
NVIDIA acquires Groq's LPU technology to boost Vera Rubin NVL72 rack performance, addressing the critical latency-versus-throughput trade-off in AI inference.
Among a plethora of announcements coming out of NVIDIA this week for their 2026 GTC AI conference, arguably the highest profile announcement was about a hardware technology that is not quite NVIDIA's own: the Groq Language Processor Unit, or LPU. On Christmas Eve of 2025, in a deal reportedly worth $20 billion NVIDIA made a major future architectural shift. Per that deal, NVIDIA hired a significant number of the company's senior staff, acquired its physical assets, and also acquired a non-exclusive license to Groq's chief technology, its LPU. It was a deal that raised significant questions about just what NVIDIA was hoping to do, why they were spending so much money on a struggling competitor, and why they seemed to be in such a hurry to acquire a company when half the world has already kicked off its holiday break. The answers to those questions, CEO Jensen Huang told investors and the public during the company's Q4'FY2026 earnings call, would come during GTC. And with day one of the show having wrapped up, headlined by Huang's critical visionary keynote, we finally have those answers.

In short, NVIDIA has acquired Groq's technology in order to boost its own inference performance for its high-end, rack-scale systems. With Groq's inference-focused LPUs having been designed for low-latency AI inference, NVIDIA will be using Groq's hardware as an accelerator for Vera Rubin NVL72 racks, in the form of the NVIDIA Groq 3 LPX rack, delivering higher (and quicker) token throughput rates than NVIDIA's GPUs can provide alone. The ultimate goal for NVIDIA is that the inclusion of Groq LPUs not only boosts the overall performance of Vera Rubin racks but also offers a substantial boost in the kind of low-latency performance that agentic AIs need to quickly react to one another, and to which AI customers are willing to spend a premium.
A Classic Case of High Throughput Versus Low Latency
While NVIDIA's acquisition of Groq's assets was relatively sudden, the problem at hand has been one that NVIDIA has been wrangling with for some time now. The company's GPUs, the backbone of their AI efforts, are fundamentally high-throughput processors. With their massive arrays of ALUs, GPUs specialize in efficiently processing massive amounts of data. In order to maximize the total amount of data they process, the trade-off they make is that they are not very quick about it in regard to latency. As a result, fully utilizing a GPU, be it for classical compute or AI workloads, involves using a number of tricks to hide latency and context switch between threads so that the GPU always has something to work on while its memory and cache subsystems are fetching the next block of instructions and data for another group of threads.

All this hyper-optimization for throughput means GPUs are poorly suited to low-latency operation. The qualities that make a processor good at low-latency computing, such as a large number of registers, copious caches, and execution units to provide beefy instruction-level parallelism, make for poor GPUs. The hardware needed to provide efficient, low-latency compute would eat into die space that could instead go towards more ALUs for higher GPU throughput.
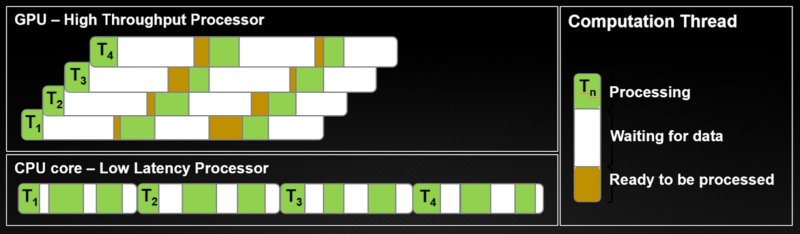
This, in a nutshell, is the classic CPU/GPU trade-off. NVIDIA's compute empire is, by and large, built on (correctly) predicting that most workloads benefit from high throughput more than they benefit from low latency. This is why many classic computing workloads are becoming GPU-accelerated these days. In the AI space, it is even more evident that CPU-only AI inference is hardly a consideration in most cases.
This kind of throughput/latency tradeoff extends into AI inference as well. Even if you have already decided to use a GPU, it is possible to tune its performance and the software running on it to favor throughput or latency, a performance curve exists between the two, where system operators can slide between them. This has been the crux of NVIDIA's performance argument up through the Grace Blackwell generation. NVIDIA's GPUs can produce a large number of tokens when optimized for throughput, fewer when optimized for low latency. Customers can focus on finding the optimal (Pareto) region along that curve to reduce latency while still achieving relatively high total throughput.
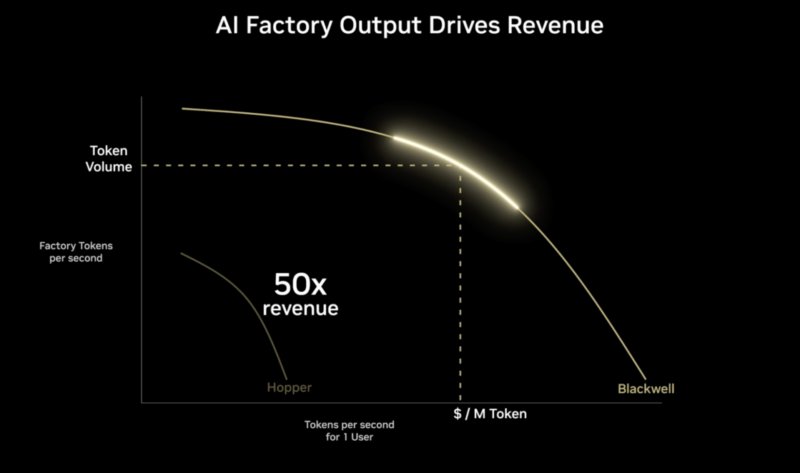
It is an argument that was not on entirely solid footing in 2025, and is on even rockier footing in 2026. The optimal operating points for a GPU do not offer latencies low enough for the kind of rapid-fire single-user token rates that NVIDIA believes are needed for agentic AI. Latency becomes a key differentiator as humans are removed from high-value workflows.
Accelerating the Accelerator: Groq Language Processor Units
While NVIDIA has been dealing with how to achieve lower latencies from high-latency GPUs, some of its competitors have been tackling the problem from the other direction, designing inference accelerators that are low-latency from the start. Chief among these has been Cerebras and Groq. Groq's chief technology was the Tensor Streaming Processor, later rebranded as the Language Processor Unit (LPU).
While not by any means a CPU, Groq's LPU employs numerous design decisions that favor low-latency execution of tensors and other AI math over high throughput. The end result of those design decisions is that Groq's LPU technology is wildly different from NVIDIA's GPU. For NVIDIA, this is a fantastic thing.

