Extend has released a free component library for building interfaces around PDFs, DOCX, XLSX, and CSV files, including bounding box citations that tie extracted data back to its source location. It targets a gap that has quietly become a headache for teams shipping LLM document pipelines: the front end.
Most of the engineering attention in document AI goes to the extraction layer. You point a model at a PDF, it returns structured JSON, and the demo looks great. Then someone has to build the screen where a human actually reviews that output, clicks a value, and sees where it came from in the original 40-page contract. That part rarely makes it into the press release, and it is usually where weeks of front-end work disappear.
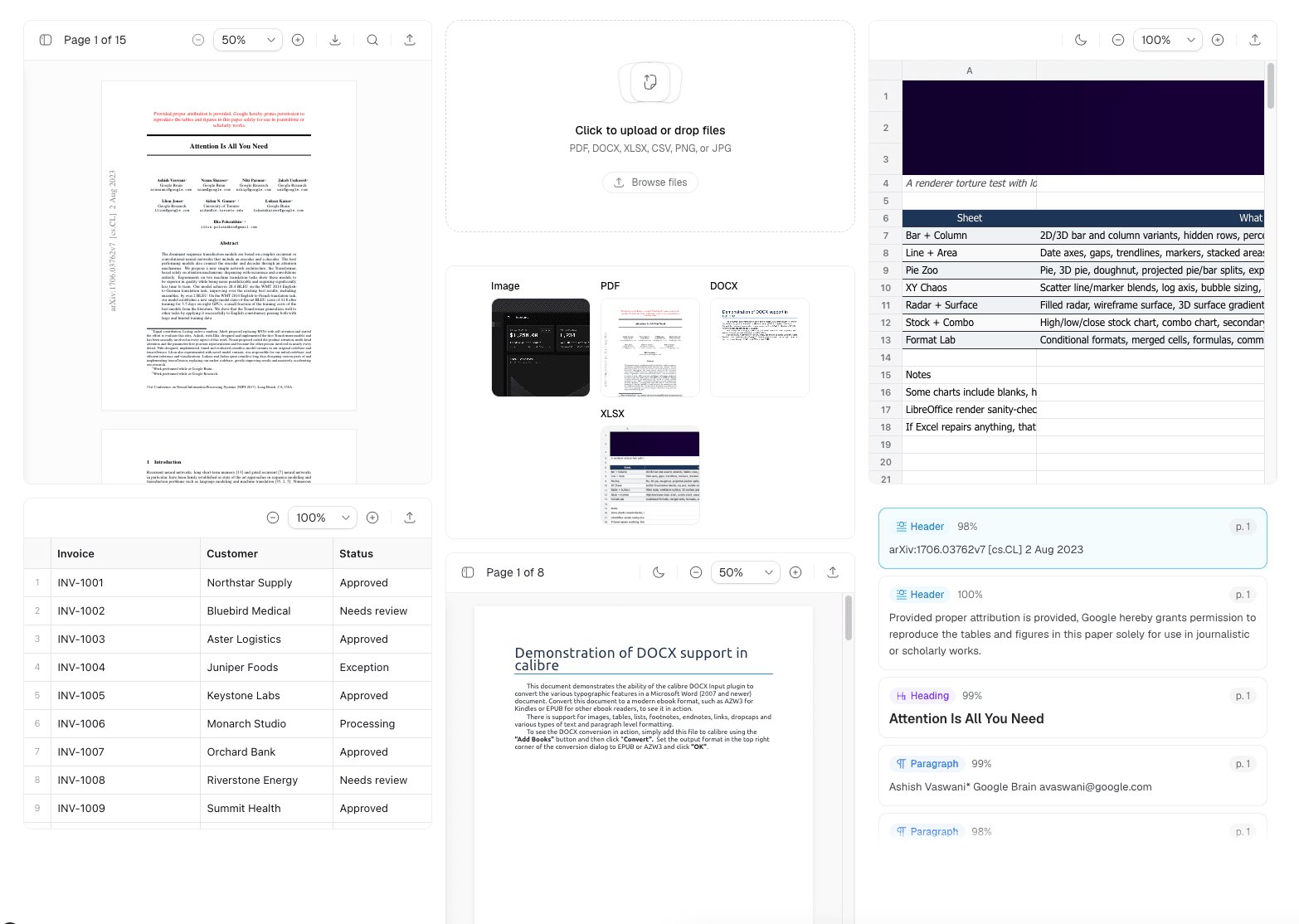
Extend UI is an open source React component library aimed squarely at that problem. It ships viewers and editors for PDF, DOCX, XLSX, and CSV, plus the connective tissue around them: file upload, a file system browser, schema building, form rendering, e-signatures, and bounding box citations. The pitch is that you drop these into user-facing flows, agent interfaces, or internal review tools instead of rebuilding a PDF viewer from scratch for the third time.
What's actually in the box
The components cluster into a few groups. There are document viewers for each supported format, so a PDF renders as a PDF and a spreadsheet renders as a grid rather than as raw text dumped into a div. There is a DOCX editor and an XLSX viewer, which matters because read-only rendering and editable rendering are very different engineering problems once you account for layout fidelity.
The more interesting pieces sit on top of the viewers. The Schema Builder lets you define the structure you want to extract: property keys, types like string, enum, object, and array of objects, nested schemas for things like an address or a list of transactions, and descriptions per field. That schema-driven approach mirrors how the underlying extraction APIs expect to be configured, so the UI and the model speak the same shape. The Form component then renders that schema as something a person can fill in or correct.
