
Building a playback resume system for millions of users requires navigating distributed systems trade-offs between consistency, latency, and cost—far beyond simple timestamp storage.

At first glance, tracking video playback positions seems trivial—just store a user ID, video ID, and timestamp. But when millions of users press play simultaneously, switch devices mid-stream, or trigger writes every few seconds, the problem rapidly escalates.  What appears as a simple key-value store quickly becomes a distributed systems challenge involving caching strategies, conflict resolution, and deliberate CAP theorem trade-offs.
What appears as a simple key-value store quickly becomes a distributed systems challenge involving caching strategies, conflict resolution, and deliberate CAP theorem trade-offs.
Defining the Core Problem
We're designing a system that allows users to resume videos from their last position across devices—not rebuilding the entire streaming pipeline. Key constraints:
- Must handle millions of concurrent writes
- Resume latency <150ms
- Acceptable eventual consistency (1–2 seconds)
- Independent per-profile watch history
Crucially, we prioritize availability over strong consistency during network partitions. If replicas fall slightly out of sync, a user resuming 1 second earlier is preferable to system downtime. This trade-off anchors our architecture.
Data Modeling Nuances
Instead of a basic user_id, we use a composite key: (account_id, profile_id, video_id). This reflects real-world usage where household accounts have multiple profiles—each with independent progress tracking. We store:
position(in seconds)updated_at(server-generated timestamp)device_id
The updated_at field enables conflict resolution via last-write-wins logic. While clock synchronization introduces complexity, server-side timestamps mitigate drift risks.

Scaling the Firehose
Assume 10M daily users with 3M concurrently watching. With 30-minute sessions and position updates every 10 seconds, we’d face:
- 540 million writes/day
- 6,250 writes/second
Smart checkpointing reduces this load:
- Update only on >15-second position changes
- Trigger writes on pause or app backgrounding
- Apply periodic 60-second fallback checkpoints
This optimization cuts writes by 3–5x, reducing database pressure and costs.
Hybrid Architecture: Caching as a Force Multiplier
A database-only approach (e.g., DynamoDB/Cassandra) works for MVPs but fails at scale due to read latency and cost. Our solution layers Redis over the database:
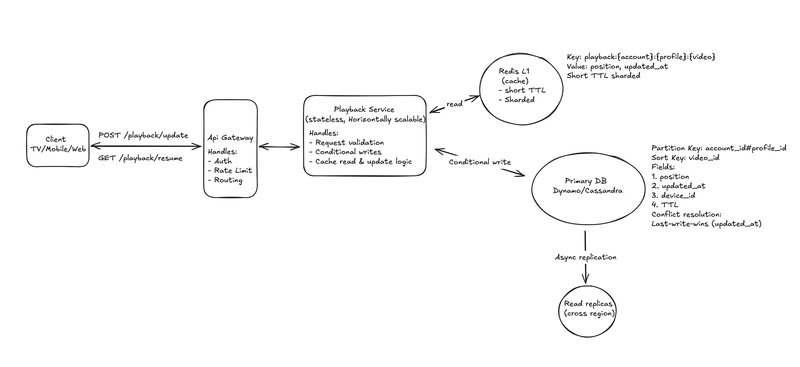
Write Flow
- Client sends
POST /playback/updatewith position data - Service performs conditional DB write:
UPDATE IF new.updated_at > existing.updated_at - Update Redis cache
- Emit analytics event (optional)
Conditional writes ensure idempotency and prevent stale overwrites. We prioritize durability: writes hit the database before Redis. If Redis crashes, the DB remains source-of-truth.
Read Flow
- Check Redis for
GET /playback/resume - On cache miss: fetch from DB → repopulate Redis
99% of reads should hit cache, keeping latency under 150ms. Brief stale reads during replication fall within our consistency tolerance.
Failure Handling and Conflict Resolution
Fallbacks
- Read timeouts: Bypass Redis and query DB directly
- Write failures: Use exponential backoff with bounded retries. Drop non-critical checkpoints rather than block playback
Multi-Device Conflicts When a TV and phone update simultaneously:
- Compare
updated_attimestamps - Latest position wins
We accept minor inconsistencies (e.g., 5-second jumps) because availability trumps perfect synchronization. UX guardrails smooth edge cases:
- Ignore regressions under 10 seconds
- Cap backward jumps beyond 5 minutes
- Prompt users: "Resume from 11:11?"
Production Hardening
Storage Lifecycle
- Set TTLs (e.g., 180 days) for inactive entries to prevent unbounded growth
Hot Partition Prevention
Partition keys (account_id#profile_id, video_id) distribute load evenly. Avoid video_id-only sharding—trending content would overload single partitions.
Capacity Planning Autoscale databases to handle write bursts. Monitor for throttling during peak hours (e.g., prime-time streaming).
Conclusion
This system exemplifies distributed design trade-offs:
- CAP: Availability over strong consistency
- Latency: Caching enables sub-150ms reads
- Cost: Checkpoint optimization reduces write amplification
- UX: Guardrails mask tolerable inconsistencies
What looks like simple state persistence is actually a carefully balanced symphony of databases, caches, and conflict resolution—proving that at scale, no timestamp is just a timestamp.

Comments
Please log in or register to join the discussion