While we will not go into the nitty-gritty of Groq's LPU architecture at this time, there are a few key design elements that allow it to offer such low latencies. Key among these is SRAM: Groq's chips feature a ridiculous amount of on-chip SRAM for their size and performance levels. The LP30 chips NVIDIA will use have 500 MB of SRAM. This is all on-die, so there is a massive 150 TB/second of memory bandwidth between these SRAM blocks and the compute elements on the LP30. As a result, it allows the compute elements to access any local data they need extremely quickly, even faster than what we think of as fast for NVIDIA's HBM-equipped GPUs.
The other interesting aspect of Groq's architecture is that it is deterministic. Instead of scheduling in hardware, as is common in CPUs and GPUs, instruction scheduling is handled entirely by the compiler ahead of time. Thus, the code emitted by the compiler knows exactly what the LPU will be doing at any given time. This kind of static instruction scheduling is not new to Groq's hardware. In fact, it is a common sight amongst VLIW designs, but it is one of the big factors in the hardware's low latency because there's no need to guess (or stall for) when a piece of data will be available or when an instruction will complete; everything is executing along a very carefully orchestrated series of events.
NVIDIA's Groq LPUs: Decode Specialists
Ultimately, Groq's hardware design not only makes the architecture good at low-latency inference but also makes it especially good at one specific aspect of inference: decode. The second stage of traditional inference methods, the decode stage, is where tokens are actually generated, consuming prefilled data (key values) to generate the output tokens. Whereas prefill is largely a compute-bound, highly parallel action, decode is far more serial in nature and sensitive to memory performance. Each successive token depends on the output of the previous token. There are a few good shortcuts here for high-throughput processors like GPUs, as they cannot move on to the next token for a user until the previous token has been returned. This makes low-latency performance critical, as lower latency means the current token will be complete that much sooner.
As a result, for high-end Vera Rubin rackscale systems, NVIDIA will split the inference process between Rubin GPUs and Groq LP30 LPUs. NVIDIA is taking a hyper-specialized route, running not only the prefill process on their GPUs, but also the sub-tasks of the decode process that still benefit from throughput, such as the attention phase of decoding. Meanwhile, the LPU gets to handle things such as the execution of feed-forward networks (FFNs). By doing this, NVIDIA effectively offloads only the parts of the decode phase that Groq's LPUs are super-fast at. In essence, NVIDIA is addressing the GPU latency-versus-throughput trade-off with a chip that does the opposite.
It goes without saying that none of this is free. Not in terms of hardware, not in terms of power budgets, and not in terms of overall complexity (this effectively turns a Vera Rubin rack into a heterogeneous system). It gives NVIDIA upwards of 35x the throughput (versus Grace Blackwell) at a given tokens-per-second-per-user generation rate, and it allows NVIDIA to viably extend their performance curve to far higher TPS-per-user rates than what Vera Rubin could achieve as just a GPU+CPU system. All of which, in turn, allows for more responsive AI models/agents and for the longer contexts (at acceptable performance levels) that these models need to deliver their best performance.
Comments
Please log in or register to join the discussion