OpenClaw's explosive growth has created confusion about optimal deployment architectures. This guide clarifies the critical CPU/GPU separation, explains why data center deployment is becoming essential, and provides practical guidance for selecting appropriate hardware.
AI agent frameworks like OpenClaw have experienced explosive growth, transforming from niche tools to essential business infrastructure. As deployments proliferate across organizations, a fundamental architectural understanding has emerged as critical for success. The rapid adoption has created a landscape where companies now deploy OpenClaw systems with the same enthusiasm that characterized Silicon Valley's Sun Ultra workstation era of the 1990s.
This guide addresses the architectural separation that many users initially overlook, explains why data center deployment is becoming essential for business-critical operations, and provides practical guidance for selecting appropriate hardware based on real-world deployment experience.
The Critical CPU/GPU Architecture Separation
The most important concept for OpenClaw deployment is understanding the fundamental architectural separation between agent orchestration and LLM inference. This divide represents two distinct computational workloads that benefit from different hardware optimizations.
Agent orchestration handles tool calling, workflow state management, API integrations, conversation history tracking, memory operations, multi-agent coordination, and business logic execution. This workload is CPU-intensive, dominated by integer operations and memory access patterns—classical computing at its finest.
LLM inference handles transformer matrix operations, attention mechanism computation, token generation, embedding calculations, and other operations. This workload is GPU-accelerated, dominated by floating-point matrix multiplications, memory capacity, and memory bandwidth.
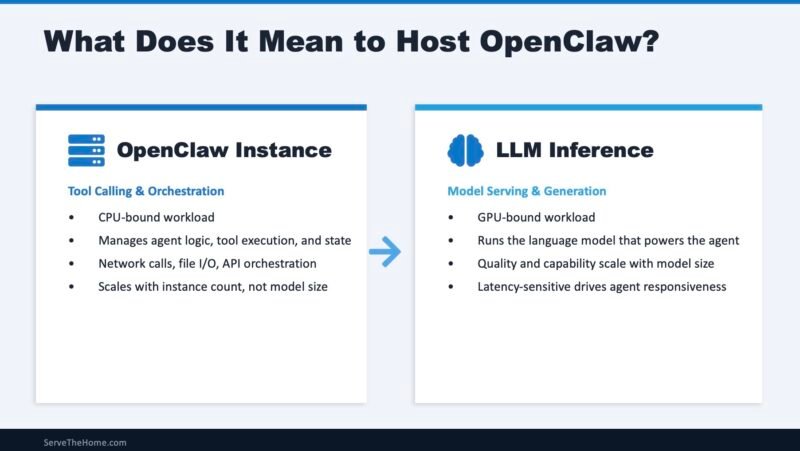
This architectural separation is fundamental to understanding OpenClaw's requirements. The "AI agent" runs on CPU cores performing traditional computing tasks, while the LLM back-end—typically GPU-accelerated—handles the majority of computational work in these workflows.
The All-in-One Deployment Misconception
Early 2026 saw widespread adoption of Apple Mac Mini systems with M4 Pro chips for OpenClaw deployment. The combination of an easy-to-install OpenClaw app, straightforward Homebrew installation, and access to iMessage (albeit with potential security concerns) drove massive demand and created shortages of Mac Mini systems.
Cloud VM and cheap VPS deployments also gained popularity, offering the benefit of public IP addresses (with similar security considerations). The Apple Mac Mini's unified memory architecture, where CPU and GPU share the same memory pool, allowed for larger LLM allocations and local model hosting, further reinforcing the perception that OpenClaw and LLM workloads could be effectively combined on a single machine.
This all-in-one deployment model, while convenient, has created confusion about the distinct computing needs of the OpenClaw AI agent (CPU) and the LLM back-end (GPU). The ease of adding API keys and running local models has bolstered the perception that these workloads are the same, when in reality they represent fundamentally different computational requirements.