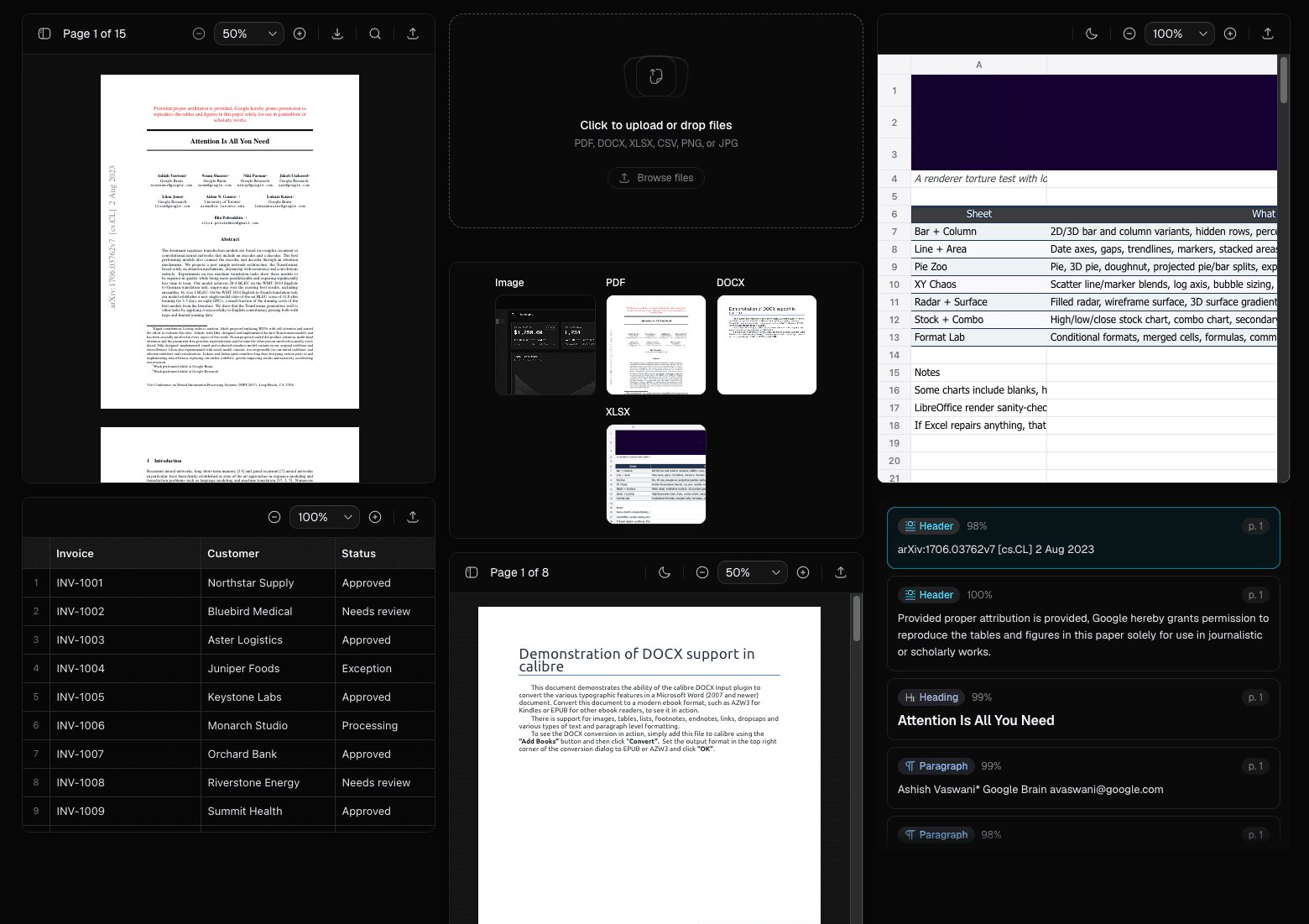
The citation piece is the real differentiator
Bounding box citations are the component most teams cannot easily buy or borrow. The idea: when an extraction model pulls a value out of a document, it also returns the coordinates of where that value lives on the page. A citation component takes those coordinates and draws a box on the rendered document, so clicking a field in your structured output jumps to and highlights the exact spot in the source.
This is what separates a trustworthy review interface from a black box. A reviewer checking 200 extracted invoice line items needs to verify questionable values fast, and scanning the whole page for each one does not scale. Tying the structured value to its pixel location turns verification into a single click. Building this yourself means reconciling PDF coordinate systems, page scaling, zoom state, and the model's output format, which is fiddly enough that a working reference implementation has real value.
Where it fits, and where it doesn't
Extend sells a document processing platform, so an open source UI kit is a reasonable on-ramp: the components work with their extraction backend but, being React and open source, are not strictly locked to it. The honest read is that the citation and schema components will be easiest to wire up if your extraction service already returns bounding boxes in a compatible format. If you are running your own pipeline, expect to write an adapter between your model output and what the components consume.
A few limitations are worth setting expectations on. A component library does not solve extraction quality, which is still the hard part of any document AI product. The viewers handle common formats, but document rendering is a long tail of edge cases: scanned PDFs, rotated pages, multi-column layouts, and spreadsheets with merged cells all tend to expose gaps in any renderer. And as with any newer open source project, you are taking on a dependency whose long-term maintenance is tied to the company's commercial priorities.
None of that undercuts the basic usefulness. For teams building human-in-the-loop review tools or agent interfaces that need to show their work against source documents, the front end has been an underserved part of the stack. Having a maintained set of React components for viewers, schema definition, and especially source citations removes a chunk of undifferentiated work. You can browse the full examples and component reference to see how the pieces compose before committing to it.
The broader pattern here is that document AI is maturing past the demo stage. The first wave of tools competed on extraction accuracy alone. The next wave has to deal with everything around the model: how people verify outputs, correct them, and trust them enough to put into production. Tooling for that review surface is a sign the field is taking the boring, necessary parts seriously.
Comments
Please log in or register to join the discussion