
DeepSeek has released DeepSeek V4, a pair of open‑weight language models that claim to rival top proprietary LLMs while cutting inference costs dramatically. The release includes a smaller Flash variant and a larger Pro model, both supporting Huawei Ascend NPUs and using novel attention mechanisms and low‑precision data types to reduce memory and compute needs.
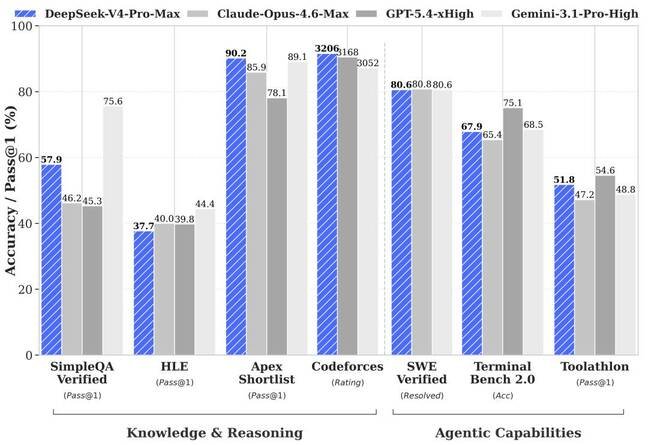
DeepSeek unveiled DeepSeek V4 on Friday, making the models available for download on Hugging Face, through the company's API, and as a web service. The release consists of two versions: a 284 billion‑parameter Flash mixture‑of‑experts model with 13 billion active parameters and a 1.6 trillion‑parameter Pro model that activates 49 billion parameters during inference. According to DeepSeek, V4‑Pro was trained on 33 trillion tokens and matches or exceeds the performance of leading open‑weight LLMs while competing with the best proprietary models from the West.

The company says the new architecture delivers substantial savings for inference providers. A hybrid attention mechanism combines Compressed Sparse Attention and Heavy Compressed Attention, which lowers the compute required to generate key‑value pairs and shrinks the memory needed for KV caches. DeepSeek reports that the KV cache footprint is 9.5 x to 13.7 x smaller than that of DeepSeek V3.2, allowing a context window of up to one million tokens without a proportional increase in memory usage.
To further reduce memory demand, DeepSeek continues its use of low‑precision data types. V4 models are trained with a mixture of FP8 and FP4 precision, applying quantization‑aware training to the MoE expert weights. FP4 effectively halves the storage required for model weights compared with FP8, a trade‑off the company says is acceptable for many workloads.
Hardware support has broadened with this release. While earlier DeepSeek models were tuned primarily for Nvidia Hopper GPUs, V4 has been validated on both Nvidia GPUs and Huawei Ascend NPUs. The paper notes that the fine‑grained expert parallel scheme works on these platforms, although it does not state that the models were trained entirely on Huawei hardware. It is possible that Nvidia GPUs handled pre‑training while Huawei accelerators were used for reinforcement learning stages.
Pricing reflects the claimed efficiency gains. The smaller Flash model is offered via the API at $0.14 per million input tokens and $0.28 per million output tokens. The larger Pro model costs $1.74 per million input tokens and $3.48 per million output tokens. DeepSeek positions these rates as a fraction of what Western vendors charge; for example, OpenAI’s GPT‑5.5 is listed at $5 per million input tokens and $30 per million output tokens.
Observers note that benchmark results should be interpreted with caution. Strong performance in controlled tests does not guarantee identical behavior in real‑world applications, and the company’s earlier models showed that training efficiency does not always translate directly to deployment advantages. Nonetheless, the combination of architectural refinements, low‑precision formats, and broader hardware compatibility signals a step toward more affordable large‑model serving.
Comments
Please log in or register to join the discussion