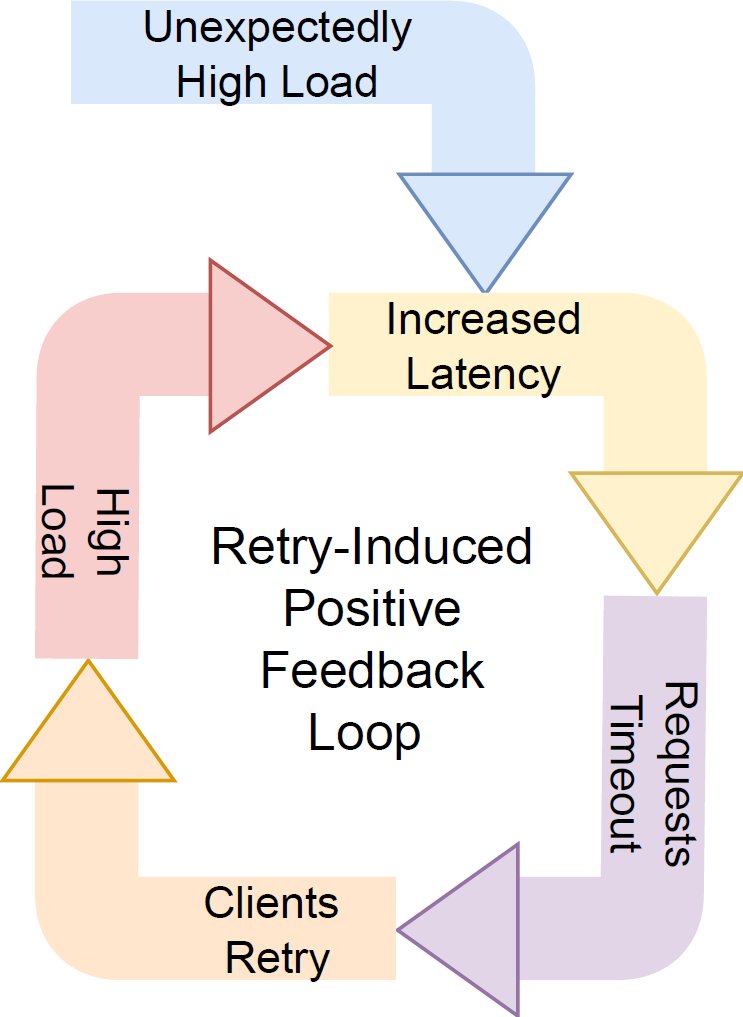 Metastable retry loops turn temporary hiccups into sustained outages. (Source: Aleksey Charapko)
Metastable retry loops turn temporary hiccups into sustained outages. (Source: Aleksey Charapko)
This loop transforms a recoverable incident into a sustained outage. As Charapko notes: "The sustaining effect is the defining characteristic—break the loop, and recovery becomes trivial."
Signals, States, and Ambiguous Actions
Charapko models systems as networks of components that observe signals and act, creating state changes that emit new signals. In the retry storm:
- Signals: Timeouts and latency (observed by clients)
- Actions: Retries (executed by clients)
- State changes: Increased server load
The critical flaw? Signals are ambiguous. A timeout could indicate either:
- A transient network hiccup (where retries help)
- Systemic overload (where retries worsen failure)
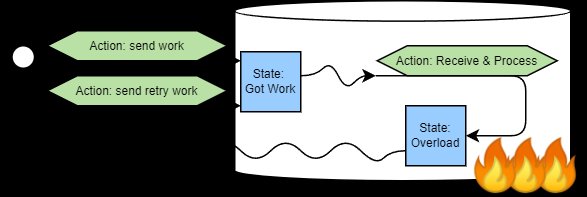 Systems interpret ambiguous signals like timeouts identically despite different underlying states. (Source: Aleksey Charapko)
Systems interpret ambiguous signals like timeouts identically despite different underlying states. (Source: Aleksey Charapko)
"We don't want to retry when the system is overloaded," Charapko emphasizes, "but the signal—timeout—looks identical in both scenarios." This ambiguity fuels the feedback loop.
Why Prevention Fails
Charapko examines three prevention strategies and their practical limitations:
Avoid interactions between components
- Problem: Modern systems require interactions for functionality
- Example: Servers can't ignore incoming requests without breaking functionality
Eliminate feedback-creating actions
- Problem: Core features rely on these actions
- Example: Removing retries sacrifices fault tolerance for transient errors
Eliminate signal ambiguity
- Problem: Distinct states often produce identical signals
- Example: Distinguishing overload from network failure requires additional instrumentation
 Avoiding metastable failures requires tackling signal ambiguity—a fundamental challenge. (Source: Aleksey Charapko)
Avoiding metastable failures requires tackling signal ambiguity—a fundamental challenge. (Source: Aleksey Charapko)
Even distributed transactions face this trap: Protocols like Two-Phase Commit mandate actions (waiting or aborting) that inadvertently increase contention when systems are stressed.
The Mitigation Imperative
Charapko concludes that elimination is unrealistic for complex systems: "I have a hunch that we may not be able to avoid metastable failures entirely in large, non-trivial systems that are economical to operate." Instead, he advocates:
- Circuit breakers: Temporarily disable actions (like retries) when failure rates exceed thresholds
- Multi-signal heuristics: Combine metrics (e.g., timeouts + CPU load) to disambiguate states
- Load shedding: Prioritize critical requests during degradation
These approaches accept metastability as an inherent risk while containing its blast radius. As distributed systems grow more interconnected, Charapko's framework provides essential vocabulary for designing failure-aware architectures—not by chasing impossibility proofs, but by strategically managing feedback loops.
Explore Charapko's full analysis including visualizations of metastable failure patterns.
Comments
Please log in or register to join the discussion