The Shift to Data Center Deployment
As OpenClaw usage has exploded, companies like Anthropic have begun limiting usage on subscription plans due to overwhelming demand. This growth, combined with significant improvements in mixture-of-expert models, has driven adoption across various hardware platforms, including Apple Mac Studios, NVIDIA's GB10-based solutions, and AMD's Strix Halo systems with 128GB of LPDDR5X memory.
However, the trend toward data center deployment is accelerating for several critical reasons:
Security and Compliance: Enforcing corporate security policies becomes extremely challenging when employees bring their own hardware. Data center deployment provides centralized control over security configurations, access controls, and compliance requirements.
Reliability and Uptime: Edge networking, power delivery issues, and physical theft of small machines can all impact availability. Data centers provide redundant power, networking, and physical security measures.
Backup and Retention: Implementing consistent backup strategies and data retention policies is nearly impossible with decentralized deployments. Data centers enable centralized backup solutions and retention management.
Resource Utilization: Decentralized computing often results in massive amounts of stranded compute, storage, or memory resources. Data center deployment allows for better resource pooling and utilization.
This shift mirrors the computing evolution of the late 1990s and early 2000s, when companies moved from desktop-centric computing to data center models. Just as VMware helped make data center computing more efficient during that transition, modern infrastructure solutions are enabling efficient AI agent deployment.
Hardware Selection for Data Center Deployment
For organizations moving OpenClaw to data center environments, hardware selection requires careful consideration of both CPU and GPU requirements.
CPU Requirements for Agent Orchestration
Data center CPUs have become a primary focus as AI agents become business-critical. The CPU handles agent orchestration, workflow management, and business logic execution. Key considerations include:
- Core count for handling multiple concurrent agent sessions
- Single-threaded performance for responsive user interactions
- Memory capacity for conversation history and state management
- Network connectivity for API integrations
GPU Requirements for LLM Inference
Despite online hype about small, highly quantized models, larger models consistently deliver better results. The GPU handles the computationally intensive LLM inference workloads. Key considerations include:
- Memory capacity for larger models (128GB+ is becoming standard)
- Memory bandwidth for efficient token generation
- Power efficiency for operational costs
- Form factor for data center integration
Over the next few quarters, we're entering an era where single high-end datacenter-grade GPUs will draw more power than a common North American 15A 120V circuit can deliver. This power density requirement makes data center deployment essential for LLM workloads.
Practical Deployment Considerations
Based on extensive trial and error across various hardware configurations, several practical considerations emerge for successful OpenClaw deployment:
Network Architecture: Consider separating agent orchestration and LLM inference onto different machines or even different networks to optimize performance and security.
Memory Management: Plan for adequate memory allocation, particularly for larger models. Unified memory architectures can simplify deployment but may limit scalability.
Quantization Strategy: Balance model quality against resource requirements. While smaller quantized models use fewer resources, larger models typically provide better results for business-critical applications.
Monitoring and Observability: Implement comprehensive monitoring for both CPU and GPU workloads, as performance bottlenecks can occur in either component.
Backup Strategy: Develop backup strategies that account for both the agent configuration and any locally hosted models or embeddings.
The Future of OpenClaw Deployment
The evolution of OpenClaw deployment reflects broader trends in enterprise computing. While desk-side AI agent boxes will certainly have a place in the future, business-critical deployments are increasingly moving to data centers for the reasons outlined above.
This transition represents a maturation of the AI agent ecosystem, moving from experimental deployments to production-ready infrastructure. Organizations that understand the fundamental CPU/GPU separation and plan their deployments accordingly will be best positioned to leverage OpenClaw's capabilities while maintaining security, reliability, and efficiency.
As AI agents become more integral to business operations, the infrastructure supporting them must evolve to meet enterprise requirements. The shift to data center deployment, while requiring more initial planning and investment, provides the foundation for scalable, secure, and reliable AI agent operations that can support mission-critical business functions.
Comments
Please log in or register to join the discussion