
An excerpt from the second edition of Martin Kleppmann's seminal book on data-intensive applications, focusing on cloud vs. self-hosting tradeoffs and the ethical responsibilities of software engineers in today's data-driven world.
Designing Data-Intensive Applications: The Cloud & Doing the Right Thing
In 2016, Martin Kleppmann published 'Designing Data-Intensive Applications,' which quickly became a go-to resource for backend developers and distributed systems engineers. Nine years later, the second edition—co-authored with software engineer and investor Chris Riccomini—brings this essential work up to date for the cloud computing era.

Cloud versus Self-Hosting Tradeoffs
For any organization, one of the first questions is whether to build systems in-house or outsource them. This decision ultimately comes down to business priorities. A common rule of thumb is that core competencies and competitive advantages should be developed in-house, while non-core, routine tasks can be left to vendors.
The Spectrum of Decisions
Figure 1-2 illustrates the spectrum of possibilities for software development and deployment:

- At one extreme: Bespoke software written and run in-house
- At the other extreme: Widely-used cloud services or SaaS products accessed through APIs
- In the middle: Off-the-shelf software (open source or commercial) that you self-host
Pros & Cons of Cloud Services
Using cloud services essentially outsources system operation to the cloud provider. There are compelling arguments for and against this approach.
Arguments for cloud services:
- Time and cost savings: Cloud providers claim their services save time and money compared to setting up your own infrastructure
- Faster adoption: If you don't know how to deploy and operate a system, adopting a cloud service is often easier and quicker
- Reduced operational burden: Outsourcing basic system administration frees up your team to focus on higher-level concerns
- Specialized expertise: Cloud providers gain operational expertise from serving many customers
- Elastic scaling: Particularly valuable for variable workloads, allowing you to scale resources up or down with demand
Arguments against cloud services:
- Limited control: If a service lacks features you need, you can only request them from the vendor
- Reduced visibility: When services go down, you can only wait for recovery; diagnosing issues is difficult without internal access
- Vendor lock-in: If a service shuts down or becomes too expensive, migrating to alternatives can be costly
- Compliance concerns: Cloud providers need to be trusted to keep data secure, complicating privacy and regulatory compliance
Cloud-Native System Architecture
The rise of cloud computing has profoundly affected how data systems are implemented technically. "Cloud native" describes architectures designed to take advantage of cloud services.
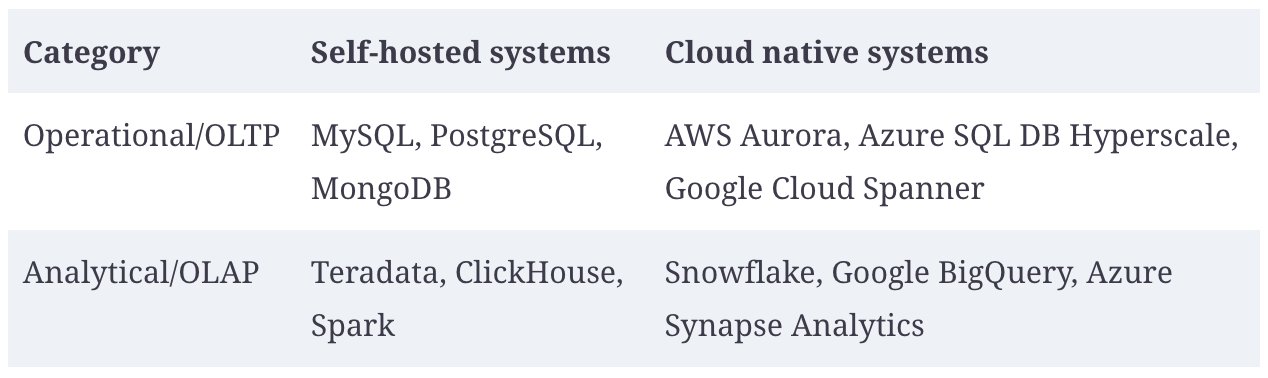
Cloud-native systems have several advantages:
- Better performance on the same hardware
- Faster recovery from failures
- Ability to quickly scale computing resources to match load
- Support for larger datasets
Layering of Cloud Services
Many self-hosted data systems have simple requirements: they run on conventional operating systems, store data as files, and communicate via standard network protocols. In contrast, cloud-native services build upon lower-level cloud services to create higher-level abstractions.
Object storage services like Amazon S3, Azure Blob Storage, and Cloudflare R2 exemplify this approach. They provide limited APIs compared to typical filesystems but hide the underlying physical machines, automatically distributing data across many machines.
Separation of Storage and Compute
In traditional computing, disk storage is treated as durable, with technologies like RAID used to tolerate individual disk failures. In the cloud, however, cloud-native systems typically treat local disks more like ephemeral caches than long-term storage.
Cloud-native systems generally avoid using virtual disks and instead build on dedicated storage services optimized for particular workloads. Object storage services are designed for long-term storage of fairly large files, while cloud databases manage smaller values in separate services and store larger data blocks in object stores.
This separation of storage and compute represents a fundamental architectural shift in cloud-native systems.
Operations in the Cloud Era
Traditionally, server-side data infrastructure was managed by database administrators (DBAs) or system administrators. More recently, the DevOps philosophy has integrated development and operations into teams with shared responsibility.
With cloud services, the role of operations has evolved:
- Setting up automation over manual processes
- Using ephemeral VMs and services rather than long-running servers
- Enabling frequent application updates
- Learning from incidents
- Preserving organizational knowledge
A bifurcation of roles has occurred: infrastructure companies specialize in providing reliable services to many customers, while customers of these services focus on choosing appropriate services, integrating them, and migrating between them.
Doing the Right Thing as a Software Engineer
In the final chapter of the book, Kleppmann and Riccomini address a fundamental aspect often overlooked in technical discussions: the ethical responsibilities of software engineers.
Ethics in Software Development
Every system is built for a purpose, and every action has both intended and unintended consequences. Software engineers have a responsibility to carefully consider these consequences and ensure decisions don't cause harm.
Many datasets are about people—their behavior, interests, and identities—and must be treated with humanity and respect. Users are humans too, and human dignity is paramount.
Predictive Analytics
Predictive analytics is both exciting and fraught with ethical dilemmas. While using data analysis to predict weather or disease spread is one thing, predicting whether a convict is likely to reoffend or whether an applicant is likely to default on a loan directly affects people's lives.
When algorithms systematically exclude people from jobs, air travel, insurance coverage, or financial services, it creates what has been called an "algorithmic prison"—a large constraint on individual freedom without proof of guilt or chance of appeal.
Bias & Discrimination
Decisions made by algorithms aren't necessarily better or worse than human decisions, but they can amplify existing biases. If input data carries systematic bias, the system will likely learn and amplify that bias in its output.
Even with anti-discrimination laws prohibiting treating people differently based on protected traits, algorithms can still discriminate indirectly through correlated features. For example, in racially segregated neighborhoods, a person's postal code or IP address becomes a strong predictor of race.
The belief that biased data can produce fair and impartial output has been satirized as "machine learning is like money laundering for bias."
Responsibility and Accountability
Automated decision-making raises questions of responsibility and accountability. When algorithms make mistakes, who is accountable?
If a self-driving car causes an accident, who is responsible? If an automated credit scoring algorithm discriminates against people of a particular race, is there any recourse? When decisions come under judicial review, can you explain how the algorithm made its decision?
People should not be able to evade responsibility by blaming an algorithm. However, predictive analytics systems are often opaque, making it difficult to understand how particular decisions were made or whether someone is being treated unfairly.
Feedback Loops
Predictive analytics can create self-reinforcing feedback loops with pernicious consequences. For example, employers using credit scores to evaluate potential hires might create a downward spiral: financial difficulties lead to lower credit scores, making it harder to find work, which worsens financial problems.
Economists found that when gas stations in Germany introduced algorithmic pricing, competition was reduced and consumer prices went up because the algorithms learned to collude.
Surveillance
The authors provocatively suggest replacing the word "data" with "surveillance" to better understand our relationship with technology:
"In our surveillance-driven organization we collect real-time surveillance streams and store them in our surveillance warehouse. Our surveillance scientists use advanced analytics and surveillance processing in order to derive new insights."
We've built the greatest mass surveillance infrastructure ever seen, with internet-connected microphones in smartphones, smart TVs, voice assistants, and even children's toys. While the benefits of digital technology are great, we now voluntarily accept a state of total surveillance by corporations rather than government agencies.
Takeaways
The second edition of "Designing Data-Intensive Applications" reflects important changes in the tech industry:
- Greater focus on the cloud: Building systems on cloud infrastructure is more common, bringing lower complexity but also accepting more risk
- AI systems: Vector databases, DataFrames, and large-scale data processing are increasingly relevant
- Local-first software: Growing demand for running models locally
- Formal methods: Getting more attention with AI-generated code
- Regulation: Engineers need to understand regulations like GDPR
The book's closing focus on "doing the right thing" as software engineers is particularly valuable. Software systems have wide-ranging societal impact, and engineers have significant influence on what gets built and how it gets built.
As the authors note, "Data and models should be our tools, not our masters." This perspective is essential as we navigate the complex ethical landscape of data-intensive applications in the cloud era.
For more insights from Martin Kleppmann on building large-scale systems, check out the Pragmatic Engineer podcast episode.
Comments
Please log in or register to join the discussion